1. Introduction
2018 연세 빅데이터 분석 공모전에서 수상 결과로서 당시 데이터를 제공한 (주)모나미에서 인턴 기회를 얻었다. 같은 팀원들과 또 한 번의 분석 프로젝트를 할 수 있는 기회이고, 무엇보다 우리가 공모전에서 분석한 것들을 비즈니스 입장에서 평가받고, 기업에서 원하는 데이터 분석을 경험하고 싶다는 생각에 팀원들을 설득해서 참여했다. 회사 생활은 처음이 아니지만 데이터 분석 직무를 맡는 것은 처음이었기 때문에 당시 분석 자체(많이 부족하다..) 보단, 분석에서 맡은 역할에 초점을 맞춰 설명하겠다.
2. 문제 정의
모나미는 문구류를 제조, 유통하는 회사다. 여러 부지의 공장에서 상품을 생산하기 때문에 SKU(Stock Keeping Unit) 별 재고를 효율적으로 관리할 필요가 있다. 지나치게 비대한 재고는 팔리지 않고, 관리해야 한다는 점에서 손실이 발생한다. 제품 생산량은 영업부에서 작성한 사업계획을 토대로 결정된다. 사업계획은 매년, 매월 영업부에서 각 거래처와 협의해 어떤 제품을 얼마나 팔지 계획한 것이다. 사업계획을 정확하게 작성할 수록 적합한 양의 제품만을 생산하기 때문에 재고를 줄일 수 있어 손실이 감소한다.
따라서 다음을 목표로 잡았다. 데이터에 대한 설명(변수, 크기 등)과 기존의 예측 방식에 대한 자세한 설명은 기밀이기 때문에 생략한다.
- 예측 정확도 향상
- 예측 정확도 지표 계산
2. 분석
2-(1) 데이터 수집
매출 데이터, 거래처 리스트, 품목 리스트
2-(2) 데이터 통합
데이터 정합성의 어려움이 컸다. 거래처, 품목 리스트가 따로 존재하여 각각 필터링하기 때문에 발생하는 문제점이 있다. 예를 들어 A제품은 B업체에 더 이상 납품하지 않지만, C업체에 계속 납품하고 있다면 리스트에 포함되기 때문에, 결과적으로 필터링한 데이터에는 B업체의 A제품 납품기록까지 포함되는 문제가 생긴다. 이런 경우 actual value, predict value 모두 0이기 때문에 예측할 필요가 없을뿐더러 결과를 왜곡시킨다. 대체로 오랜 기간 동안 거래 내역이 없는 경우는 향후에도 거래하지 않는 경우가 많지만, 몇 년이 지나고 다시 거래하는 경우도 있다.
- 향후 거래할 업체 혹은 납품할 품목

거래처, 품목별 거래 기간 사이 공백 기간의 분포를 count한 것인데, 다시 거래한다면 대체로 500일 이내에 이뤄지지만, 몇 년 후에 다시 거래한 경우가 적지 않음을 확인할 수 있다. 이로인해 향후 거래할 업체 혹은 납품할 품목을 판단하는 것은 그 자체로 까다로운 분석 주제가 될 수 있다. 예측 기간인 3개월 내에 거래가 한 번이라도 이뤄진 경우만 다룸
2-(3) 파생변수
데이터를 깊이 이해하는 것에 초점을 맞췄고, 이러한 작업을 통해 예측 정확도를 조금씩 높일 수 있었다.
- 매출금액
- 거래처 주소, 제품 색상 및 세트, 납품사 경쟁 업체 수
2-(4) 모델 관련
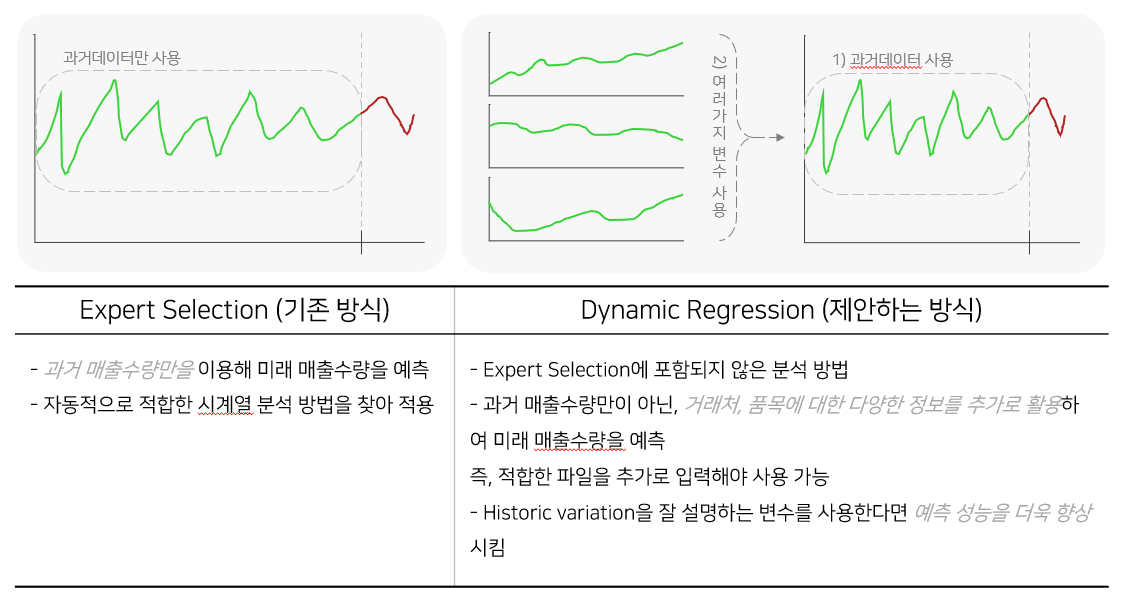
dynamic regression 기존에는 단변량 시계열 분석에 그친다는 한계점이 있다. 거래처, 품목 등에 대한 정보를 분석에 활용할 수 있다면 보다 더 높은 예측 정확도를 얻을 수 있으며, 시계열 자료의 경우, multiple time-series 기법 중 하나인 dynamic regression
Dynamic regression은 linear regression model을 구축하고, error term η_t가 ARIMA model을 따른다고 가정하며, white noise error ε_t를 갖는 예측 모델이다. 모델의 독립변수가 될 시계열 변수가 historical variation을 잘 설명할수록 모델 성능을 향상시킬 수 있다. 매출수량에 유의한 영향을 미치는 변수를 탐색하기 위해 ANOVA 검정, Bartlett 검정, Correlation 검정을 시행하여 연&월, 광역자치단체, 채널, 품목군, 대분류, 중분류, 단위 변수를 선별
2-(5) 예측 지표
품목별 MAPE를 다음과 같이 계산함. 
예측에 사용하는 데이터 기간은 MMAPE를 최소화하는 방향으로 21개월 설정함
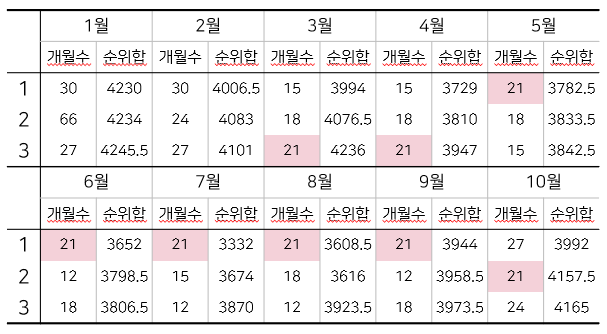
품목별로 MAPE가 작은 순으로 개월수에 순위를 부여하였고, <그림4-2> 각 개월수마다 모든 품목의 순위를 합산한 것이 작을수록 예측력이 좋은 것으로 판단하였다
3. 결과
데이터의 기간을 설정하는 문제는 통계적 분석을 통해 의미있는 결론을 얻기 어렵다. 기존의 방식과 별반 차이가 없으며 이 점에서 세부적인 사항은 업계 상황을 숙지하고 있는 사원분들의 직감이 훨씬 적합하다
Dynamic regression을 통해 프로그램의 예측 정확도를 향상시킬 수 있었다. <표7>은 두가지 최종 모델의 MAPE 기술통계량을 1~10월까지 기존 expert selection 방식과 비교한 것이다. MAPE의 평균, 중간값, 표준편차가 가장 낮게 나온 모델의 조합은 선형회귀를 사용한 연도&월 + 채널 + 대분류(model 1)와 rank를 사용한 연도&월 + 채널 + 대분류 모델(model 2)이다. Model 1은 여름에 예측을 잘하고, model 2는 봄과 겨울에 예측 정확도가 높다고 볼 수 있어 계절에 따라 다른 모델이 필요함을 제시하고 있다
- 기존의 expert selection 방법은 품목별 예측 오차의 변동성이 매우 커서 어떤 제품은 잘 예측할지라도, 다른 제품은 예측이 매우 빗나가는 반면, dynamic regression을 사용하여 품목별 매출수량을 예측한다면, 품목별로 큰 변동성 없는 예측이 가능하다. 전체적인 정확도 면에서도 기존의 expert selection보다 dynamic regression이 다소 정확하다고 볼 수 있다