Github link : https://github.com/s-seo/bigcon_2020_mmmz
본 데이터 분석 프로젝트는 일반적인 분석 프로세스(데이터 수집, 전처리, 모델링, 결과 해석)으로 이뤄졌으나 가독성을 위해 프로젝트에서 내가 직접 정의한 문제와 그 해결에 초점을 맞춰 설명하겠다.
1. 문제 정의
대회에서 제시한 것은 한 문장의 주제와 두 개의 데이터 셋이다.
- NS Shop+ 판매실적 예측을 통한 편성 최적화 방안(모형) 도출
- 2019년 NS 편성 데이터(어떤 제품이 언제 얼마나 팔렸는지), 시청률 데이터
따라서 다음과 같이 문제를 구체화했다
- 2019년도의 데이터로 2020년 6월의 매출을 예측해야 한다는 time gap 문제
- COVID-19의 영향력이 크지만 관련 데이터가 주어지지 않았다는 한계
- COVID-19을 반영해 어찌어찌 예측했다 하더라도 제대로 반영했는지?
- 편성표 최적화 (최적화 개념 정의와 구체적인 방법)
전반적인 분석 프로세스는 뒷부분에서 다루고 있다.
2. 문제 해결
2-(1). Time Gap between train and test data
훈련 시점과 예측 시점의 time gap이 아무리 크다 하더라도 기본적으로 높은 예측 정확도를 얻는 것이 중요하기 때문에,
- 시간, 상품, 판매력 관련 25개의 파생 변수를 만들어내고
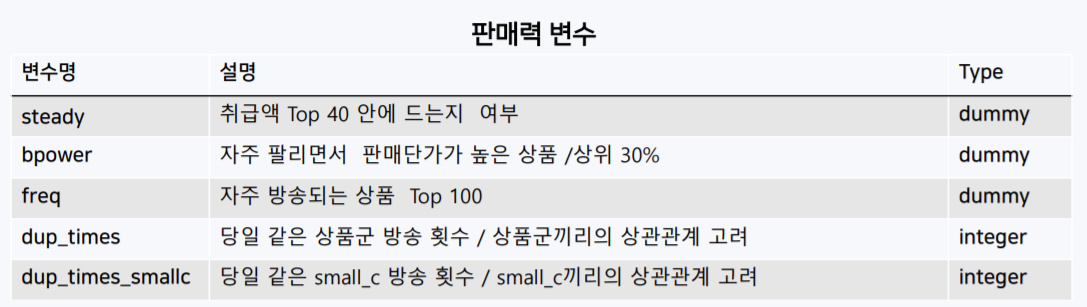
매출과 연관이 있는 검색량 데이터를 크롤링해서 변수화하고,
시계열 패턴을 반영하기 위해 lag, rolling means 변수를 생성하여 적합한 모델(2-stage LGBM)에 적용했다. Cross-vaildate을 통해 약 4~50대의 MAPE를 얻을 수 있었는데 신기하게 다른 팀들도 (심지어 대상받은 사람도) 비슷한 MAPE를 내고 있었다. 리더보드가 없었기 때문에 정확한 비교는 어렵지만 그만큼 예측이 어려운 데이터라는 것은 확실하다. CV가 아닌 실제 test에서 좋은 예측을 얻는 것이 목적이고, 6 months time gap + COVID 19 effect를 가지고 있기 때문에 모델로 설명하지 못하는 부분을 보완하고자 COVID 19 index라는 것을 계산해서 예측값에 weight을 줬다.
- COVID 19 index를 만들어내고자 19년~20년 5월까지의 온라인 쇼핑, 홈쇼핑 관련 뉴스 기사를 크롤링했다. 19년도의 각 상품군 언급 빈도 각 상품군 평균 언급 빈도(1달)를 구한뒤 20년 5월까지의 평균 언급 빈도와의 ratio를 계산했다. 또한 수집한 네이버 쇼핑 검색량 데이터를 사용해 COVID-19으로 인해 달라진 검색량(19년, 20년의 동기간 비교)을 마찬가지로 ratio로 구하여 위의 뉴스 기사 index와 평균내어 사용했다. 또한 실적 지표에 각 상품군 별 매출액이 나와있는데, 19년 1~5월과 20년 1~5월의 매출액의 ratio를 계산하여 위의 index와 비교해보니 상당히 비슷했다. 기본적으로 가장 중요한 예측 정확도를 높이는 것 외에 COVID-19 index를 계산하여 time gap 문제를 해결하려고 했다.

2-(2). COVID-19 data collection
네이버 데이터랩 쇼핑 인사이트에서 제품 검색량을 소,중,대분류(분류 코드) & 성별 & 기기별(PC,모바일) & 연령병(20대~60대 이상)로 구분지어 수집했다. 웹크롤링으로 얻은 데이터를 public한 데이터 분석에 사용할 수 없다고 판단해서 네이버에서 제공하는 API를 사용했다. (사실 크롤링과 별반 다를게 없고 오히려 더 복잡…) 코드는 github link에 가면 있고, json으로 뽑아낸 뒤 R에서 전처리, 변수화했다. API를 분류 코드마다 여러 조건(성별, 연령 등)을 부여해서 뽑아내는 방식인데 분류 코드 별 호출된 검색량은 상대적인 값으로 범위가 [0,100]이다.

또 한 번에 최대 세 개의 분류 코드만 호출할 수 있는데, 이 세 개의 분류 코드끼리는 비교가 가능하다. 모델 변수로 사용해야하기 때문에 절대적인 검색량을 얻어야하는데, 이를 위해선 모든 제품 조합, 즉 $C(N,3)$만큼의 호출을 하면 되는데 n이 적어도 몇 천개이기 때문에 계산량이 너무 비대해지는 문제가 있다. 따라서 약간의 트릭을 사용했다.
- 먼저 3개의 분류 코드(1~3번째) 조합에서 가장 높은 검색량의 분류 코드를 구한다.
- 4~6번째 분류 코드 조합에서 가장 높은 검색량의 분류 코드를 구하고 이를 N번째 코드까지 반복한다.
- 각 조합에서 선정된 분류 코드의 빈도를 구하여 가장 높은 빈도의 분류 코드를 찾고 이를 top category라고 한다.
- Top category를 기준으로 나머지 모든 조합을 구한다. 따라서 $C(N,2)$로 계산량을 줄일 수 있다.
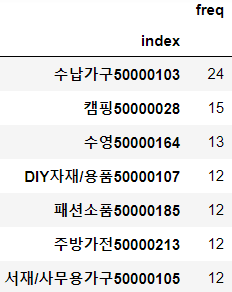
이 방식으로 절대적인 검색량을 파악할 수 있고 이를 모델에 사용했다. 검색량 데이터를 분석에 사용하기 위한 타당성을 파악하기 위해 다음의 문제를 정의히고 해결했다.
- A1. 네이버 쇼핑 검색량 데이터가 실제로 COVID-19 영향을 잘 반영하는지?
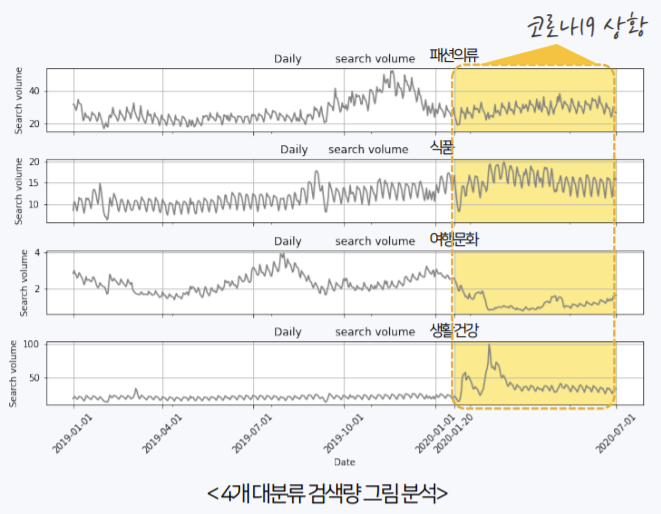
- A2. 검색량 데이터와 NS 홈쇼핑 매출액 데이터 간 연관성이 있는지?
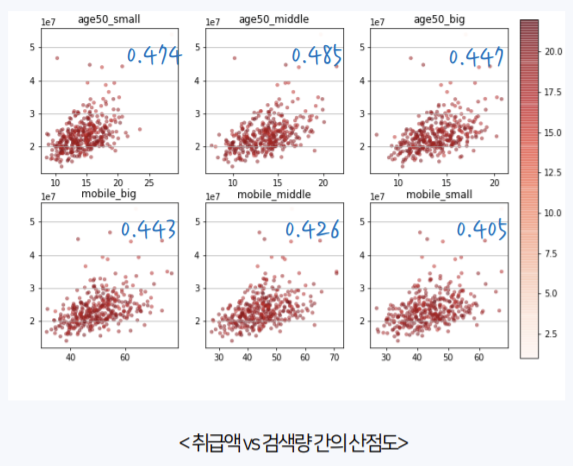
위 산점도는 같은 19년 6월의 데이터만 사용했다. 발표 당일 꽤 많은 팀이 비슷한 네이버 쇼핑 데이터를 사용했지만, 조합론 트릭을 이용해 절대적인 검색량을 계산하고, 위와 같이 타당성을 입증한 부분에서 차별점을 둘 수 있었고 이에 좋은 평가를 얻은 것 같다. 또 실제로 모델링 결과, feature importance를 계산했을 때 검색량 변수의 중요도가 어느정도 높게 나왔다.
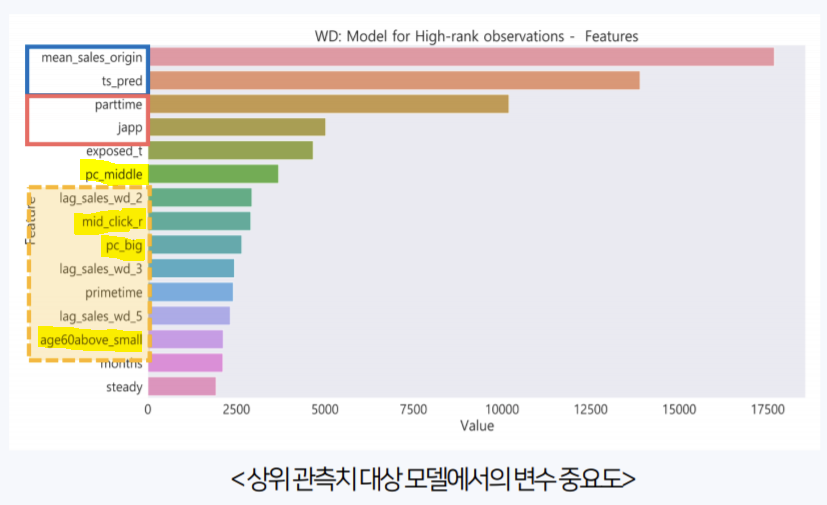
- A3. 검색량과 매출액 간 인과관계
검색량과 매출액 데이터 간 인과관계를 주장하려면 두 변인 간 상관 관계, 시간적 우위 관계, 결과를 설명할 수 있는 다른 요인의 부재가 필요한데, 검색량과 매출액은 서로 같은 시간대이고, 매출액이라는 결과를 설명할 수 있는 다른 요인이 너무나 많기 때문에 (제품 가격, 계절성 등) 둘 사이에는 단순한 양의 상관관계만 존재한다고 할 수 있다. 이 부분은 분석 당시에는 크게 고려하지 않고 당연하게 넘어갔는데, 어떤 면접관 분께서 이 문제를 집어주셨고, 생각해볼 부분이라 여겨 그 후에 따로 공부했었다. 관련된 내용은 정리해서 포스팅할 예정이다.
2-(3). COVID-19 effect test
네이버 쇼핑 데이터와 COVID-19 index 등으로 COVID-19의 영향력을 모델에 반영했다고 하지만 모델을 처음 접하거나 실제로 사용할(?) 사람들에겐 이러한 영향력이 실제로 잘 반영된건지 확인하는 검증 작업이 필수적이다. 이를 위해 counterfactual analysis를 적용했는데, counterfactual이란 만약 어떤 것이 발생하지 않았다면 어떤 현상이 일어났을 것인가를 의미한다. 인과관계를 추론하는 기법으로 impact evaluation의 한 종류고 A/B test와 비슷한 성격인데, 순수하게 예측 결과만을 가지고 인과관계를 추측한다는 점에서 다르다. 이 기법의 가장 중요한 점은 모델의 예측 정확도다. 앞서 네이버 쇼핑 데이터가 COVID-19 상황을 잘 반영함을 확인했기 때문에 다음과 같이 실험을 설계했다.

즉, COVID-19이라는 원인이 매출액이라는 결과에 어떻게 영향을 미쳤는지 파악하고자 네이버 쇼핑 데이터만을 분석에서 제외한 결과를 기존 결과와 비교했다. 이렇게 함으로써 외부 경제 상황과 같은 교란 요인을 완벽하게 배제하기도 했고 분석의 실행, 전달 면에서 용이하다는 장점이 있다. Counterfactual analysis로 다음의 결과를 얻을 수 있었다.
- COVID-19가 발생해서 NS 홈쇼핑 매출은 상승함
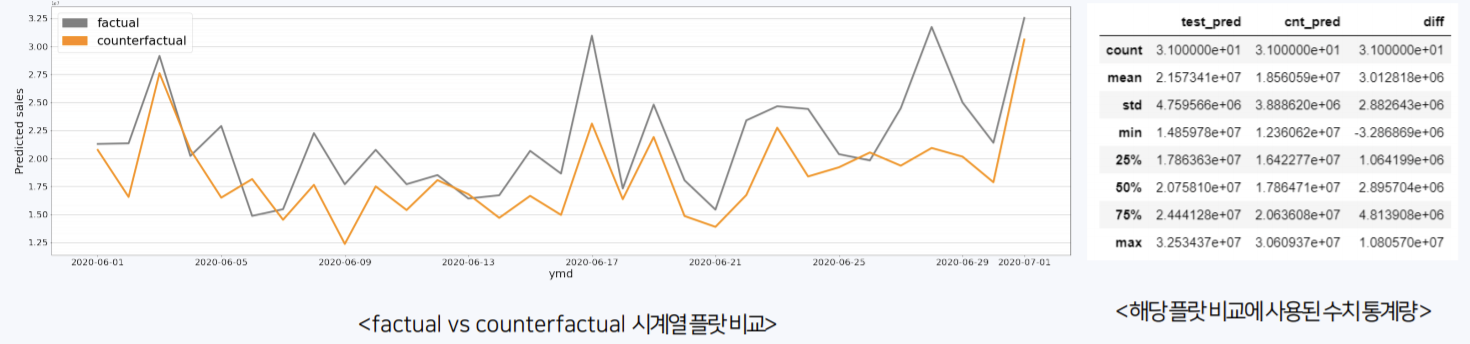
- 각 상품군이 COVID-19가 발생함으로 인해 어떤 영향을 받았는지
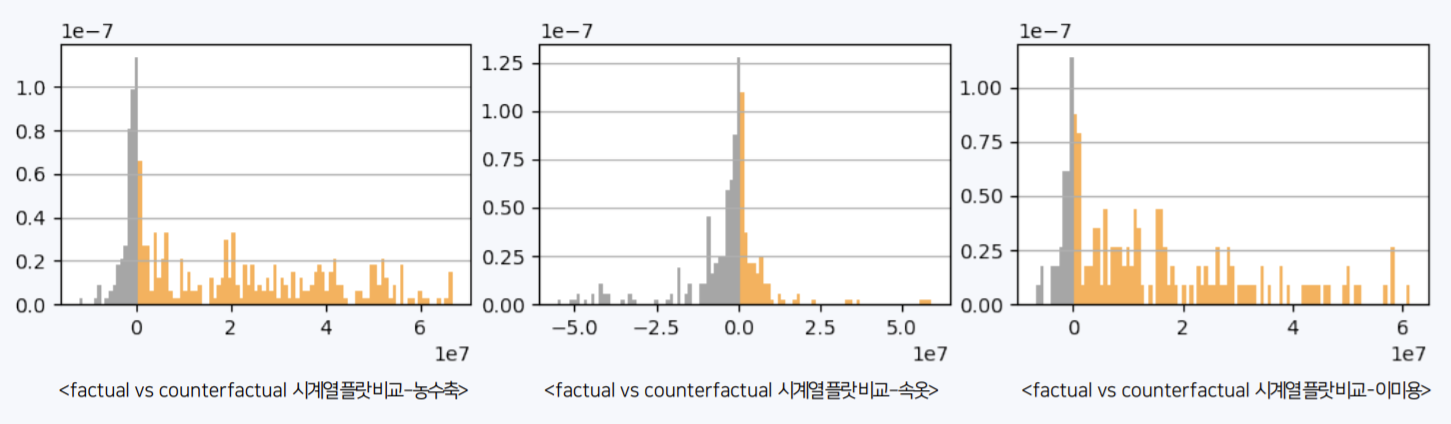
노란 부분이 클수록 COVID-19으로 인해 매출이 상승했다는 의미다.
- COVID-19가 발생해서 매출이 증가한 세부 상품을 확인할 수 있다.
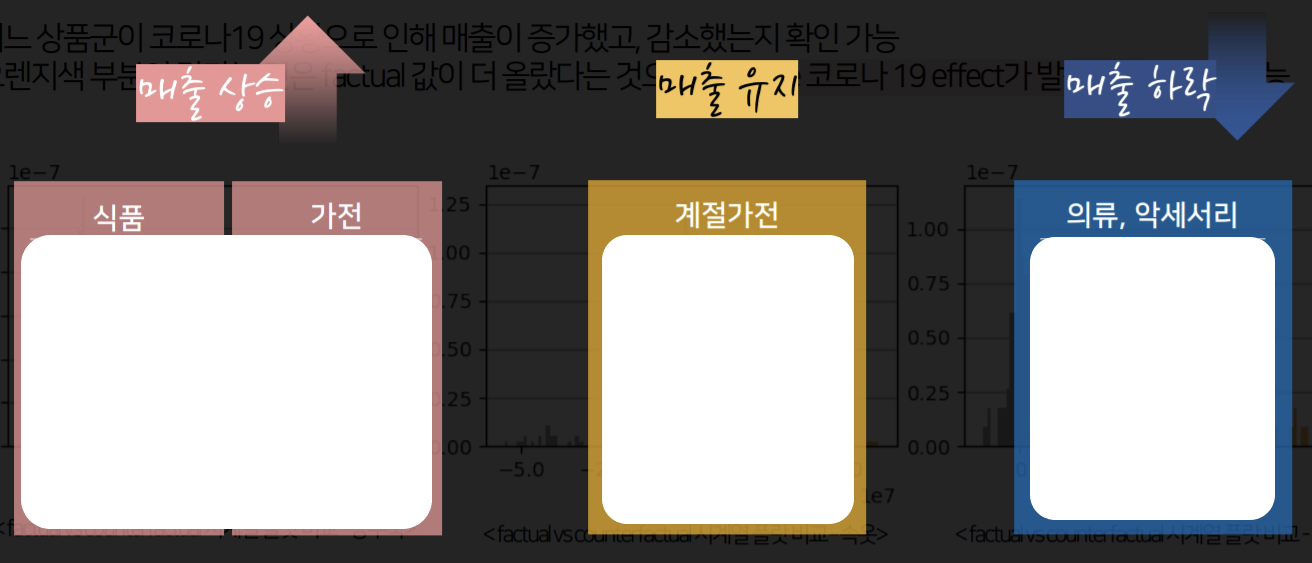
이렇게 counterfactual analysis를 사용해 COVID-19과 매출 간 인과관계를 밝히고, 어떤 상품군, 상품에서 긍정, 부정의 영향력이 나타났는지 파악함으로써 비즈니스 인사이트를 도출할 수 있었고 이 부분에서 다른 팀들과 차별점을 가졌다고 생각한다.
2-(4). Table optimization
편성표 최적화라는 주제에 대해 불만과 걱정이 많았다. 예측 모델을 사용하는 것은 맞는데 최적화라는게 무엇이며 어떻게 구현하고 해결할 수 있을까. 일련의 문제를 해결하기 위해 가장 근본적인 물음에서 시작했다.
- 동일한 시간대에 다른 상품을 배치했는데 예상 매출액이 더 높다면?
이 때 동일한 시간대란 방송 한 타임을 의미하고, 다른 상품이란 상품의 색상, 크기는 고려하지 않고 상품명, 상품군 자체가 다른 것을 의미한다. 예상 매출액은 우리 모델의 예측값을 의미한다. 기업 입장에서 생각했을 때 최적화란 곧 매출이란 금전적 부분의 optimize를 의도했다고 해석한 것이다. 이런 관점에서 다음과 같은 해결 방안이 떠오를 수 있다.
- 모든 시간대에 모든 상품의 예상 취급액을 계산하고 가장 높안 상품을 배치한다면?
결과적으로 제일 잘 팔리는 상품만 편성될 것이다. 이는 다양한 상품을 다뤄야 하는 일반적인 편성표라고 보기 어렵기 때문에 최적화라는 단어를 NS 홈쇼핑의 특징(상품 다양성, 프라임 시간대)을 반영한 수익성 최대화라고 정의했다. 또한 문제 해결에 필요한 몇가지를 가정했다. 어떤 프로세스로 편성안이 만들어지는지 알 수 없었기 때문에 팀원들과 다방면으로 리서치했고 심지어 NS 홈쇼핑 본사에도 전화했었다. (얻은건 없었다) 리서치한 결과를 바탕으로 다음과 같은 문제 상황을 가정했다.
- A1. 상품 계약 시 방영 횟수가 정해져 있다.
- A2. MD가 여러 편성안을 보고 최종 결정을 한다.
- A3. 주어진 test set의 편성안은 이미 NS 홈쇼핑의 모든 전략이 적용된 것이다.
따라서 최적화 기법을 적용해 기존 편성안의 예상 매출액보다 높은 편성안을 작성할 수 있다면 NS 홈쇼핑의 전략이 더욱 최적화 될 여지가 있는 것이다. 이러한 점을 토대로 다음과 같은 문제를 정의했다.
- 현재 NS 홈쇼핑 전략의 유효성
- 같은 상품군을 연속시켜 편성하는 것과 분산시켜 편성하는 것 중 어떤 것이 더 최적화하는지?
두번째 문제는 처음 최적화를 시도해볼 겸 임시 편성표를 작성했는데, 기존 편성안과 두드러지는 차이점이 비슷한 상품군이 연속되어 나타나는지에 있었기 때문에 이 점에 초점을 맞췄다. 문제 정의하는 것이 호수에서 반지 찾는 것과 같이 막연했지만 막상 정의하고 나면 나머지는 구체적인 해결 방법과 결과 해석 뿐이다. 최적화를 위해 헝가리안 알고리즘을 다음의 두 방식으로 사용했다.
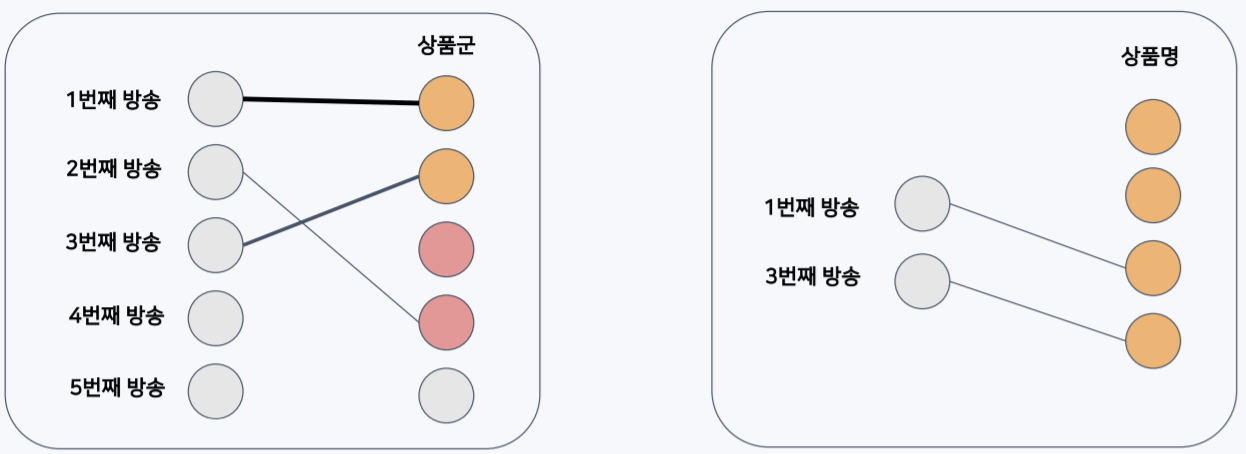
1. Direct method
가장 기본적인 방법으로 특정 방송 시간에 특정 상품을 매칭시키는 방법이다. 이 때 최적화 정의에 의해 NS 홈쇼핑의 특징을 반영하고자 매 주의 상품 리스트만을 돌렸다. 즉, 첫번째 주에 A 상품이 3번, B 상품이 1번, C 상품이 5번…이 방송되었다면 이 리스트를 헝가리안 알고리즘에 적용시켜 NS 홈쇼핑의 특징을 그대로 반영했다. 결과로 작성된 편성표는 다음과 같은 형태이다.

2. 2-level hierarchical method
Direct method와 달리 특정 방송 시간에 상품군을 먼저 매칭시키고(1-level), 매칭된 상품군 내에서 상품명을 매칭시키는(2-level) 계층적 방식이다.
이 때 NS 홈쇼핑의 특징을 반영하고자 6월 전체 편성안에서 상품군의 빈도를 확률로 변환하여 다항분포의 모수로 사용했고, 이 분포에서 매일 방송될 22개의 상품군 리스트를 샘플링했다.
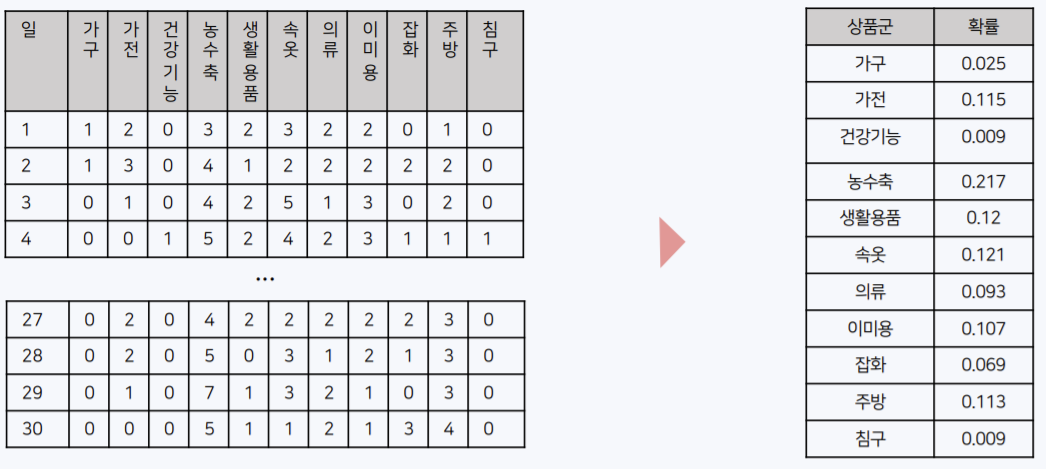
다음으로 매칭된 상품군에 속하는 상품을 매칭시켰는데, 이 때는 해당 방송 시간 기준 3일 내에 취급된 상품 중 가장 높은 예상 매출액의 상품을 매칭했다. 결과적으로 2-level을 지나면 모든 방송 시간대에 특정 상품명이 매칭된다. 아래는 작성된 편성표 예시이다.

두 방법을 사용한 이유는 결과로 얻는 편성표가 상품군 연속성 면에서 대비되는 특징을 가지기 때문이다.
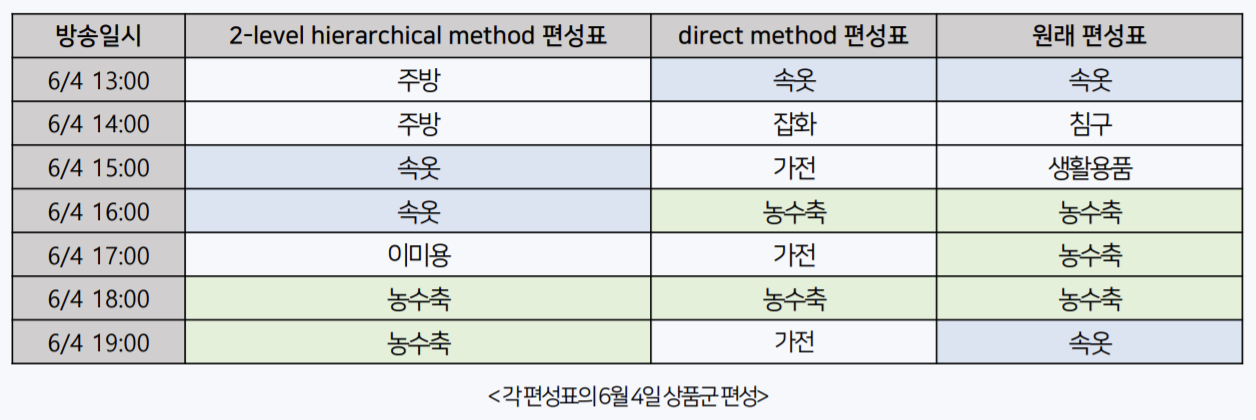
위와 같은 결과를 가지고, 최적화라는 단어의 정의 중 예상 매출액 최대라는 것에 기반하여 위에서 정의한 문제(상품군 연속 vs 분산)를 해결할 수 있다.
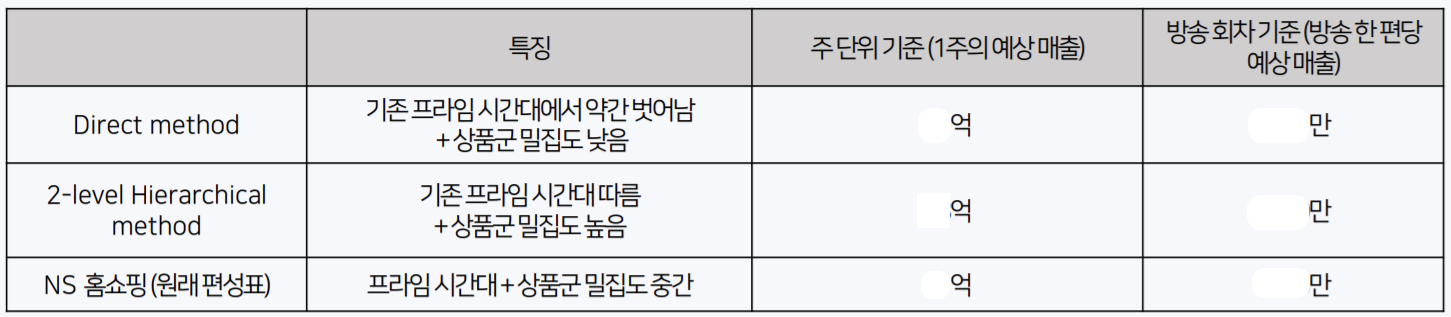
결과적으로 2-level hierarchical method를 사용해 기존 NS 홈쇼핑의 편성표보다 최대 2배의 매출액을 달성할 수 있고, 전략 면에선 상품군을 연속적으로 편성하여 기존의 프라임 시간대를 따르는 것이 더 나은 최적화를 얻을 수 있다.
3. Overall process
EDA를 통해
- within week & between week sequentiality
- 주말, 주중 구분
- NS 홈쇼핑의 제품별 프라임 시간대
- 판매량이 매우 높거나 자주 방송되는 제품
- 제품 카테고리화 (소,중,대분류)
와 관련된 feature engineering을 적용했고, 네이버 쇼핑 인사이트 검색량을 크롤링하여 각 제품 카테고리마다 검색량을 반영하고, 추가로 날씨 데이터(강수 여부, 일교차)를 크롤링하여 변수화했다. 시청률 데이터는 대체로 0에 편향되어 있어 사용하지 않았는데 어차피 테스트 시점의 시청률 데이터를 제공해주지도 않았다… 또한 시계열 패턴을 반영하고자 lag, rolling means 변수와 prophet 모델 예측값 변수를 생성했다. 전처리는 sissing value는 0으로 impute 및 label encoding을 적용했다. 모델링은 다음의 model diagram을 참고하면 된다.
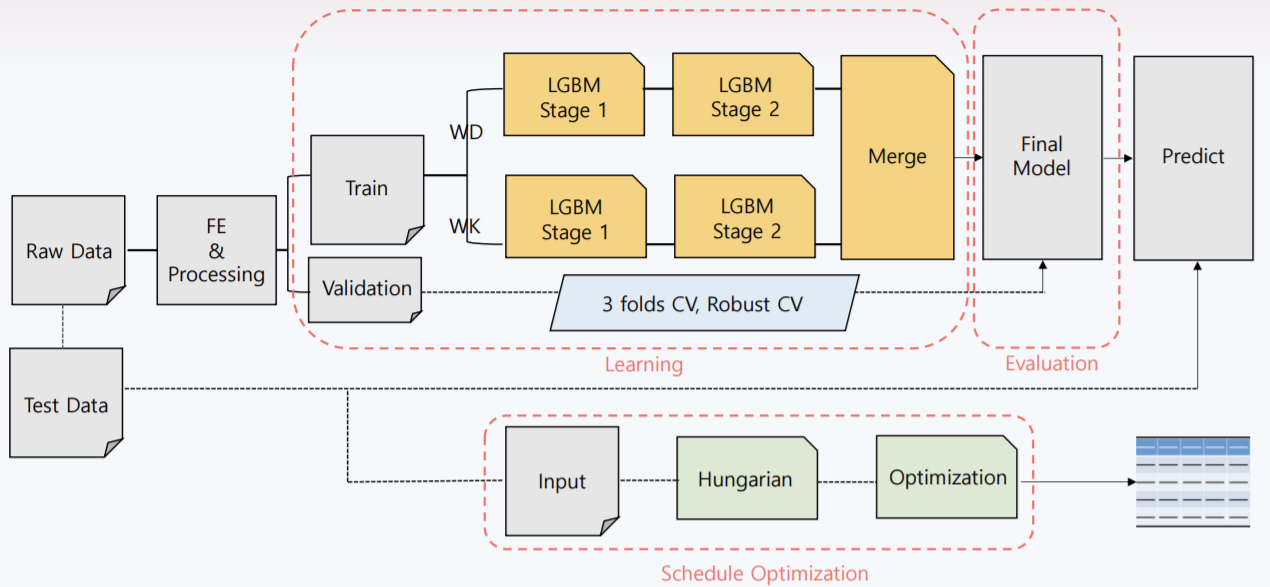
LGBM의 parmeter tuning은 bayesian optimization을 사용했다. 여기서 특이한 점은 LGBM을 두 개의 stage로 나눈 것인데 모델 훈련 시 낮은 취급액에 초점이 맞춰져 있어 큰 값의 예측 정확도가 떨어지는 것을 보완하고자 상위 취급액 데이터를 따로 훈련시켜 기존 결과와 병합시켰다. 이렇게 함으로써 약 5 정도의 MAPE를 감소시킬 수 있었다. 모델 결과에 residual analysis를 통해
- 같은 코드의 제품이어도 사이즈, 옵션에 따라 취급액 변동이 있기 때문에 이에 대한 예측 정확도가 떨어진다는 점
을 확인했고, counterfactual analysis 적용해 우리의 모델이 코로나 영향을 잘 반영하고 있음을 검증했다. 마지막으로 편성표 최적화에선 헝가리안 알고리즘을 다양한 방식으로 시도했고, 그 중
- 특정 방송에 최적화된 상품을 직접적으로 매칭
- 특정 방송에 최적화된 상품군을 먼저 매칭시키고, 해당 상품군 내에서 상품을 매칭시키는 계층적 방식
의 가장 대비되는 두가지 방식을 통해 편성표 작성에 필요한 인사이트를 얻고 최적화를 통해 예상 매출액을 최대 2배 가량 증가시킬 수 있음을 보였다.