파이썬으로 데이터를 다룰 때 가장 큰 불편한 점을 하나 꼽자면 R의 dplyr과 같은 통일된(?) 패키지가 없다는 것이다. 좀 복잡한 인덱싱, aggragation, pivot table 등을 구현하는 함수나 메서드가 같은 부모(?)에서 나오지 않았다는게 나한테는 큰 어려움이다. 매번 구글링하는 것도 귀찮고, 그냥 내가 정리해볼란다.
중구난방으로 정리할 수는 없으니, 아래의 머신러닝 워크플로우에 따라 정리해보곘다.
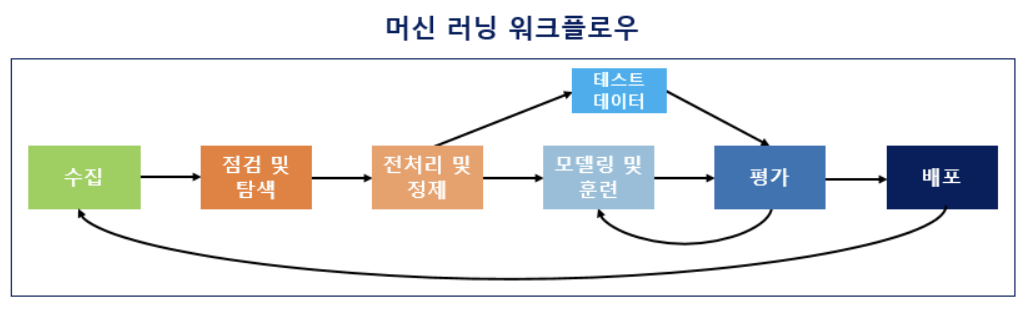 출처: https://wikidocs.net/31947
출처: https://wikidocs.net/31947
패키지 관련 (Python Packages)
대부분의 패키지는 다른 여러 패키지를 상속받아 뼈대로 쓴다. 이 때 부모 클래스의 어떤 시기(버전)을 쓰는지가 패키지마다 달라서 문제가 되곤한다. 특히 numpy에서 이런 에러가 자주 뜨는데, 아래 두 개의 명령문으로 커버할 수 있다.
$ pip install --user numpy --upgrade # numpy를 최신 버전으로 업데이트할 때
$ pip install --user numpy==1.16.5 # 구버전의 numpy가 필요할 때
Downgrade든 upgrade든 끝나면 np.__version__으로 numpy 버전을 확인해주자.
수집 (Data Load)
점검 및 탐색 (Exploratory Data Analysis)
- Pandas Profiling
pr = df.profile_report() pr.to_file('./pr_report.html') - Data Type
type(data) - Select Columns with a Prefix(Suffix) using Pandas filter
df.filter(regex = '^start', axis = 1) # prefix df.filter(regex = 'end$', axis = 1) # suffix df.loc[:, df.columns.str.startswith('start')] df.loc[:, df.columns.str.endswith('end')] - Dataframe Sampling
df.sample(n, random_state, replace, weights = 'col_name', # 특정 열의 값을 가중치로 매겨 sampling함 axis = 1) # or 'column', 열 단위로 sampling하는 것인데 잘 안함... axis = 0 은 index 기준으로 default 값이다. df.fraction(frac, random_state, replace, weights = 'col_name', axis = 1) df['col1'].sample(n) # Series 반환 - Unique
df1.col1.unique() set(df1.col1.unique()) - set(df2.col1.unique()) # 고유값의 차집합 - Sort
# 데이터프레임 정렬 df.sort_values(by = None, axis = 0, # axis = 1 이면 열을 정렬하느건데 보통 알파벳 순으로 정렬한다 ascending = True, inplace = False, kind = 'quicksort', na_position = 'last') # 결측값을 'first'에 또는 'last'에 위치할 것인지 # 튜플 정렬 sorted(tuple, key = lambda key1: key1[0], # 튜플 원소의 몇 번째 값으로 정렬할 것인지 reverse = True) # 리스트 정렬 sorted(list, reverse = True) list.sort(reverse = True) - Round
round(x, n) import math math.ceil(x) math.floor(x) # -inf로 향하는 내림 math.trunc(x) # 0으로 향하는 내림 - Correlation
df.corr(method = 'pearson)
전처리 및 정제 (Data Preprocessing)
- Convert column type
dat['col1'] = dat.col1.astype('str') dat.col1 = dat.col1.astype('str) - Reshape
pd.melt(data, # id_vars 에 해당하는 열만 남기고 나머지 열은 varaible로 나머지 열의 값은 value로 melting id_vars, # 어떤 열(들)을 남길 것인지 var_name, # variable의 이름을 지정해줌 value_name) # value의 이름을 지정해줌 pd.pivot_table(data, # 긴 테이블을 옆으로 늘릴 때 주로 씀 index, # 어떤 열(들)을 남길 것인지 columns, # 어떤 열(들)을 옆으로 늘릴 것인지 value, # 어떤 열을 늘린 열들의 값으로 할 것인지 aggfunc = np.sum, np.mean, # 중복되는 값을 어떻게 처리할 것인지 margins = True, False) # 행, 열 합계 제시할지 # `melt()`는 id_vars가 column으로 들어가고, `pivot_table()`은 동일한 개념인 index가 index 그 자체가 된다. # 범주형 변수들의 도수분포표 구하는 함수 pd.crosstab(index, # 행 쪽으로 grouping variable, multi-index: [id1, id2] columns, # 열 쪽으로 grouping할 variable, multi-level: [col1, col2] rownames, # 행 이름 부여 colnames, # 열 이름 부여 margins = True, # 행 합, 열 합 추가 normalize = True) # count가 아닌 proportion을 계산 # 옆으로 뚱뚱한 테이블을 아래로 길게 쌓는 것. 대신 index 차원으로 작업함 dat.stack(level = -1, # 기본적으로 df의 row index와 col index의 level은 1개인 경우가 많다. 그래서 stack을 하게되면 multi (row) index가 됨 dropna = True) # df를 stack할 때 결측값 제거 # stack 된 df가 있으면 dat_stacked['ind1']['ind1_1'] # 아래로 기다란 테이블을 옆으로 뚱뚱하게 만드는 것 dat.unstack(level = -1, # multi (row) index가 있을 때 가장 바깥쪽이 가장 낮은 level에 해당한다. 중간은 0 level, 가장 바깥쪽은 1 level에 대응되는 것 같은데... fill_value = None) dat_unstck_df = dat_unstacked.reset_index() # unstack하면 series가 반환되는데 이를 다시 df로 바꿔준다. dat_unstck_df.rename(columns = {'level_0':'col1', 'level_1':'col2'}, inplace = True) # df로 바꿔도 여전히 row, col index는 남아있기 때문에 이름을 지정해야한다. - Row names to columns
df.index.name = 'name_I_want' df.reset_index(inplace=True) # or df.rename_axis("name_I_want").reset_index() - Matching
pd.concat([df1, df2], ignore_index = True, # axis=0인 경우 그냥 붙이면 각 df의 행 인덱스까지 가져온다는 문제를 방지 axis = 1, # 열 기준으로 붙임. axis = 0은 행 기준이고 default 값임 join = 'inner') # 교집합만을 붙이는 것. default는 outer다 sr1 = pd.Series(['cont1', 'cont2', 'cont3'], name = 'cont', # series가 df에 붙을 때 열 이름 지정 index = [3, 4, 5]) # 매칭시키려는 인덱스도 정의할 수 있음 pd.concat([df1, sr1], axis = 1) # 열 기준으로 시리즈를 데이터프레임에 붙임당연히 series끼리도 붙일 수 있다. 열방향으로 concat하면 데이터프레임이, 행방향으로 하면 시리즈 객체가 반환된다.
pd.merge(df_left, df_right, how = 'inner', # outer, left, right on = None, # 공통 열이름을 기준으로 inner join함. left_on = None, right_on = None) JSON to pandas dataframe
JSON은 JavaScript Object Notation의 약자인데, JavaScript의 객체 형식을 기반으로 구조화된 데이터를 표현하는 인코딩 기법이다. 일종의 파일 형식으로 알고 있어도 무방하다. 데이터를 저장하는 방식의 단순성, 구조성(?)이 좋아 서버와 웹 응용 프로그램 간 데이터 공유에 많이 사용된다. JSON은 여러 목록과 그에 대응하는 dictionary의 조합으로 볼 수 있다. 그래서 JSON 파일에서 데이터를 추출하고 이를 Pandas dataframe으로 저장하는 것이 쉽다.
import json from pandas import json_normalize data = ''' { "Results": [ { "id": "1", "Name": "Jay" }, { "id": "2", "Name": "Mark" }, { "id": "3", "Name": "Jack" } ], "status": ["ok"] } ''' info = json.loads(data) df1 = json_normalize(info['Results']) df2 = pd.read_json(data, orient ='index')- Dataframe rename
df.columns = ['col1', 'col2'] df.rename(columns = {'old_col' : 'new_col'}, inplace = True) df.index = ['row1', 'row2'] df.rename(index = {'old_row' : 'new_row'}, inplace = True) - Label encoding
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() le.fit(df.col) le.classes_ # 인코딩 확인 df.col = le.transform(df.col) le.inverse_transform(df.col) # 역 인코딩 확인 - Min, max index
np.min(x) # 최솟값 np.argmin(x) # 최솟값의 인덱스 np.max(x) np.argmax(x) - Numpy where (ifelse in R)
np.where(X > 10) # 인덱스 출력 x[np.where(x > 10)] # 인덱싱 np.where(x > 10, 1, 0) # array 반환 - Iterating over rows, columns in dataframe
for i, j in df.iterrows(): print(i, j) # 각각 row index, row value를 key-value pair 형태로 반환 for i, j in df.iteritems(): print(i, j) # 각각 feature name, feature value를 key-value pair 형태로 반환 - Appending df in a for loop
appended_data = [] for infile in glob.glob("*.xlsx"): data = pandas.read_excel(infile) # store DataFrame in list appended_data.append(data) # see pd.concat documentation for more info appended_data = pd.concat(appended_data) # write DataFrame to an excel sheet appended_data.to_excel('appended.xlsx') - Transpose
arr.T np.transpose(arr, (2, 1, 0)) # 3차원 이상 자료에 대해서 shape(2, 3, 4) => shape(4, 3, 2)로 바꿀 수 있음 np.swapaxes(arr, 0, 1) # 2차원 자료에 대해선 0, 1, 3차원의 경우 0, 2로 하면 처음과 끝의 shape이 바뀜 - Inner product
np.dot(arr1, arr2)
모델링 및 훈련 (Modelling)
- OLS formula
from statsmodels.formula.api import ols all_cols = '+'.join(df.columns) # y가 있는지 확인 my_formula = 'y~' + all_cols # R에서는 'y~.'으로 간단하게 되는데..불편하네 ols(my_formula, data = df) - VIF
from statsmodels.stats.outliers_influence import variance_inflation_factor model = ols(formula, data) res = model.fit() # res.summary() pd.DataFrame({'Features': column, 'VIF': variance_inflation_factor(model.exog, i)} for i, column in enumerate(model.exog_names) if column != 'Intercept')
평가 (Evaluation)
배포 (Export)
전처리한 데이터나 오래 걸려 얻은 모델을 밖으로 빼내어 저장할 수 있다. 매번 코드를 다시 처음부터 돌리는건 비효율적이니 이 방법을 습관화해야 한다.
- list to file
import pickle with open('./dat_pkl.ob', 'wb') as fp: pickle.dump(dat, fp) with open ('./dat_pkl.ob', 'rb') as fp: dat = pickle.load(fp) - JSON export
import json with open("json1.json", "w") as json_tmp: # json1.json 이름의 파일을 쓰기 모드("w")로 열고 이걸 json_tmp로 객체화한 뒤, json.dump(data, json_tmp) # json.dump로 직렬화(?)해서 내보내려는 data를 직렬화된 데이터가 쓰여질 파일 json_tmp에 쓰기를 해줌