Background
분석가라면 주기적으로 컨플루언스(위키) 문서를 만들 일이 있을텐데, 이런 문서는 크게 두 부분으로 나뉨
- 고정적인 부분: 대시보드에 나타난 수치, 테이블 일부, 그래프
- 변동적인 부분: 분석가가 전달하려는 인사이트
이 중 고정에 해당하는 내용을 작업하는데 매번 많은 리소스가 들어간다는 비효율 이슈가 있음
- 태블로 대시보드 캡쳐
- 슬랙 메시지 복붙
- 쿼리 결과를 위키 테이블에 하나씩 복사 등
위 작업을 모두 자동화시킨다면 그만큼 불필요한 리소스를 덜어낼 수 있지 않을까? 이런 생각은 평소에도 가지고 있었는데, 마침 팀 내 몇 명의 니즈와도 맞아 떨어져서 작업 시작하게 되었다.
…
자동화는 크게 세 단계로 나뉜다.
- [데이터 수집] 문서 작성에 필요한 데이터를 데이터브릭스에서 수집 & 집계
- [데이터 전처리] 수집한 데이터를 전처리 후 HTML 수정 (파싱 & DOM 조작으로 정형화시켜볼 여지 있음)
- [데이터 전송] 수정한 HTML을 json으로 담아 컨플루언스 API로 post 요청
환경은 데이터브릭스 플랫폼 사용했는데, 이유는 다음과 같다.
- python api 지원
- 각종 데이터 접근 용이
- html 파싱, 수정 편리
- 스케줄러 내장 (workflow)
데이터 수집 - Tableau REST API
Tableau REST API 사용을 위한 PAT 발급
- 태블로 클라우드 접속 (https://prod-useast-a.online.tableau.com/#/site/kraftonbi/home)우측 상단 계정 클릭 → 내 계정 설정
- 토큰 이름 입력 후 ‘새 토큰 만들기’ 클릭

- 생성된 토큰 이름과 토큰 암호는 별도 저장 필요(발급 당시에만 확인 가능하기 때문)
Q. Tableau Server Client (TSC) 라이브러리를 사용한 방법?
- API 문서: https://tableau.github.io/server-client-python/docs/api-ref
- 아래 rest api의 복잡한 http 요청을 python으로 감싸준 것 → rest api의 기능을 모두 제공하지 않음
- 데이터브릭스에서 해당 모듈 임포트하면 데이터브릭스 일부 유틸과 충돌 이슈 있어 REST API 사용하기로 함
Tableau REST API 접근하기 위한 authentification
- 태블로 서버에 접근하기 위해선 매번 auth를 인증받아야 함
- 위에서 발급 받은 PAT과 달리 temporary 성격이 있어 일정 시간 후에는 자동 만료됨 (PAT과 더불어 이중 보안 성격이 강함)
- 전송 받은 credentials_token은 API 엔드포인트의 header에 필요한 값
- 그 외 server_url, api_version 은 다른 엔드포인트에 필수적으로 사용되기 때문에 global 변수로 할당함
- 중간의 ET는
from xml.etree import ElementTree as ET로 로드할 수 있는데, xml 파싱하는 도구다
server_url = '*'
api_version = '*' # 사용하려는 API의 버전에 맞는 값을 부여해야 함
def get_tableau_auth():
token_name = '*'
token_value = '*'
site_content_url = '*'
signin_url = f'{server_url}/api/{api_version}/auth/signin'
signin_body = {
"credentials": {
"personalAccessTokenName": token_name,
"personalAccessTokenSecret": token_value,
"site": {
"contentUrl": site_content_url
}
}
}
response = requests.post(signin_url, json=signin_body)
root = ET.fromstring(response.text)
ns = {'ns': 'http://tableau.com/api'}
credentials_token = root.find('.//ns:credentials', ns).attrib['token']
site_id = root.find('.//ns:site', ns).attrib['id']
return credentials_token, site_id
View 데이터 가져오기
- REST API를 사용해서 뷰의 데이터를 수집할 수 있음 (대시보드 전체를 한번에 호출 할 수 없음)
- 뷰: 시트, 대시보드를 일컫음
- 가정
- 수집하려는 뷰의 id를 알아야 함
- 뷰가 숨겨진 상태면 호출 불가
| 설명 | 엔드포인트 예시 |
|---|---|
| 통합 문서 (workbook)의 이름을 토대로 id 확인 | f'{server_url}/api/{api_version}/sites/{site_id}/workbooks/?pageNumber={page_number}&pageSize=100' |
| workbook id를 사용, 해당 workbook에 포함된 모든 view의 id를 확인. 이 중 필요한 view id를 확인 | f'{server_url}/api/{api_version}/sites/{site_id}/workbooks/{workbook_id}/views' |
| 해당 view id가 포함된 엔드 포인트로 데이터 요청 | f'{server_url}/api/{api_version}/sites/{site_id}/views/{view_id}/data' |
- 코드 예시
view_ids = []
headers = {
'X-Tableau-Auth': credentials_token,
'Accept': 'application/json'
}
workbooks_url = f'{server_url}/api/{api_version}/sites/{site_id}/views/{view_id}/data'
response = requests.get(workbooks_url, headers=headers)
response.text
View 이미지 가져오기
- 작동 방식은 간단한데,
- view의 이미지를 받아와서 dbfs에 png로 저장
- 저장한 png를 컨플루언스 문서의 첨부파일로 업로드
- 다만, 첨부파일로 업로드 시키기만 하면 문서에 자동으로 표시되지 않음
- 문서 html 구조에 해당 파일을 사용하도록 작성되어 있어야 첨부파일이 표시되는 구조
- ex) 아래와 같이 파일명을 html 구조에 미리 포함시킨 뒤에, 이후에 첨부파일 업로드하면 자동으로 문서에 표시됨
- DBFS란? 데이터브릭스 플랫폼의 Data Base File System인데 파일 저장, 조회 할 수 있는 구조라고 할 수 있다.
- 사내에선 데이터브릭스 플랫폼을 쓰고, 이 노트북에서 자동화 코드를 실행하기 때문에 png 파일을 임시 저장할 파일시스템으로 DBFS를 사용했다
<p>
<ac:image ac:width="1400">
<ri:attachment ri:filename="image_{device}.png" />
</ac:image>
</p>
- View 이미지 다운로드 & DBFS에 임시 저장 코드 예시
def download_view_image():
view_id = ''
workbooks_url = f"{server_url}/api/{api_version}/sites/{site_id}/views/{view_id}/image"
headers = {
'X-Tableau-Auth': credentials_token,
'Accept': 'application/json'
}
response = requests.get(workbooks_url, headers=headers)
image_data = response.content
dbfs_path = '/dbfs/~'
image_path = f'{dbfs_path}/view_image.png'
if image_data:
with open(image_path, 'wb') as file:
file.write(image_data)
return image_path
- 데이터브릭스 노트북에서 출력 & 확인 코드 예시
from IPython.display import Image
image_path = download_view_image(device)
display(Image(filename=image_path))
- DBFS에 저장된 이미지를 컨플루언스 문서 첨부파일로 업로드코드 예시
- headers 양식 유의
- 업로드하려는 문서의 page id를 알고 있어야 함
def upload_image_to_confluence(page_id):
confluence_api_token = '*'
headers = {
"Authorization": f"Bearer {confluence_api_token}",
"Content-Type": "multipart/form-data",
"X-Atlassian-Token": "no-check"
}
ctx = create_urllib3_context()
ctx.load_default_certs()
ctx.options |= 0x4
image_path = download_view_image()
image_name = f'image_temp.png'
url = f"https://*/api/content/{page_id}/child/attachment"
with urllib3.PoolManager(ssl_context=ctx) as http:
with open(image_path, 'rb') as file:
file_data = file.read()
field = RequestField(name='file', data=file_data, filename=image_name)
field.make_multipart(content_type='image/png')
fields = [field]
body, content_type = encode_multipart_formdata(fields)
headers['Content-Type'] = content_type
r = http.request('POST', url, body=body, headers=headers)
return r.status
- 업로드 된 png 파일 편집
- 문서 우측 상단 점 세 개 버튼 클릭 → 첨부파일 클릭
- 아래 화면에서 ‘편집’ 클릭
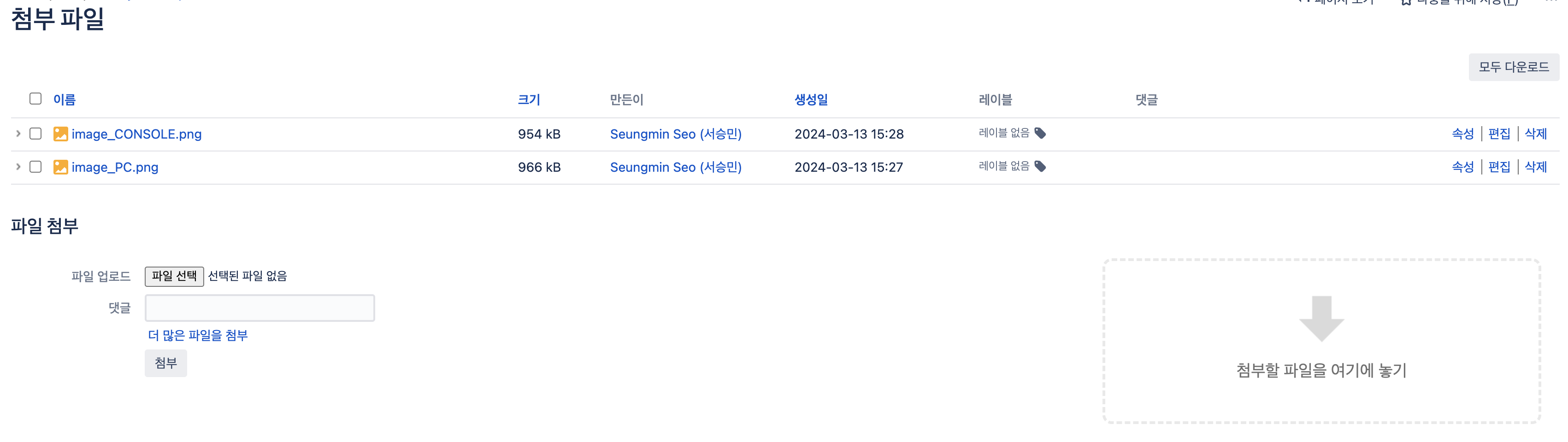
- Atlassian Companion 앱 다운로드
- OS 내장 뷰어의 자르기 기능(맥의 경우 마크업) 등 적용
- 파일 수정 후 저장하면 Atlassian Companion 프로그램 상에서 ‘업로드’ 버튼 활성화됨. 버튼 클릭하면 저장된 이미지가 문서에 반영됨
View에 필터 걸어서 데이터 가져오기
- 아래와 같이 key-value 쌍을 ‘vf_’ 접두어 붙여서 쿼리할 수 있음
?vf_{field-key-name}={field-value}
Github Region과 같이 띄어쓰기가 포함된 필터의 경우, url encoded된 키를 줘야함?vf_Github%20Region=CN.
- API 문서: https://help.tableau.com/current/api/rest_api/en-us/REST/rest_api_concepts_filtering_and_sorting.htm#Filter-query-views
- 만약 대시보드 필터의 이름을 수정헀다면, 수정한 필터명을 사용해야 함
데이터 수집 - Slack API
- 슬랙 메시지, 쓰레드 등
- 클러스터 library에 slackclient 추가되어 있어야 함
- slak sdk 문서: https://slack.dev/python-slack-sdk/api-docs/slack_sdk/
# pip install slackclient
import slack
slack_api_token = '*'
client = slack.WebClient(token = slack_api_token)
channel_id = "*" # 슬랙 채널 정보에서 확인 가능
messages = client.conversations_history(channel=channel_id)
for message in messages['messages']:
if 'thread_ts' in message:
thread_ts = message['thread_ts']
thread_messages = client.conversations_replies(channel=channel_id, ts=thread_ts)
# 쓰레드 메시지를 처리하는 코드
# 예: print(thread_messages)
데이터 전처리
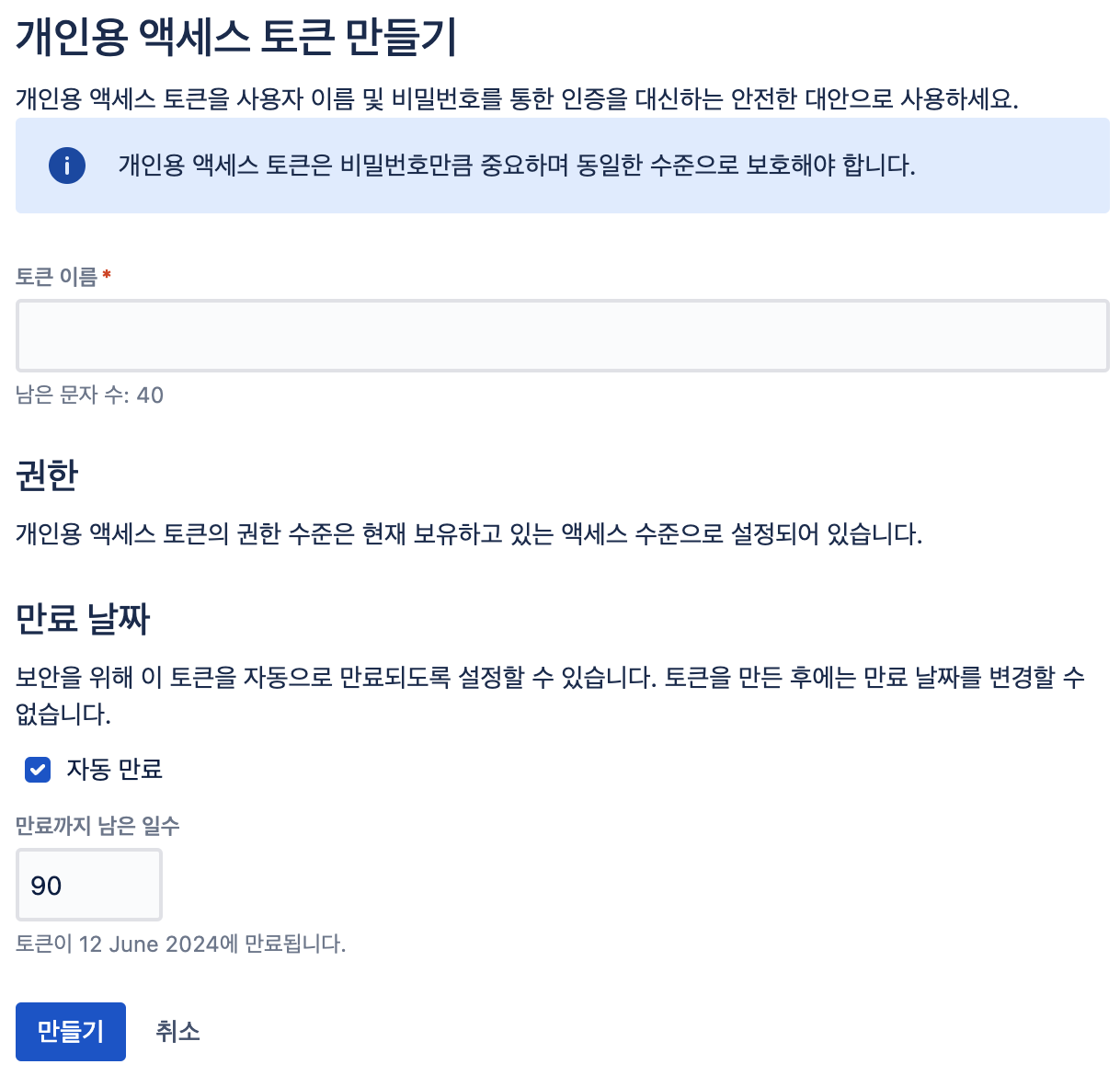
컨플루언스 API 토큰 발급
- wiki 페이지 접속 → 우측 상단 내 사진 우클릭 → 환경설정 → 개인용 액세스 토큰 → 토큰 만들기
작성하려는 컨플루언스 위키 페이지의 html 데이터 수집
- confluence rest api 사용
- API 문서: https://developer.atlassian.com/server/confluence/confluence-rest-api-examples/
- HTML 포매팅시켜서 뷰 할 수 있는 사이트: https://html.onlineviewer.net/
page_id = '*'
ctx = create_urllib3_context()
ctx.load_default_certs()
ctx.options |= 0x4
confluence_api_token = dbutils.secrets.get(scope="*", key="*")
headers = {
"Authorization": f"Bearer {confluence_api_token}",
"Content-Type": "application/json"
}
# 문서 정보 가져오기
with urllib3.PoolManager(ssl_context=ctx) as http:
response = http.request('GET', f"https://wiki.krafton.com/rest/api/content/{page_id}?expand=body.storage", headers=headers)
response.json()
# html 구조
# response.json()['body']['Storage']['value']
수집한 html 데이터를 수정
- 가능하면 파싱 & DOM 조작으로 어느정도 정형화 시키는게 좋을 것 같음
- html을 전부 입력하는 방식 & 일부만 formatting으로 수정하는 방식이 안정적인 것 같다.
데이터 전송
작성하려는 url에 POST 요청
- 위에서 작업한 html을 json으로 담아 API 엔드포인트에 요청하는 방식
- 작성하려는 문서의 상위 페이지 id를 알고 있어야 함 (ancester_id)
- 데이터브릭스에서 post 요청 시 SSL 관련 이슈가 있어 urllib3 사용
html_data = get_html()
title_text = '*'
ancester_id = '*'
json_data_prep = {
"title": title_text,
"type": "page",
"space": {
"key": "*"
},
"status": "current",
"ancestors": [
{
"id": f"{ancester_id}"
}
],
"body": {
"storage": {
"value": f"{html_data}",
"representation": "storage"
}
},
"metadata": {
"properties":{
"editor": {
"value": "v2"
}
}
}
}
json_data = json.dumps(json_data_prep)
confluence_api_token = '*'
headers = {
"Authorization": f"Bearer {confluence_api_token}",
"Content-Type": "application/json"
}
ctx = create_urllib3_context()
ctx.load_default_certs()
ctx.options |= 0x4
url = "https://*/api/content/"
with urllib3.PoolManager(ssl_context=ctx) as http:
r = http.request("POST", url = url, body = json_data, headers = headers)
post_status = r.status
page_id = json.loads(r.data.decode('utf-8'))['id']
문서 첨부파일 업로드
- 첨부파일을 업로드하려면 당연히 해당 문서가 존재해야 함 + 해당 문서의 id를 알고 있어야 함
- 업로드 코드 예시
def upload_image_to_confluence(page_id):
confluence_api_token = '*'
headers = {
"Authorization": f"Bearer {confluence_api_token}",
"Content-Type": "multipart/form-data",
"X-Atlassian-Token": "no-check"
}
ctx = create_urllib3_context()
ctx.load_default_certs()
ctx.options |= 0x4
image_path = f'./{image_name}'
image_name = f'image_temp.png'
url = f"https://*/api/content/{page_id}/child/attachment"
with urllib3.PoolManager(ssl_context=ctx) as http:
with open(image_path, 'rb') as file:
file_data = file.read()
field = RequestField(name='file', data=file_data, filename=image_name)
field.make_multipart(content_type='image/png')
fields = [field]
body, content_type = encode_multipart_formdata(fields)
headers['Content-Type'] = content_type
r = http.request('POST', url, body=body, headers=headers)
return r.status
참고 문서
구축 결과, 후기
- 자동화 가이드라고는 하지만 정작 이 가이드로 할 수 있는건 10% 정도인 것 같다.
- 수집한 데이터를 적절히 처리해서 html 구조에 넣는 작업이 90% 정도 차지했다.
- 이 작업으로 현재 두 개의 문서 작성을 자동화시키고 있는데, 아래와 같이 슬랙 알람으로 결과를 받아보고 있다.


- 확실히 비효율적인 작업을 걷어내니까 그만큼 근무 시간이 확보되었다. 끝~!