글 쓴 배경
CF는 Collaborative Filtering의 준말로 대표적인 추천 알고리즘 중 하나다. 사실 CF 자체에는 관심 없고, 실시간 추천 서비스가 어떻게 동작하는지 궁금했다. 특히 모델 업데이트, 서빙 아키텍쳐, 더 나아가면 추천 시스템 Ops 등 다만 간단한 알고리즘이라도 알고 있어야 뭘 활용하니까 대표적인 흐름만 공부했다. CF란 무엇이고, 이걸 파이썬으로 구현한 과정을 정리했다. 이 글을 시작으로 CF, 로깅, 도커에 대한 글을 시리즈처럼 써보려고 한다. 시리즈라고 한 이유는, 이게 다 추천 서비스 스터디에 참여하면서 배운 것 & 내가 담당한 것들이기 때문이다.
들어가기 전
읽기 전, 내가 남한테 추천할 때 어떤 사고 방식으로 추천하는지 논리를 되새겨 보면 좋다.
- 저 사람은 이런 상품을 좋아한다. 이 상품과 유사한 상품에는 A 상품도 있다. 그래서 A 상품을 추천함 -> Content-based Filtering
- 저 사람은 이런 상품을 좋아한다. 이 상품을 좋아하는 사람들을 보통 B 상품도 좋아한다. 그래서 B 상품을 추천함 -> Collaborative Filtering
위 두가지 모두 filter라는 용어가 쓰인다. 처음엠 filter가 아닌 select라고 보는게 맞지 않을까 싶었지만, 어감 차이가 있는 것 같다. Filtering은 방대한 양의 데이터에서 관련성 높은 것만을 걸러내는 과정이다. Select는 내가 인지할 수 있는 범위 내의 것들 중에서 선택하는 것이다. Filtering이 약간 기계적인 뉘앙스라면 selection은 상대적으로 더 인간적(?)인 뉘앙스라고 정리해본다.
왜 collaborative라는 용어를 썼을까? 본문에서 살짝 다뤘다.
Collaborative Filtering(CF)이란
먼저 CF는 아래 논문에서 처음 나온 개념인 것으로 보인다.
- 이 논문은 Tapestry라는 시스템 소개글에 가깝다. 이 시스템을 소개하면서 collaborative filtering이란 용어가 등장한다. 이후 CF의 개념, 시스템 아키텍쳐 등에 대해 언급한다.
- Collaborative filtering simply means that people collaborate to help one another perform filtering by recording their reactions to documents they read
- 메일링 시스템에서 추천 모델이 나왔다는게 신기하다. 나는 개인용, 업무용 메일 모두 양이 그렇게 많지 않아 대부분 확인하는 편이다. 그래서 메일링 - 추천을 연관짓기 어려웠지만, 아마 그 당시에는 모든 뉴스, 광고, 업무가 메일로 왔었기 때문에 자연스럽게 필터링이 필요하지 않았을까
- 논문에선 정확한 알고리즘이나 수도 코드가 없다. 대략적인 방식은 아래와 같다.
- 사용자가 문서에 대한 평가를 anootate한다.
- 이 값을 기반으로 다른 사용자와의 annotation 간 유사성을 계산한다.
- 유사도를 기반으로 나와 평가가 비슷한 사용자를 필터링한다.
- 논문에선 ‘비슷한 사용자’, 즉 사용자 간 유사도를 어떻게 계산하는지 구체적으로 언급하진 않았다. 이후에 코사인 유사도, 피어슨 상관계수 등의 방법을 적용한 논문이 나왔다. (이 기본적인게 나중에 나왔다면 도대체 이 논문에선 어떻게 계산을 했던건가..?)
- 이 논문에선 추천을 제공하는 것이 아닌, 직접 추천을 받는(?) 것에 초점이 맞춰져 있다.
- 사용자 간 서로의 annotation을 공유 DB 위에서 탐색할 수 있다.
- Tapestry Query Language라는 쿼리 언어를 직접 만들어서 이걸로 유사도를 직접 계산한다.
- 직접 계산한 유사도를 바탕으로 비슷한 사용자를 필터링한다.
- 사용자가 스스로한테 추천을 해야하는 방식이라는 점에서 현대의 추천 시스템과 많이 다르다고 느꼈다. 왜 이렇게 했을까 궁금하긴 하다.
- 다만 이 점에서 collaborative라는 용어로 시작한게 납득은 된다. 온전한 내 생각이지만, collaborative의 뉘앙스는 협력을 하는 주체에게 초점이 맞춰져서 이 주체가 직접 협력을 하는 듯한 의미를 갖는다고 생각한다. 이 때의 CF는 위에서 언급한대로 사용자가 스스로 추천을 능동적으로 받아야 했다. 그래서 다른 사용자와 협엽이라는 개념이 자연스럽지 않았을까? 지금 시대에서 추천이란 일종의 서비스로서 협업과는 다소 의미가 멀다고 생각한다.
- 사용자의 평가(annotation)에 직접적으로 의존하기 때문에 memory-based라고 할 수 있다.
이 논문에서 시작된 CF는 아래와 같은 특징으로 정리할 수 있다.
- 사용자가 문서에 대해 평가한 것이 user가 item에 대한 평가(interaction)으로 대응된다. 이 데이터는 interactions를 value로 갖는 user * item matrix로 볼 수 있다.
- 간단하게 useri-item interactions 라고 한다.
- CF는 user-item interactions 데이터를 바탕으로 아이템을 추천하는 전략이다.
- Content-based Filtering(CBF)는 item data만 가지고 추천하는 전략이다.
- 예를 들어 CF를 사용해서 나에게 영화를 추천하는 상황이다. 나와 선호도가 비슷한(평점을 비슷하게 매긴) 사용자들을 찾는다. 이 사용자들이 좋은 평점을 매겼지만 나는 아직 안 본 영화를 추천한다.
- CF 단점은 크게 두가지다.
- Cold start: CF 기반 추천 시스템이 작동하려면 충분한 양의 user-item interactions가 있어야 한다. 데이터가 충분히 쌓이기 전까진 CF로 제대로 된 추천을 할 수 없다.
- 새로운 사용자, 아이템 추가 시 기존의 interactions가 없기 때문에 추천받거나, 추천되기 어렵다. (이를 보완하고자 hybrid system이 나왔다.)
더 나아가 CF를 memory-based와 model-based로 나눌 수 있다.
- Memory-based CF는 user-item matrix를 메모리에 올려두고 새로운 추천이나 예측이 필요할 때 마다 이 행렬을 참조해서 유사도를 계산한다.
- Memory-based CF는 먼저 비슷한 정도를 사용자 단에서 파악할 것인지, 아이템 단에서 파악할 것인지에 따라 item-based filtering과 user-based filtering으로 구분된다
- item-based는 아이템 간 유사성, user-based는 사용자 간 유사성을 각각 기반으로 한다.
- item-based의 경우 CBF와 다른 점은,
- item-based: 사용자들의 행동 데이터를 기반으로 아이템 간 유사성 추정한다. 예를 들어 많은 사용자들이 영화 A와 B에 비슷한 평점을 부여하면, A와 B는 유사하다고 본다.
- CBF: 아이템의 내용 또는 특성을 기반으로 아이템 간 유사성 추정한다. 예를 들어 영화 A와 B가 같은 장르와 같은 감독의 작품이라면 A와 B는 유사하다고 본다.
- Memory-based CF는 먼저 비슷한 정도를 사용자 단에서 파악할 것인지, 아이템 단에서 파악할 것인지에 따라 item-based filtering과 user-based filtering으로 구분된다
- Model-based CF는 user-item 상호작용 데이터를 바탕으로 모델을 사전 학습시키고, 학습된 모델을 사용해서 추천한다.
이 중 model-based CF에 대해 자세히 살펴보겠다.
Model-based CF
- 아이디어는 간단하다. user-item interactions의 패턴을 통째로 학습한 뒤, 학습한 패턴을 기반으로 사용자가 선호할만한 top-N items를 예측한다.
- Memory-based CF에 비해 sparse한 user-item matrix에서도 효과적인 추천을 할 수 있다.
- Model-based CF는 아래와 같이 분류할 수 있다.
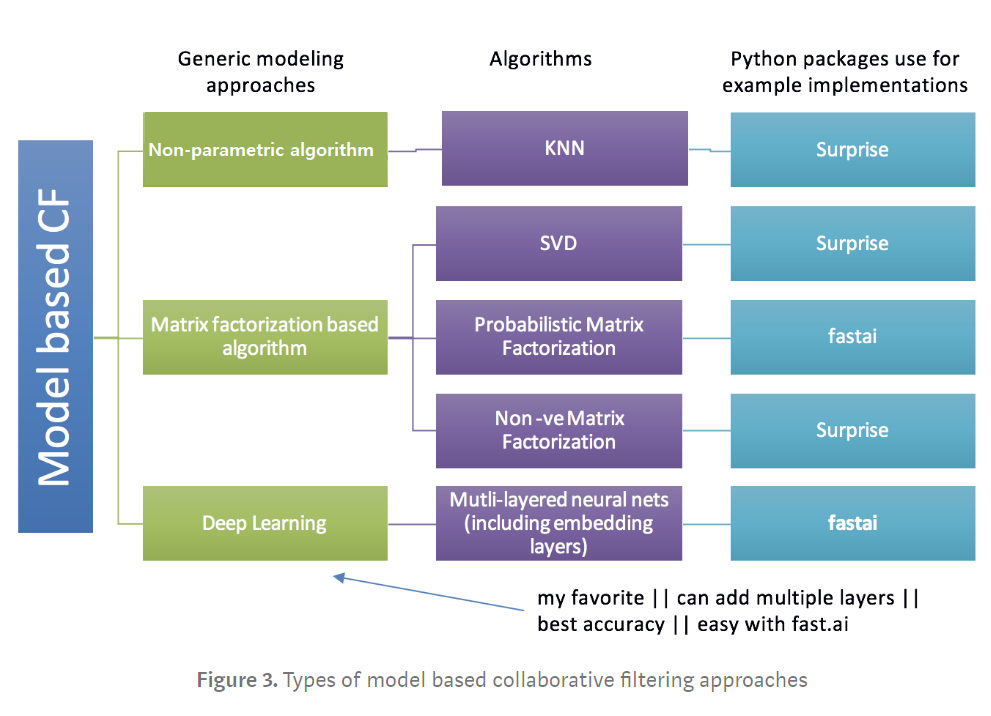
- Non-parametric approach: 유사성을 추정하되 비지도 학습 방식을 사용한다는 점에서 메모리 기반 CF와 다르다. 대표적으로 KNN 방식이 있다.
- Matrix Factorization based algorithm: 사용자-아이템의 선호도를 latent factor로 설명할 수 있다는 가정에 기반한다.
- 대표적으로 Singular Value Decomposition (SVD)가 있다.
SVD
- \(R\)라는 \(m*n\) 행렬이 있다고 가정하자. \(m\)은 유저 수를 \(n\)은 아이템 수를 의미한다.
- \(R = USV^T\)로 decompose하는 것이 SVD이다
- \(U\): \(m*r\)의 orthogonal matrix, 각 행은 사용자의 잠재적 특성을 나타냄
- \(\Sigma\): \(r*r\)의 diagonal matrix, 대각선 원소는 각 잠재적 특성의 중요도를 나타냄
- \(V\): \(n*r\)의 orthogonal matrix, 각 행은 아이템의 잠재적 특성을 나타냄
- SVD를 사용해 \(R\)의 latent factors를 추출함으로써 차원을 \(r\)개로 줄일 수 있다. 각 사용자와 아이템을 \(r\)개의 잠재 요인으로 나타내는 것과 같다.
- Deep Learning: MF를 응용한 것이라 볼 수 있는데, NN을 사용해서 embedding matrices의 값을 업데이트(최적화)하는 방식이다.
- SVD는 단순한 matrix decomposition 기법. 이걸 기반으로 모델을 학습시키는 것은 아래 과정이 추가됨
- user-item matrix를 SVD 시켜 얻은 초기 \(U\), \(V\)를 무작위로 초기화함 (shape만 따오는건가?)
- 두 행렬의 내적을 가지고 예측 평점 행렬을 구함 (\(R_{pred}\))
- \(R\)과 \(R_{pred}\) 간의 오차 (SSE 또는 RMSE)를 계산
- Gradient Descent와 같은 최적화 알고리즘을 사용해 loss를 최소화하는 방향으로 \(U\), \(V\)를 반복적으로 업데이트시킴
- 오차의 변화가 특정 임계값 이하로 줄어들면 학습 종료
- 이렇게 학습된 \(U, V\)로 새로운 사용자와 아이템의 평점을 예측할 수 있음
- 예측한 평점에서 높은 평점을 추천할 수 있음
- SVD는 단순한 matrix decomposition 기법. 이걸 기반으로 모델을 학습시키는 것은 아래 과정이 추가됨
Model-based CF 구현 예제
| 링크 | 설명 |
|---|---|
| Machine Learning Mastery | |
| Analytics India Magazine | SVD를 사용해서 item의 latent features를 구한 뒤, 이걸 기반으로 Cosine similarity를 구해 아이템 간 유사도를 측정함. Memory-based CF의 item-based filtering을 SVD 사용해서 구한 예제 |
| Data Science HI | item-based filtering, user-based filtering을 KNN & cosine similarity를 사용해 구현 |
| Keras | NCF를 keras로 구현한 예제 |
| Kaggle | SVD를 사용하는데, user-item matrix에서 mean matrix를 빼서 Sparsity를 우회한 행렬에 SVD 적용, 결과로 얻은 세 행렬을 기반으로 내적시킨 값 + 앞에서 뺀 mean matrix를 다시 더해 예측 평점을 구함. 왜 굳이 mean matrix를 뺏을까? (추정) sparse matrix에 SVD를 적용할 경우, 아래와 같은 문제가 있을 수 있다고 함: 계산 복잡도 (\(O(m*n*min(m,n))\)), 누락된 데이터가 0으로 해석되어 결과 왜곡 |
| Simonezz Tistory | 파이썬 surprise 라이브러리의 SVD 함수 사용한 예제. |
Simon Funk SVD CF
내가 궁금했던 matrix factorization에 기반한 CF 연구는 아래 논문을 기점으로 활발해진 것으로 보인다.
Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender systems.
- model-based CF에는 여러 방법론이 있다.
- Latent Semantic Indexing
- Clustering Models
- Bayesian Networks
- Probabilistic Latent Semantic Analysis
- Markov Decision Process
- etc.
- 위와 같은 방법론이 나오다가, 2006년 Netflix Prize 경연에서 Simon Funk의 SVD 기반 CF가 우승하면서 matrix factorization(MF)에 기반한 model-based CF가 각광 받은 것으로 보인다.
- 2009년에 나온 위 논문은 Simon Funk가 저술한 것은 아니지만, Simon Funk의 SVD를 중점적으로 두면서 MF 기반 model-based CF의 개론(?)같은 느낌으로 작성된 것 같다.
- 참고로 Simon Funk는 해당 방법론에 대해 2006년 자신의 블로그에 이미 작성했다. https://sifter.org/~simon/journal/20061211.html
- 아래는 이 블로그 상단을 캡쳐한 것이다. 왜 이런 사진을 걸었을까?

- 논문을 통해 알고자 했던 것은 아래와 같다.
- 왜 model-based CF를 검색하면 SVD가 대세일지. 왜 이런 연구 흐름(?)이 생겼었는지
- user-item matrix는 sparse matrix이고 incomplete하기 때문에 SVD를 적용하기 불가능할 것 같은데 어떻게 적용했다는 것인지
- 파이썬 라이브러리(scikit-learn, Surprise)에서도 SVD에 기반한 학습 알고리즘을 제공하는데, 원리가 궁금했음
1. 왜 SVD를 model-based CF에 적용하려는 흐름이 생겼을까?
- Memory-based CF 등장 (당시엔 이런 이름 없었음. 단순히 NN 알고리즘에 기반)
- NN 알고리즘을 대체할 latent factor model based CF이 나옴
- Latent factor model의 여러 기법 중 matrix factorization methods이 대표적임
- \[\hat{r}_{ui} = q_i^T p_u\]
- Matrix factorization methods의 여러 기법 중 singular value decomposition에 기반한 방법이 나옴
- Conventional SVD에 기반한 학습 알고리즘 한계: sparse matrix(+ imputation도 불완전), overfitting
- 그냥 imputation 없이, 정규화만 반영함
- 아래의 최적화 문제를 해결하는 것과 같음
- \[\min_{q*,p*} \sum_{(u,i) \in \kappa} (r_{ui} - q_i^T p_u)^2 + \lambda (||q_i||^2 + ||p_u||^2)\]
- 방법은 stochastic gradient descent와 alternating least squares
- user-item matrix \(R\)이 있다고 할 때, 이 행렬을 두 개의 행렬 \(P, Q\)의 곱으로 근사시킴
- \[R \approx PQ^T\]
- \(P\): 사용자와 잠재 특성 공간 간 매핑시키는 행렬
- \(Q\): 아이템과 잠재 특성 공간 간 매핑시키는 행렬
- \(P, Q\)를 주어진 shape에 맞춰 무작위 값으로 초기화함
- 주어진 평점 데이터와 근사시킨 평점 데이터 간 예측 오차를 최소화하도록 \(P, Q\)를 SGD 방법으로 업데이트 함
왜 SVD일까?
- 방법을 이해하고 나니 드는 의문은, 왜 RS에서 굳이 matrix factorization을, 그 중에서도 SVD를 선택한걸까라는 것이다
- 일단 RS의 user-item matrix의 보편적 특징을 먼저 짚어볼 수 있다
- extremly high sparsity: RS에서 다루는 대부분의 user-item matrix는 매우 sparse하다.
- 애초에 모든 유저가 모든 아이템을 다 경험했다면 추천할 것이 없다. (재탕에 대한 니즈가 있는 시장이라면 얘기가 달라질까?)
- 이렇게 안 이쁜 행렬을 이쁘게 만들어주는 어떤 전처리 과정이 들어가지 않는 이상, 현재 이 User-item matrix에 적용 가능한 기법은 많지 않다
- 유저의 아이템에 대한 선호를 결정짓는 일종의 latent factor가 있을 것이라는 가정 (이 가정 하에선 모든 추천 문제를 matrix decomposition으로 접근 가능함)
- extremly high sparsity: RS에서 다루는 대부분의 user-item matrix는 매우 sparse하다.
- SVD는 high-sparse matrix에 적용 가능할 뿐더러(eigen-decomposition과 달리) 차원까지 축소시켜 이를 latent variable model로도 볼 수 있다는 강력한 장점이 있다.
- latent variable model도 처음에는 이해하기 어려웠다. 관련 설명을 읽어보면, 결국 값에 의미를 부여하는 것처럼 보이는데, 값 자체는 의미가 담길 수 없으니까… 그렇게 보겠다~라는 정도로 받아들이면 될 것 같다.
2. sparse, incomplete matrix에 SVD를 어떻게 적용했다는 것인지?
- 이 논문에서 말하는 SVD는 Funk의 SVD (Funk SVD)를 말함
- 논문에서도 sparse matrix에 SVD를 적용하기 위해 imputation을 해볼 수도 있다고 하는데, 불확실성이 증대해 비추한다고 나옴
- ‘Hence, more recent works suggested modeling directly the observed ratings only, while avoiding overfitting through a regularized model.’
- Conventional SVD를 적용하기 위해선 해당 행렬이 complete matrix라는 가정이 필요하며, 주어진 행렬을 세 개의 행렬의 곱으로 분해함
- Funk SVD는 sparse matrix에도 적용 가능하며, 세 행렬의 곱이 아닌 두 행렬의 곱으로만 근사시킴
- SVD와 Funk SVD간 연결점을 따지자면, 주어진 행렬을 latent factor model의 관점에서 다룬다는 것
- 복잡하게 생각할 것 없이 Funk SVD는 그냥 전통적인 SVD의 latent factor space라는 아이디어, 개념, 의미를 차용했다고 보면 됨
- 두 행렬로 분해시켜서 각각 학습시킨다는 관점에서만 보면 QR decomposition이나 eigendecomposition 등 일반적인 matrix decomposition을 사용했다고 해도 무방하지 않을까?
- 다만 잠재 특성이라는 개념을 사용했다는 점에서 SVD의 variation이라고 할 수 있는 것
- 상당히 직관적인 사고방식이다. 수학적 공식에 의해 만들어낸 알고리즘이라기 보다는, 지식을 넘어선 지혜에 기반한 방법론 같아 인상 깊음
3. scikit-learn, Surprise에선 어떤 방식으로 SVD 기반 학습 알고리즘을 구현한 것인지? (ChatGPT 참고)
- scikit-learn의 TruncatedSVD는 기존의 conventional SVD와 달리 \(\Sigma\)의 작은 값을 제거해서 행렬의 차원을 truncated 시킨 후, 이 행렬을 SVD 하는 방식
- Surpise의 SVD 알고리즘은 Simon Funk의 SVD를 구현한 것
- 두 방법 모두 conventional SVD의 변형(응용? 활용?)인 셈이라 sparse matrix에도 적용 가능하며, 사용자와 아이템의 잠재 특성을 학습하는 알고리즘이다.
그 외 논문 읽고 든 생각
- 구글링 할 때와 달리 논문을 읽고 정리 된 생각 중 하나
- 구글링: user-item matrix를 어떻게든 SVD 시켜서 나온 세 개의 행렬을 가지고 학습시키는 줄 알았음
- 논문: SVD의 개념만 차용. 학습시키는 행렬 자체는 무작위 추출에 가까움
- Mean matrix (\(\mu\))를 왜 빼는건가 궁금했었고, 스터디에서 사용자의 편향을 다루기 위한 장치라는 피드백을 받았는데, 논문에 이를 더 자세하게 설명함. 이해한대로 정리해보면,
- bias를 고려해야 하는 이유는 결국, 평가는 주관적일 수 밖에 없고, 그걸 수치화한 값 역시 사용자의 편향이 있음. 이러한 편향을 고려하지 않고 CF를 적용한다면, 대체로 평점이 높은 특정 아이템 군만 추천이 되거나, 대체로 높은 평점을 주는 특정 유저 그룹의 선택만이 추천될 수 있음. 그럼 편향을 모델에 어떻게 반영하고, 어떻게 측정할 것인지?
- 임의의 유저 \(u\)가 임의의 아이템 \(i\)에 대해 매긴 평가가 \(r_{ui}\)이라고 할 때, 이 평가에 포함된 bias를 \(b_{ui}\) 라고 함
- \(\hat{r}_{ui} = b_{ui} + q_i^T p_u\)로 위 식이 확장됨
- 논문에서는 가장 기본적인 first order approxiamte을 통해 \(b_{ui} = \mu + b_u + b_i\)로 정의함
- \(\hat{r}_{ui} = \mu + b_u + b_i + q_i^T p_u\)로 정의할 수 있음
- \[\min_{q*,p*,b*} \sum_{(u,i) \in \kappa} (r_{ui} - (\mu + b_u + b_i + q_i^T p_u))^2 + \lambda (||q_i||^2 + ||p_u||^2 + b_u^2 + b_i^2)\]
- bias는 intercepts와 비슷한 위치인 것 같음
- Bias 외 overfitting을 완화하기 위한 정규화 장치, implicit data(ex. user click rate 등)를 반영한 모델, temporal dynamics라는 시간에 따른 유저 선호도 변화까지 반영한 모델을 다루는게 인상 깊다.
- 논문에서 말하는 implicit data가 결국 우리가 배포하려는 서비스의 input data 형태가 될 것 같다. 논문에선 implicit data를 추가해서 예측을 보완하지만, 우리는 implicit data만으로 예측을 해야한다.
- 추천 시스템에 기반한 프로덕트의 retention을 위해서라도 temporal dynamic 모델을 다루는 것이 좋을 것 같다.
- 들어올 때 마다 같은 아이템만 표시한다면, 다시 이 서비스를 찾을 이유가 그렇게 크지 않을 것 같다.
- 내 선호가 바뀜에 따라 추천 받는 아이템도 바뀌는 것이 상식적으로도 그럴듯하다.
Funk SVD 기반 CF model (+ biased) 파이썬 구현
| 코드가 필요하신 분은 이메일 등으로 연락 부탁드립니다. |
- 메인 수식은 아래와 같다.
- \[\min_{q*,p*,b*} \sum_{(u,i) \in \kappa} (r_{ui} - (\mu + b_u + b_i + q_i^T p_u))^2 + \lambda (||q_i||^2 + ||p_u||^2 + b_u^2 + b_i^2)\]
- SGD를 사용해서 각 파라미터를 아래와 같이 업데이트 시킴
- \[b_u \leftarrow b_u + \alpha \left( e_{ui} - \lambda b_u \right)\]
- \[b_i \leftarrow b_i + \alpha \left( e_{ui} - \lambda b_i \right)\]
- \[p_u \leftarrow p_u + \alpha \left( e_{ui} \cdot q_i - \lambda p_u \right)\]
- \[q_i \leftarrow q_i + \alpha \left( e_{ui} \cdot p_u - \lambda q_i \right)\]
- \(e_{ui} = 1 - \left( \mu + b_u + b_i + q_i^T p_u \right)\) 는 예측 오차
- \(\alpha\)는 learning rate
- Train data: user_id, movie_id 열로 구성된 테이블
- 영화 시청 여부라는 implicit data만을 가지고 학습
- Ratings가 아닌 implicit data로 학습할 때 차이점?
- error 계산 시 추정한 값을 1에서 뺀다는 점
- 새로운 유저에게 추천
- user_id (int)와 movie_id (list)를 받아서 추천하는 movie_id의 index(movie_indices)를 출력
- 출력된 movie_indices를 movies.dat에 조인시켜 최종 추천 결과 받음
- 새로운 유저가 유입될 때 마다 모델 전체를 학습시킬 필요 없이, 새로운 유저에 대응하는 파라미터만 학습시킴
실시간 추천 서비스에서 model-based CF 구현
- 위 예제는 대부분 memory-based CF의 느낌이 있다. 실시간 추천 서비스에 적용한다면, 새롭게 유입되는 유저의 선호도 데이터에 대한 예측을 할 때, 위 예제를 적용하려면 결국 기존 User-item matrix에 concat 시켜서 다시 svd를 구해야 한다.
- 다르게 보면 새로운 사용자에게 아이템 추천을 해야할 때 마다 모델을 재학습시킨다는건데 비효율적이다
- user-item matrix가 얼마나 더 들어와야 모델을 재학습시키는 것이 효율적일지에 대한 문제?
- (추정) 학습된 사용자 특성 행렬(\(U\))과 아이템 특성 행렬(\(V\))가 있다고 할 떄, 새로운 사용자 선호도 벡터 \(r\)이 주어진 상황
- 이 사용자에 대한 추천은 결국 해당 사용자의 잠재 특성 벡터 \(u\)를 찾는 문제와 같음 (이걸 찾으면 여기에 아이템 특성 행렬를 곱해 선호도 높을 것이라 예상되는 아이템을 추천할 수 있음)
- \(u\)가 존재한다고 하면, \(uV\)는 \(r\)과 유사해야함. \({min}_u norm(r - uV)\) 라고 한다면
- \(r\)을 \(V\)에 선형 회귀시켜 구한 계수 = \(\hat{u}\)
- \(\hat{u}V\)의 벡터에서 선호가 높은 n개 아이템을 추천
- surprise 라이브러리의 SVD() 함수는 어떻게 새로운 사용자에 대한 아이템을 추천하는 것일까?
- 전체 데이터셋의 평균 평점을 기본 예측값으로 사용
- 사용자와 아이템 바이어스: SVD()는 사용자와 아이템의 바이어스 (편향)도 함께 학습한다. 이 바이어스는 해당 사용자나 아이템의 평점이 전체 평균에서 얼마나 떨어져 있는지를 나타낸다. 새로운 사용자나 아이템에 대한 예측을 생성할 때, 이 바이어스를 전체 평균에 더하여 예측값을 조정한다.
- 잠재 특성: 만약 새로운 사용자에 대한 아이템의 평점을 예측하려면, 이 사용자의 잠재 특성을 알면 된다. 그러나 이 사용자의 잠재 특성은 학습 데이터에 포함되지 않았기 때문에 직접적으로 알 수 없다. 이 경우, SVD()는 전체 사용자의 평균 잠재 특성을 사용한다. (반대의 경우에도 마찬가지입니다)
- 위의 세 가지 구성 요소 (평균 평점, 바이어스, 잠재 특성)를 결합하여 새로운 사용자나 아이템에 대한 평점 예측을 생성한다
- 모델 파라미터 ver 1을 저장소에 올림.
- 저장소에 있는 모델을 가져다가 t 시점에 접속한 신규 유저의 인풋을 받아 추천 결과 생성
- 이후 t+1 시점까지 새로 수집된 유저, 아이템 로그를 기존 데이터셋에 붙임
- 붙인 데이터셋으로 모델 다시 학습 시킴
- 학습 시킨 모델 ver 2를 저장소에 덮어씌움
- 모델 성능 평가할 때 여러 지표를 사용 (CTR, CVR, Diversity 등)
- 실시간 서비스에선 이 지표를 모니터링 하는 용도로만 보지 않을까?
- 지표가 유의하게 낮으면 모델을 재학습 시키거나, 알고리즘을 바꾸는 등의 조치 가능
- 위 두 케이스와 같이 데이터가 유의하게 쌓이거나, 지표가 유의하게 변동하는 경우 모델을 재학습 시킬 수 있다.
- 같은 유저가 여러번 페이지에 접근하는 경우, 매번 다른 추천을 어떻게 띄워줄지?
- multi-armed bandit
- 유저의 선호가 시간에 따라 변할 수 있음. 이런 변동성까지 반영할 수 있는 모델?
- temporal dynamics, sequential ratings를 반영한 모델
- 진정한 의미의 실시간 추천은 불가능하다고 함
- 유저가 클릭한 직후 전체 모델이 업데이트 되어서 다른 유저의 추천에 영향을 미치는게 불가능하기 때문
- 대부분의 추천 시스템은 사실 준-실시간 추천이라고 함
공부하려는 추천 모델, 시스템 방향
- 필터 버블을 느끼게 되면 유저는 서비스를 이탈하는 것 같다.
- 이런 한계를 보완하는 여러 방법 중 serendipity에 대해? 어떻게 구현하는지
- 동적인 추천 알고리즘을 제공하면 필터 버블을 자각한 유저의 이탈을 막을 수 있지 않을까
- 웹에서 사용자가 직접 추천 알고리즘의 여러 paramters를 조정할 수 있는 시스템
- 예를 들어 ‘다양성’를 1~100까지 스크롤로 보여주고, 기본 값이 50이라 했을 때 유저가 100으로 늘리면 100의 입력값을 받아서 이걸 모델에 적용
- 추천 시스템 아키텍쳐
- 추천 시스템 MLOps
- 추천 시스템 로깅 with 도커