TL;DR;
- FastAPI를 사용하여 자동 요약 서비스 API를 개발하고 EC2 인스턴스에 배포
- 깃헙과 EC2 서버를 연결하여 코드를 가져오고 miniconda 설치 필요
- 깃헙 액션을 사용해 포스트 요약 생성 및 업데이트 작업 수행 가능
사이드 프로젝트 배경
- 내 블로그 포스트 대부분이 긴 흐름이라 누군가 글을 읽는다면 피로를 많이 느끼지 않을까 싶음
- 글이 긴 만큼 한 제목에 모든 내용을 담기 어려운 점도 있다
- 마침 서쿼드 스터디에서 OpenAI API 기반 서비스를 구축해보는 공부를 하면서 이런 문제를 해결할 수 있지 않을까 싶었음
- 블로그에 어떤 문서를 작성하면, 이 문서에 자동으로 요약본(TL;DR;)을 붙여서 업로드하는 요약 서비스를 만들고자 함
- 현재 내 커리어와는 거의 관련 없는, 순수하게 재미와 호기심으로만 시작한 프로젝트다 (앞으로도 관련 없지 않을까..?)
세부 기획
- 목적:
- 블로그 포스트에 OpenAPI 사용한 요약본을 자동으로 붙여주는 서비스 개발
- 내가 할 액션은 기존과 같이 포스트 작성 -> 깃헙 푸쉬만 해야함
- 방법:
- 요약 서비스 API를 만들어야 하고
- 굳이 API로 해야하는지? API를 직접 띄워보고 싶은 것이 컸는데, 하다보니 위 목적 중 최소한의 액션을 달성하기 위해선 API가 최적인 것 같음 (그 외엔 로컬에서 하는 방법이 있을 것 같은데, 수동으로 작업해야 할 부분이 많다고 판단)
- API를 계속 띄워놓을 수는 없으니, 포스트 업로드 시에만 API를 서버에 띄우는 액션이 추가됨
- API는 fastapi 사용하고, AWS EC2 인스턴스 띄워서 배포
- 위 API로 만들어낸 요약본을 포스트에 자동으로 붙이는 프로세스 구축해야 함
- 작성한 포스트를 깃헙 블로그 레포에 푸쉬한 시점 이후로 자동으로 요약본이 생성, 붙여지고, 붙여진 포스트가 다시 커밋, 머지 되어야 함
- 깃헙 서버 단에서 위 작업이 이뤄지는 것이 완전한 자동화에 가깝다고 판단, 깃헙 액션 사용 이러한 점 때문에 API를 로컬에 띄울 수 없고 EC2 기반 작업 필요함 (로컬에 띄울 시 깃헙 액션에서 API 호출 불가)
- 요약 서비스 API를 만들어야 하고
- 어떤 상황에 어떻게 동작되어야 하는지
- 새로운 포스트 업로드 시 -> 요약본 생성, 붙이기, 포스트 업데이트
- 기존 포스트 수정 시 -> 기존 요약본 수정, 포스트 업데이트
- 기존에 이미 작성한 포스트에 대해 -> 아무런 액션 없음
- 포스트에 텍스트 외의 데이터가 포함된 경우 -> 포스트 데이터에서 텍스트만 필터링
구현 과정
LLM 중 ChatGPT에 대한 이론적인 설명도 같이 들어가면 좋을텐데, 이건 내용이 길어질 것 같아 나중에 별도 포스트에서 다루겠음
1. OpenAI API 사용 준비
- OpenAI API 페이지 접속 해서 로그인
- 첫 접속이라면 OpenAI API를 사용할 수 있는 포인트를 20$ 정도 주는 것 같던데, 나는 이미 계정이 있었고, 시간이 오래돼서 만료됨
- 여러 API 중 Completion을 사용할 예정
- 결제 (필요시)
- Personal - Billing 에 들어가서 일부 금액 이미 충전해야 함 (선결제 방식임)
- 토큰 발급 (결제 후 발급받아야 유효함)
- 결제 완료 후 USER - API keys 탭에 들어가 ‘Create new secret key’ 클릭해서 API 토큰 발급 받음
- 발급 받은 토큰은 최초 1회만 표시되니, 해당 모달에서 복사 후 개인적으로 저장하는 것이 좋음
2. FastAPI 기반 요약 API 개발
- 내가 어떤 url에 json 데이터를 담아 post 요청을 보내면, 서버(백) 단에서 이 post 요청을 받아 요약 후 요약본을 반환하는 과정 필요
- 이후엔 내가 post 요청을 보내는 것이 아니라, 깃헙 서버에서 post 요청을 보내는 방식으로 업데이트 필요
import openai
from fastapi import FastAPI
from pydantic import BaseModel # pydantic은 post 메서드 사용할 때 필요
openai.api_key = "*"
def summarize(text):
system_instruction = "assistant는 user의 입력을 bullet point로 반드시 3줄 요약해준다."
messages = [{"role": "system", "content": system_instruction},
{"role": "user", "content": text}]
response = openai.ChatCompletion.create(model = 'gpt-3.5-turbo',
messages = messages)
result = response['choices'][0]['message']['content']
return result
app = FastAPI()
class InputText(BaseModel):
text: str
@app.post("/summarize")
def post_summarize(input_text: InputText):
summary = summarize(input_text.text)
return {"summary": summary}
- 백엔드에 돌릴 스크립트는 위와 같이 작성했고, 이 API를 실행하려면 터미널에 아래 구문 실행시키면 됨
uvicorn [파일명]:app --reload
- 이 API가 잘 동작하는지 swagger로 확인할 수 있음
- 띄운 서버 주소 + /docs 로 확인 가능 (ex. 로컬에 포트 8000번으로 띄웠다면, 127.0.0.1:8000/docs 이동)
- swagger 화면에서 직접 텍스트 입력해 요약되는지 확인 가능
3. AWS EC2 인스턴스에 위 API 띄우기
- AWS 계정 만듦
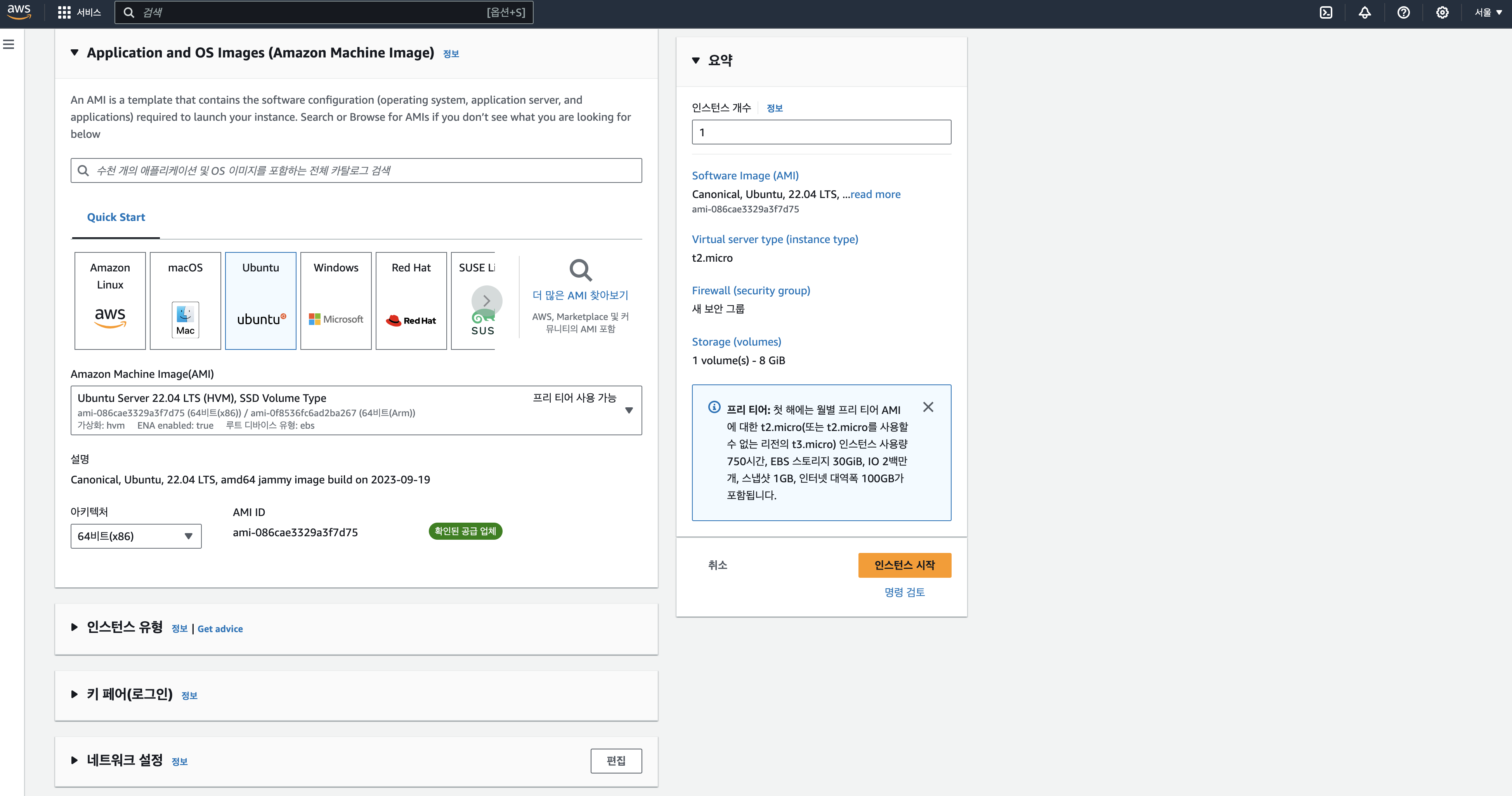
- ECS 대시보드 -> EC2 인스턴스 생성하면 위와 같은 화면 나타남
- 인스턴스 시작 전 리전을 서울로 변경 (우측 상단)
- OS는 우분투 프리티어
- 인스턴스 유형은 성능을 결정하는 것 (t2.micro 가 프리티어)
- 키 페어: 서버에 SSH 프로그램으로 원격 로그인할 때 사용되는 비밀번호. 숫자가 아닌 파일 개념
- 키 페어 유형은 RSA
- 프라이빗 키 파일 형식은 .pem
- 네트워크 설정: 외부에서 이 서버에 접근하는 것을 제한하는 항목. 지금은 그냥 놔둠
- 추후 streamlit 등에 외부에서 접근할 때 이 항목 조작 필요
- 스토리지 구성: 서버가 사용할 스토리지 설정하는 것. 프리티어는 최대 30gb
- 인스턴스 시작 하면 생성됨
- 이제 이렇게 띄운 인스턴스에 직접 접근해볼 수 있는데, SSH 로그인 가능
- pem 파일을 특정 경로에 옮김
- 이 위치로 터미널에서 이동
ssh -i fc_chatgpt.pem ubunto@43.201.66.120- 퍼블릭 주소 붙인 것
- 처음엔 에러. 퍼미션이 잘못 되었다고 함
chmod 400 fc_chatgpt.pem을 실행하면 권한이 다르게 설정됨- change mode 인 것 같고.. 400은 뭐지
- 여튼 다시 실행하면 로그인 됨
ls하면 아무것도 안 뜸pwd하면 /home/ubuntu 정도로만 뜸mkdir projects/로 프로젝트 경로 만듦
- 이렇게 띄운 가상 서버에 위에서 작업한 백엔드 스크립트를 옮기면 됨
- 단순히 복붙 보다는 스크립트 관리를 위해 git으로 작업
4. 깃헙 코드를 원격 서버에 옮기기
- 인스턴스 서버 접근를 용이하게 하려면, 아래와 같은 파일(login_aws.sh) 작성 후
- ``` #!/bin/bash
ssh -i fc_chatgpt.pem ubuntu@43.201.66.120 ```
- 이 파일에 실행 권한은 아래 코드 실행시켜서 부여 후
chmod +x login_aws.sh
- 터미널에
./login_aws.sh실행하면 간단히 EC2 서버 접속 가능함
- 깃헙 코드를 원격 서버로 가져오려면, EC2 서버와 깃헙 레포를 연결지어야 함
- 원격 서버에서 생성한 SSH를 깃헙에 등록해야 함
- 등록 후 인스턴스에서
git clone git@github.com:s-seo/fc_chatgpt.git - miniconda 설치 필요
- 설치 후
uvicorn backend_summary:app --host 0.0.0.0 --port 8000 --reload하면 아까 만든 API가 EC2 서버에서 동작하는 것- 특정 포트에서 동작하려면 포트를 외부에서 접근할 수 있게 권한 설정 필요. EC2 인스턴스 대시보드에서 설정 가능
5. 깃헙 액션 붙이기
- 먼저 깃헙 액션이란? 소프트웨어 개발 시 필요한 워크플로우가 있을텐데(예를들어 코드 커밋 시 자동으로 빌드, 테스트하고 통과하면 클라우드 서비스에 자동으로 배포까지 하는 것) 이걸 자동화하는데 사용하는 일종의 플랫폼
- 이 기능을 사용해 내 블로그 포스팅을 커밋할 때 자동으로 요약본을 붙이는 워크플로우를 자동화시킬 계획
내가 워크플로우를 만들면 위와 같은 UI로 실시간 확인할 수 있다.
- 내 깃헙 블로그 레포 내 아래 py를 작성함
- 깃헙 액션에 yml 파일을 등록해서 아래 py를 실행시키게끔 설정
- 아래 과정이 필요함
- 요약해야 하는 md 파일을 필터링하고
- 필터링한 md 파일을 아래 py의 인풋으로 넣음
- 인풋 데이터를 요약 API에 post 해서 요약본 받음
- 받은 요약본을 원래 md 파일에 붙여넣음
- 업데이트 된 md 파일을 다시 main branch에 commit, push 함
import os
import sys
import requests
import json
def summarize_file(file_path):
with open(file_path, 'r') as f:
post_content = f.read()
length = 4000
summarized_contents = []
for i in range(0, len(post_content), length):
response = requests.post('http://43.201.66.120:8000/summarize', json = {'text': post_content[i:i + length]})
summarized_contents.append(response.json()['summary'])
response = requests.post('http://43.201.66.120:8000/summarize', json = {'text': '\n'.join(summarized_contents)})
summarized_content = response.json()['summary']
front_matter, main_content = post_content.split('\n---')
with open(file_path, 'w') as f:
f.write(front_matter)
f.write("\n---\n")
f.write('TL;DR; (OpenAI API, github actions 기반 자동 요약문)')
f.write('\n***\n')
f.write(summarized_content)
f.write('\n***\n')
f.write(main_content)
if __name__ == "__main__":
changed_files = sys.argv[1].split()
print(changed_files)
for file in changed_files:
if file.endswith('.md') and 'docs/' in file:
print(file)
summarize_file(file)
= 받은 요약본을 원래 md 파일에 붙여넣을 때 위와 같이 직접 문서 포맷을 설정해야 하는데, 이 부분이 꽤나 흥미로웠다. 어떻게보면 서비스의 UI를 다루는 부분이라 볼 수 있으니까 간결한걸 좋아하는 내 성향을 잘 드러낼 수 있기 때문 아닐까
- 이제 이렇게 만든 py 파일을 워크플로우에 등록시켜야 함
- 워크플로우는 yml 파일에 기술하기 때문에 아래에 해당 py를 가져오는 부분을 확인할 수 있음
name: Auto Summarize Post
on:
push:
paths:
- 'docs/**'
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
with:
fetch-depth: 0
token: $
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: |
pip install requests
- name: Get list of changed files
id: getfile
run: |
echo "files=$(git diff --name-only $ $)" >> $GITHUB_ENV
- name: Run summarization script
run: python summarize_post.py $
- name: Commit and push if changed
run: |
git config --global user.email "baoro9394@gmail.com"
git config --global user.name "s-seo"
git add -A
git diff-index --quiet HEAD || git commit -m "Summary Added" && git push
6. QA
- 나름 일종의 서비스이기 때문에 의도한 대로 작동하는지 직접 테스트해서 개선시켜야 하는 점을 정리해봤다. (QA라고 할 수 있지 않을까..?)
| 기획 | 테스트 결과 | 액션 |
|---|---|---|
| 새로운 포스트 업로드 시 | 요약본 생성, 붙이기, 포스트 업데이트 (Done) | - OpenAI Completion API의 글자 수 제한으로 인해 4,000자로 나누어 요약 |
| 기존 포스트 수정 시 | 기존 요약본 수정, 포스트 업데이트 (No) | - 수정한 모든 포스트 인식 - 기존 요약본 확인 및 수정 필요 |
| 기존에 이미 작성한 포스트에 대해 | 아무런 액션 없음 | - 수정하지 않은 기존 포스트에 대해선 그대로 유지 |
| 포스트에 텍스트 외의 데이터가 포함된 경우 | 포스트 데이터에서 텍스트만 필터링 (No) | - 이미지 등은 GPT 모델에서 자동으로 필터링됨 |
| 요약본을 안 붙이고 싶은 경우 | 요약본 미부착 | - API 미실행 시 summary yml 에러 발생, 이메일로 에러 알림 전송 |
7. 결과
- 요약본은 성공적으로 붙여진다. 다만 요약본을 붙이기 전 수동으로 예열시켜주는 작업이 필요하다.
- 깃헙 블로그 포스팅 시 추가하는 작업
- fc_chatgpt로 터미널 생성,
./login_aws.sh실행해서 서버 접속 cd projects/fc_chatgpt로 폴더 위치한 경로로 이동uvicorn backend_summary:app --host 0.0.0.0 --port 8000 --reload로 API 뛰우기- 앤드포인트는 http://43.201.66.120:8000/
- 다시 깃헙 레포 있는 터미널로 돌아와서, 푸쉬
- 깃헙 actions에서 정상적으로 summary 붙은 것 확인 후
- 내 로컬 저장소에 다시 pull 해줘야 함 (summary는 깃헙 서버 단에서 작업한거라 로컬에는 안 붙어있음)
- fc_chatgpt로 터미널 생성,
- api 서버 끄는건 VSC 종료하면 알아서 셧다운 됨 (좀 더 건전한(?) 방법이 있을지)
- pull 안하면 로컬, 원격 버전 달라져서 문제 생김. 그 떄 마다 fetch 시켜주고 있음.. 이런 휴먼 에러의 가능성을 남겨두는게 영 찝찝하다
git fetch origin git merge origin/master
8. 프로젝트 결론 & 회고
- 재미로 시작한 것 치곤 배운게 많았음
- 그동안 API라는 개념을 뜬구름 잡듯이 알고 있었는데, 이번 스터디로 좀 더 명확히 알게된, 뜻밖의 수확(?)이 가장 큼
- 사실 API 위에 API를 감싼 형태라 수박 겉핥기 느낌으로 구현한건데, API의 앞단, 뒷단까지 내가 직접 구현해보는 개발을 해보는 것도 재밌을 것 같음
- 깃에 더 친숙해짐
- OpenAI API 비용은 아직까진 그렇게 유의미하지 않음. 만약 이 서비스를 배포한다면… 그 땐 고려해야 할 것이 훨씬 더 많아지는게 귀찮다. 그렇게까지 할 프로젝트인가 싶음 (난 사업가는 아닌 것 같다)
- 한번에 4,000자 제한을 좀 더 현명하게 해결 할 수 있을 것 같은데, 현재 구현한 방법은 아쉬운 것이 있음
- md 파일의 텍스트를 순차적으로 4,000자 씩 끊어서 요약 후 요약된 여러 말뭉치를 다시 최종 요약하는 방법
- 깃헙 액션으로 일종의 배치를 yml 구현하는 방식의 경우, 코드 수정 했을 때 결과 확인하기까지 약 3~4분 텀이 있는 것이 작업을 루즈하게 만듦
- 로컬에서 하는 방법도 있던데 시도 안 함
- API를 사용하는데서 그치지 않고 LLM을 이해해서 직접 요약 모델을 구현, 배포 해보는 것도 재밌을 것 같고, 로깅을 직접 심어서 로깅에 대한 이해를 높이는 것도 재밌을 것 같다
- 로컬에 pull 시키는 것까지 자동화시킬 수 없을까?
- 레슨런이라면…
- 실무하면서 개발자와 소통할 일이 없진 않은데, 그 사람들의 사고방식(?)을 좀 더 잘 알게 된 것 같다