Github link : https://github.com/s-seo/SNU-GAN-project
1. 연구 배경
- 해외 주요 국가에서는 시각 지능 분야에서 인공지능 (AI, Artificial Intelligence) 기술 개발을 위한 기계학습 데이터 구축 등 인프라를 확보하여 개방함 (Kaggle, Open images dataset V4, ISIC, TCIA, NIH, etc.)
- 국내 의료 데이터 인공지능기술의 활성화를 위해서는 다양한 패턴의 고품질 이미지 데이터 확보가 중요함. 의료 데이터 고유의 특성을 가진 연구에 유효한 데이터의 확보가 필요하지만, 의료데이터에는 개인정보가 내포되어 있기 때문에 빅데이터 연구 및 활용을 위한 데이터 배포에 어려움이 있음
각 병원마다 전문 분야에 따라 보유하고 있는 이미지 데이터에 불균형이 존재하기 때문에, 다양한 분야에서의 연구 실용성 및 접근성에 데이터 부족으로 인한 어려움이 있음
- 국내 인공지능 기술의 활성화를 위해서는 무엇보다 기계 학습에 활용할 다양한 패턴의 고품질 이미지 데이터 확보가 중요함
- 기존 공개된 이미지 데이터베이스에서 다루지 않은 의료 특화 서비스 및 데이터 개방을 위한 고유의 특성을 가진 이미지 데이터의 생성 및 구축이 필요함
- 따라서, 최신 딥러닝 기술 중 하나인 GAN(Generative Adversarial Networks)를 활용하여, 이를 통해 접근하기 힘든 의료 이미지 데이터를 생성해 교육·연구 배포용 데이터를 만들어 사용하는 것이 가능한지, 임의의 테스트를 통해 결과를 확인하는 것이 본 연구의 최종 목적임
2. 연구 방향
- 딥러닝 기술로서 Ian Goodfellow 등 (2014)에서 처음 제안된 이래, 가장 주목받고 있는 최신 기술 중 하나인 GAN(Generative Adversarial Networks)를 활용하여, 연구/학습용 이미지를 생성할 수 있는지 확인함
- 현재 연구되어 있는GAN의 성능 및 장/단점을 살펴보고, 현재 사용할 수 있는 리소스(CPU, GPU)를 최대한 활용하는 GAN을 구현하여, 가짜(Fake)이미지를 생성 및 비교함
- GAN을 구현하는 중 발견한 점들을 논의하고, GAN을 통해 생성한 가짜이미지를 활용하여 CNN을 설계 및 성능을 확인함
3. 연구 목표
- 실제 해당 GAN을 구현하는 연구를 통해, GAN을 통해 만들어진 가짜이미지가 교육/연구용 배포 데이터로 활용 가능성이 있는 지 검토 및 논의함
- 또한, GAN을 통해 만들어진 가짜 이미지의 성능을 평가하기 위해 실제 이미지 데이터로만 만들어진 CNN 모델에 GAN으로 생성한 이미지를 추가한 CNN모델의 성능이 좋아지는지 판단하여 가짜이미지가 배포용 의료데이터로 활용될 가능성이 있는지 검토함
4. 연구 과정
4.1 이미지 수집 및 전처리
색상을 포함한 이미지 중 ISIC에서 취득한 피부이미지를 처리하기로 선택함
- (1) 처음 GAN 학습은 전처리과정을 거치지 않은 23,905장으로 작업함 (~약 50Gb)
- (2) 전처리 후 (스티커 최소 · 중복 데이터 제거 후 23,345 장)

4.2 GAN
2014년 Ian J. Goodfellow가 발표한 GAN은 지도학습중심의 딥러닝 패러다임을 비지도 학습으로 바꿈. 이 Network는 ‘생성자(Generator)’와 ‘감별자(Discriminator)’로 불리는 두 모델로 이루어져 있으며, 생성자는 진짜이미지와 가능한 가까운 가짜이미지를 생성하고, 감별자는 진짜이미지와 가짜이미지를 학습하는 방식으로 서로를 대치하며 학습되는 방식임
분석 세팅
- 본 연구에서는 사용하는 피부이미지는 칼라(3채널)이기 때문에, 이 기존 선형 레이어 network 구조를 사용하지 못함. 따라서, convolution 레이어로 전환하여 학습을 진행함
- 원본 피부이미지를 32x32로 전환시킨 후, GAN를 훈련하고 생성기에서 만들어진 가짜이미지를 출력함 [전처리가 끝난 이미지(23,345장)로 진행함.]
모델 요약
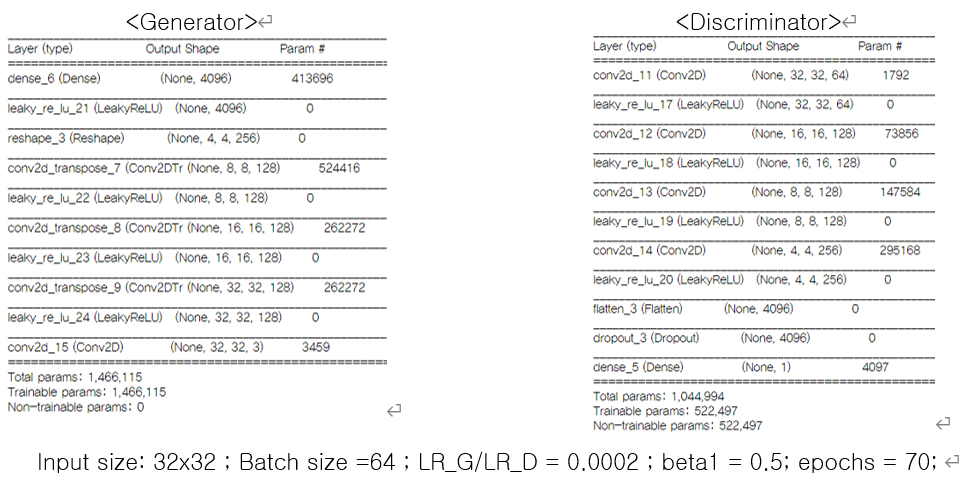
장단점
- 이 network는 코딩이 단순하여 복잡하지 않아 GAN에 대한 원리와 코드를 익히는 데 도움이 됨. 또한, 모델 자체에서 많은 연산이 요구하지 않아서, 훈련 시간이 비교적 짧고 CPU연산이 가능함
- 실제 원본 피부이미지를 32X32로 줄이기 때문에 이미 정보가 손실되고, 다시 이 이미지를 사용하여 GAN을 학습하기 때문에, 노이즈가 증가하고 화질 또한 제한 적임.
- MNIST와 같이 비교적 단순한 이미지(1 채널 및 저해상도(low resolution))를 사용하면 괜찮은 가짜 이미지를 생성한다고 알려져 있으나, 복잡하거나 고해상도의 이미지에 대해서는 좋은 결과를 얻지 못하는 것으로 알려져 있음
- 학습 파라미터(batch size, learning rate, input image size,etc.)가 달라지면, 그에 따라 모델에 안정성이 현저하게 떨어져, 현재에는 이 network는 GAN의 기본적인 개념을 학습하는 데에만 많이 사용됨
결과
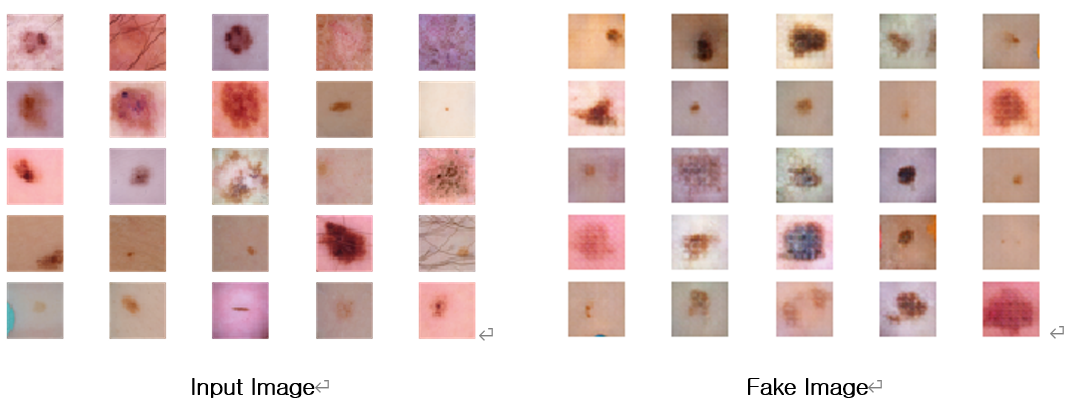
실제로 피부이미지를 사용하여 가짜이미지를 출력해 본 결과임. 아무것도 없었던 노이즈에서 점과 비슷한 특징들을 가진 그림을 그릴 수 있다는 것을 확인함. 해상도의 문제점과 이미지의 품질을 증가시키기 위해 다른 GAN모델을 시도하기로 함
4.3 Deep Convolutional GAN (DCGAN)
GAN의 일반적인 응용 형태 중 하나로, 심층 합성곱 생성적 신경망 (Deep Convolution Generative Adversarial Network, DCGAN)이라고 함. 학습 시 안정성이 떨어지는 기존 GAN의 단점을 보완하여, 대부분의 상황에서 안정적인 학습이 가능한 GAN 의 구조를 찾아낸 것이 DCGAN임.
모델 요약
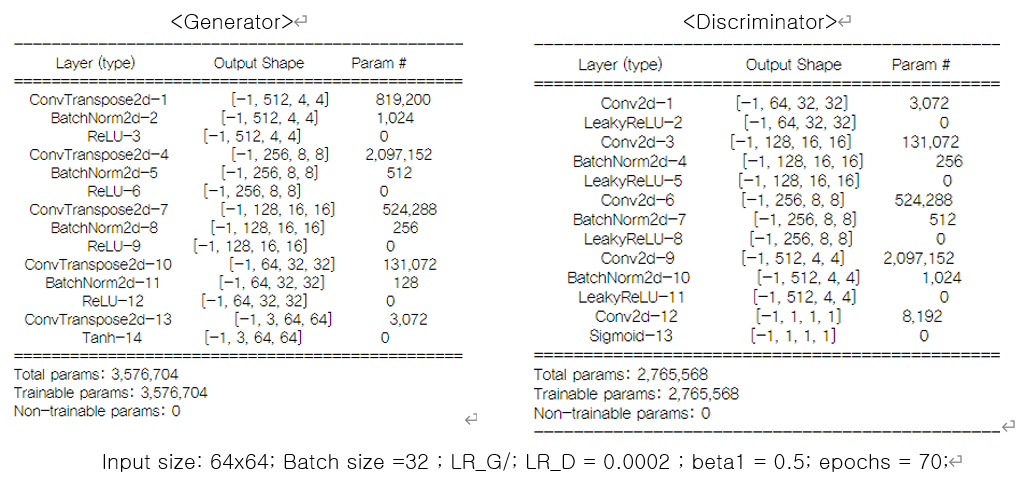
pros and cons
- 기본 GAN보다 Network의 안정성 및 해상도(32x32 -> 64x64)가 향상됨
- 기본 GAN보다 훈련시간이 길지만, 해당 GAN에서도 CPU연산이 가능함 (GPU 사용시 시간이 1/3으로 줄어듦)
- 2015년 처음 이슈가 되었을 때에, 최초로 안정적인 고화질 이미지를 생성시킬 수 있었다고 함. 하지만, 64x64 이상의 해상도를 생성하는 network로 구현하여 시도하는 경우, 모델의 안정성이 현저히 떨어진다고 알려져 있음
결과
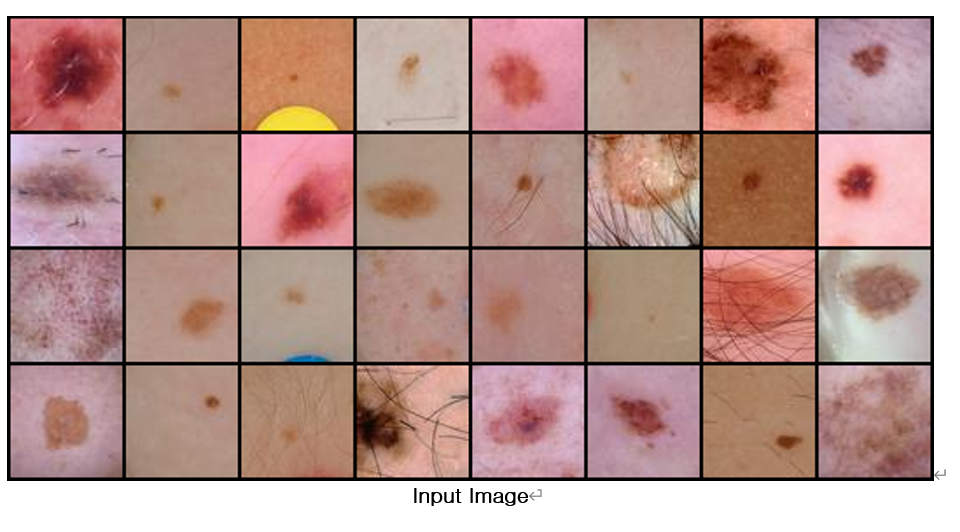
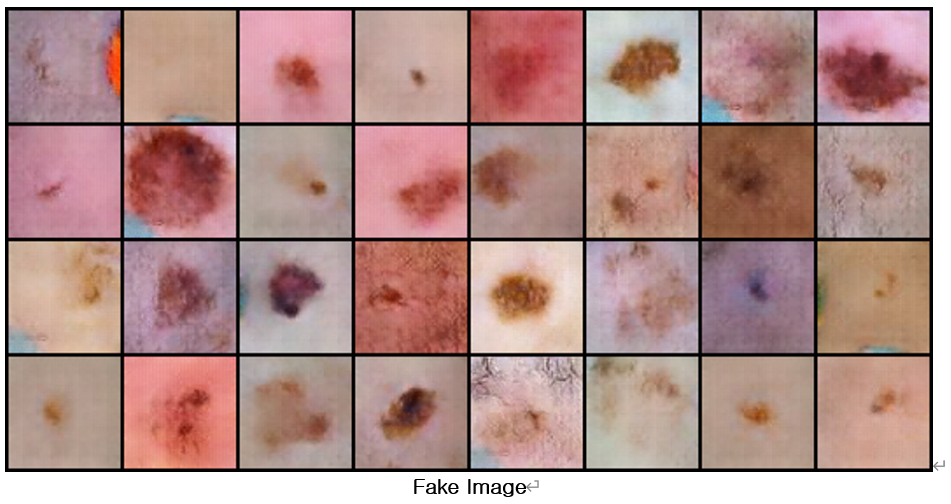
전처리 과정을 거친 이미지를 이용하여 다시 network를 구현 한 결과에서는 생성된 가짜이미지에서 스티커 등 필요 없는 노이즈가 많이 감소한 것을 확인 할 수 있었음
4.4 BigGAN
BigGAN은 ICLR 2019에 큰 이슈가 되었던 연구로, Scalability, Robustness, stability의 3가지 측면에서 큰 발전 보여주었음; 기존에 가짜이미지의 해상도가 64X64 ~ 128x128의 한계를 가지고 있었지만, 이 Network를 통해 해상도 증가(128x128 ~ 512x512) 및 향상된 질의 이미지 생성이 가능함을 보여줌 (BigGAN의 연구진은 모델 파라미터의 양을 늘리고, 큰 batch size 및 아키텍처에 변화를 주어 이러한 성과를 얻어냈음)
연구 세팅
- 해상도를 향상시키지 위해, BigGAN을 구현하고 전처리 후 피부이미지를 넣어 학습을 시작함
- 이 network에서는 melanoma와 nevus의 클래스를 나누고, 각각에 클래스에 맞게 가짜이미지를 생성함
- 이 network는 막대한 computing power가 들어가는 것으로 알려져 있음. 따라서, 현재 사용 가능한 리소스를 최대로 사용하면서 구동이 가능하도록 파라미터 찾아 맞추고 학습을 시작함
pros and cons
- 고해상도의 이미지 생성이 가능함 (high-resolution)
- 기존 GAN 아키텍처에 ResNet을 사용하여 Network가 조금 더 깊어지지만 보다 안정적이고 원본이미지에 가까운 이미지 생성이 가능한 것으로 알려져 있음 (High Fidelity)
- 이 Network를 사용하여 고해상도의 결과이미지를 얻기 위해서는 높은 사양의 GPU가 요구됨. (실제 이 network의 성능 향상을 이루어 준 특징 중 하나가 큰 batch size인데, 현재 GPU 2080ti 을 이용하고도 batch 사이즈를 16까지 밖에 구현하지 못함) 따라서, BigGAN연구진이 제시한 모델에서 이미지를 완벽하게 생성해 내기 위해서는 batch size(256)을 호환할 만한 시스템이 필요함
결과
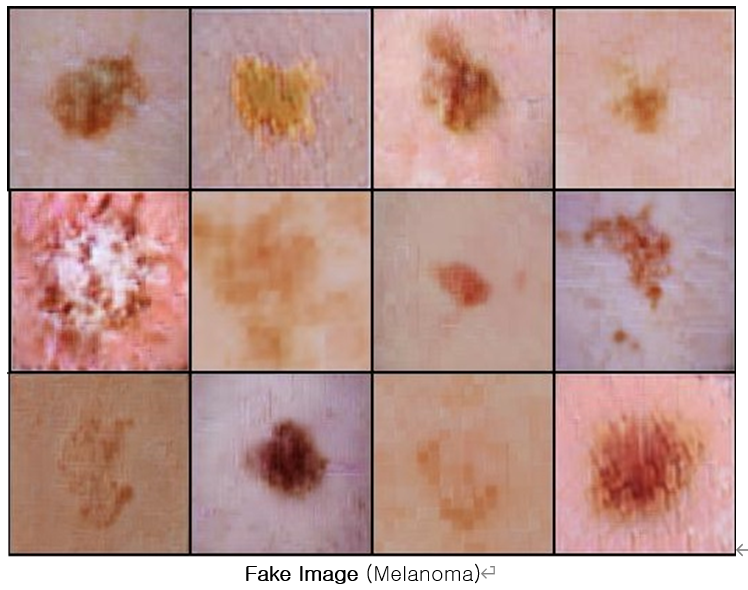
- 보유하고 있는 리소스(GPU 2080ti)에서 최대 모델링이 가능한 resolution(128*128)을 백만 번의 학습 (총 12일)을 통해 얻어진 결과임
- 간단한 GAN에서 생성된 가짜이미지들 보다 피부를 표현하는 디테일이 강조되어 보이나, 실제 원본데이터와의 차이는 육안으로도 존재함
- 해당 Network를 백만 번까지 학습해보았지만, 실제적으로 많은 학습이 모델에 성능을 늘리지는 못 하였음. 또한, 학습이 길어질수록 비슷해 보이는 가짜이미지를 생성하는 양상을 보여줌
- BigGAN연구진이 강조했던 Network의 특징 중 하나인 batch size에 변경이 현재 컴퓨터로는 구현이 불가능해 더 좋은 결과를 얻을 수 없었다고 봄
4.5 CNN
CNN (Convolutional Neural Network)은 GAN의 감별자와 같은 원리이지만, 여기서는 GAN을 통해 생성된 의료 이미지가 추후 의료 영역에서 활용될 수 있고, 의료 이미지 분류를 위한 CNN의 성능을 변화를 주는 지의 여부를 확인하기 위한 수단으로 사용하기 위해 CNN을 적용함
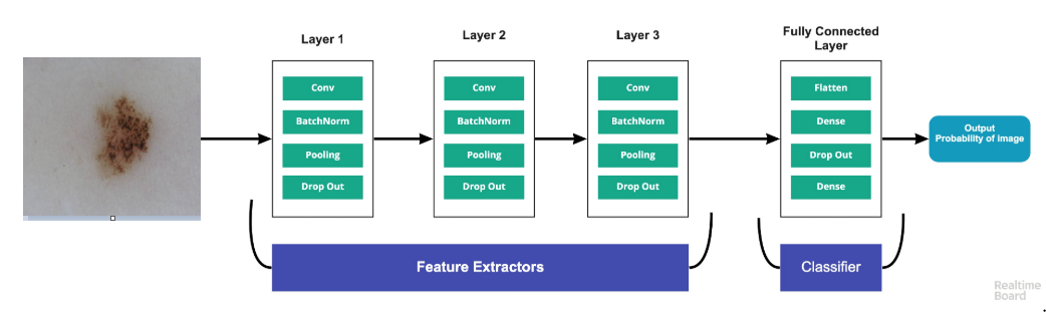
분석 세팅
- 원본 피부 이미지를 (128X128)해상도로 축소하여, Melanoma와 nevus를 구별하는 CNN을 설계함
- 실제 피부이미지는 melanoma와 nevus로 나뉘어 있는데, 이미지의 분포의 심한 비대칭 존재함으로 이를 조절하기 위해, class weight를 설정(1:14)함 (데이터의 분포가 적은 쪽으로 로스 웨이트를 높게 설정함)
- 총Train/Validation 이미지 데이터는 19,309장임. Test를 위한 이미지 데이터는 melanoma case 500장, nevus 500장으로 따로 빼놓음
- CNN의 이미지의 훈련을 돕기 위해, Image augmentation 추가함 (rotation(15); rescale(1./255); shear(0.1); zoom(0.2); horizontal flip; height/width shift(0.1)
- CNN 훈련과정에 Early stop, learning rate 기법을 포함하여 진행함
결과
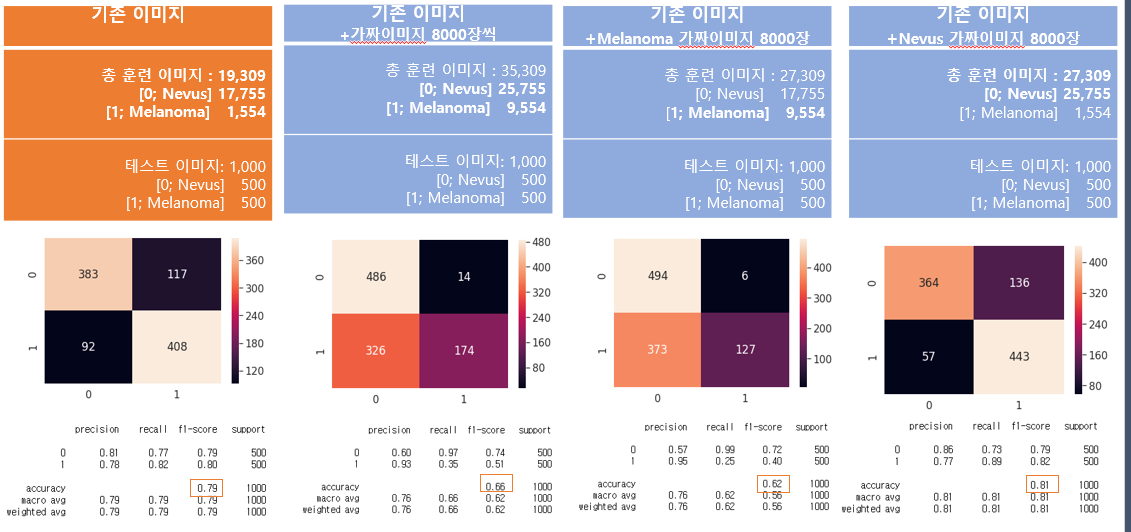
- 실제 GAN에서 생성된 Melanoma 가짜 이미지는 CNN을 트레이닝 하는 결과에 좋은 성능을 보여주지 못함. 이는 원본이미지에서 Melanoma의 class의 사진 양이 적기 때문에, 실제로 GAN을 통해 생성하는 가짜 이미지는 Melanoma의 특징을 충분히 반영하지 못하는 것으로 판단됨
5. 결과 및 의의
- 이미지 개수의 한계성이나 연구자의 리소스의 한계로 상위 모델을 사용하기 어려울 경우, 이미지의 전처리 과정이 필수임
- 실제 훈련하고 싶은 클래스에 대한 이미지의 양이 많을수록 좋은 결과(해당 클래스의 특징을 많이 포함함)의 가짜 이미지를 얻어 낼 수 있음
- 복잡한 상위 GAN모델은 해당 연구자의 리소스와 같은 환경에서 진행하지 않으면, 예전에 연구된 하위 GAN모델의 성능보다 저하될 수도 있음
- GAN을 처음 접하는 연구자들이나 환경리소스가 충분하지 않은 연구자들에게는 DCGAN을 기반으로 학습을 하는 것이 좋음
- 현재 GAN의 생성되는 이미지 사이즈(해상도)/안정성의 문제점은 여전히 연구 중임
특히, BigGAN의 연구진은 모델사이즈를 올리고(scaling up), batch size를 늘려 높은 해상도 및 화질의 가짜 이미지를 생성함. 하지만, 가짜 이미지의 해상도와 질을 동시에 올리기 위해서는 network에 파라미터의 양을 늘리고, 세부적인 아키텍쳐 상 layer가 deep해야하는데, 쉽게 접할 수 있는 환경의 리소스로는 불가능함 (실제 BigGAN연구자는 구글의 512개의 Tensor Processing Units (TPU)를 사용하여 훈련하고 512 pixel 사이즈의 가짜 이미지들을 생성하는 데 약 24~48시간이 걸렸다고 함. 만약 TPU가 200 Watt/h의 전기를 사용한다고 한다면, 이러한 연구과정은 약 2450~4915 kilowatt/h를 사용한다는 뜻인데, 이는 보통 미국사람들이 가정에서 쓰는 6개월치의 전기를 사용하는 것이라고 함)
- 이 과제의 목표는 실제 존재하는 의료용 이미지 데이터를 GAN을 통해 훈련하고 가짜 이미지를 생성하여 학습/연구용으로 공유하는 것이 가능한가를 알아봄
- CNN을 구현하여 가짜 이미지를 넣었을 때의 변화를 평가함을 통해, 원본이미지가 많이 존재하였던 nevus는 잘 판단하고, 원본이미지가 적게 존재하였던 melanoma는 판별하지 못한 것을 관찰함. 이를 통해, 타겟클래스의 원본이미지의 양이 GAN을 통해 생성되는 가짜 이미지의 질(특징 추출)을 결정함
- 본 연구자들은 병원의 의료용 이미지 데이터는 보통 높은 해상도의 이미지가 많으며, 해상도의 축소로 인해 상실되는 중요한 정보들이 의료용 이미지 데이터에는 중요하기 때문에, 현재 GAN기술로는 목표달성이 어렵다고 판단함
- 따라서, 데이터를 학습시켜 가짜 이미지를 생성하는 방법 외에 기본 이미지에 특정한 특징을 입힐 수 있는 pix2pix GAN, CycleGAN, DiscoGAN등을 응용하는 기법들이 학습/연구용 의료 이미지 데이터를 생성에 더욱 효과적일 것으로 판단함
현 연구에서는 실험하지 못하였지만, BigGAN과 다른 방법으로 quality, stability, variation을 항상 시켰다는 Progressive Growing GAN(2017) 을 시도해보는 것을 권유함
- 여러 연구결과에서 알려진 사실과 직접 GAN을 돌리며 얻은 결과를 비교하고, GAN으로 의도한 목표 성취가 가능한지의 여부를 알아봄
- 실제로 GAN을 훈련할 때에 필수적으로 고려해야 할 사항 및 문제점들을 제시함
- 일정량의 데이터를 보유하고 있는 센터에서 GAN을 통해 이미지 데이터를 생성하여 타 기관에서 접근하기 힘든 의료 이미지 데이터를 교육 혹은 연구용으로 배포가 가능하다고 보았으나, 이를 위해서는 너무 많은 환경 리소스(시간, 비용)가 필요함
- 가짜 이미지를 생성하는GAN보다 기본이미지의 특징들을 다르게 변화시키는 종류의 GAN 응용하는 기술을 사용하여 학습/연구용 이미지를 생성하는 것이 더 나을 것으로 파악됨