데이터 사이언스는 business analysis, statistics와 data engineering의 교집합이다. 그래서인지 분석을 하다보면 분산 처리, 병렬 연산 등의 개념을 반드시 마주치게 된다. 이 기회에 저 쪽 개념을 확실히 알고자 의식의 흐름대로 이해한걸 정리해본다.
Intro
데이터 분석 공모전이나 프로젝트를 하게 되면 데이터 크기 자체가 TB를 넘어가는 일은 잘 없다. 그래서 보통 개인 노트북이나 데스크탑 등에 데이터를 저장하고 R, Python 등의 분석 프로그램에서 매번 불러와 사용한다. 그러나 TB, PB, ZB 단위의 데이터는 애초에 R, Python에서는 불러오는 것조차 버겁다. 기업의 데이터는 사이즈 자체가 매우 크니까 DB를 따로 저장, 처리할 필요가 있는데 주로 사용할 수 있는게 RDBMS(related database management system)다. 간단하게 말하면 데이터가 저장된 서버에서 데이터를 처리하는 시스템이다. 정형 데이터에 적합하고 RDBMS는 라이선스가 비싸기 때문에 수십 테라 이상의 데이터를 RDBMS에 저장하고, 처리하려면 비용이 어마무시하다. 이에 반해 하둡은 여러 대의 서버에 데이터를 저장하고, 각 서버에서 동시에 데이터를 처리하는 분산 처리를 지원하며 비정형 데이터도 다룰 수 있다.
“그럼 하둡이 어떻게 작동되길래 저런걸 할 수 있는걸까?”
1. Hadoop
- 정식 명칭은 Apache Hadoop이며 대용량 데이터를 분산 처리할 수 있는 Java 기반의 오픈 소스 프레임워크다. 2006년 Doug Cutting과 Mike Cafarella에 의해 개발되었으며 커딩의 아들이 가지고 놀던 코끼리 인형 이름에서 Hadoop이란 이름을 따왔다고 한다.

- 하둡의 두 가지 키워드는 scalable과 distributed computing이다. 하둡은 아래 두 시스템으로 구성된다고 볼 수 있다.
1-(1). HDFS(Hadoop Distributed File System)
- 분산 파일 시스템이며, 물리적으로 나눠져 있는 서버를 논리적으로 하나의 서버 형태로 구현한 파일 시스템이다. 이 때 마스터 서버를 NameNode, 슬레이브 서버를 DataNode라고한다.
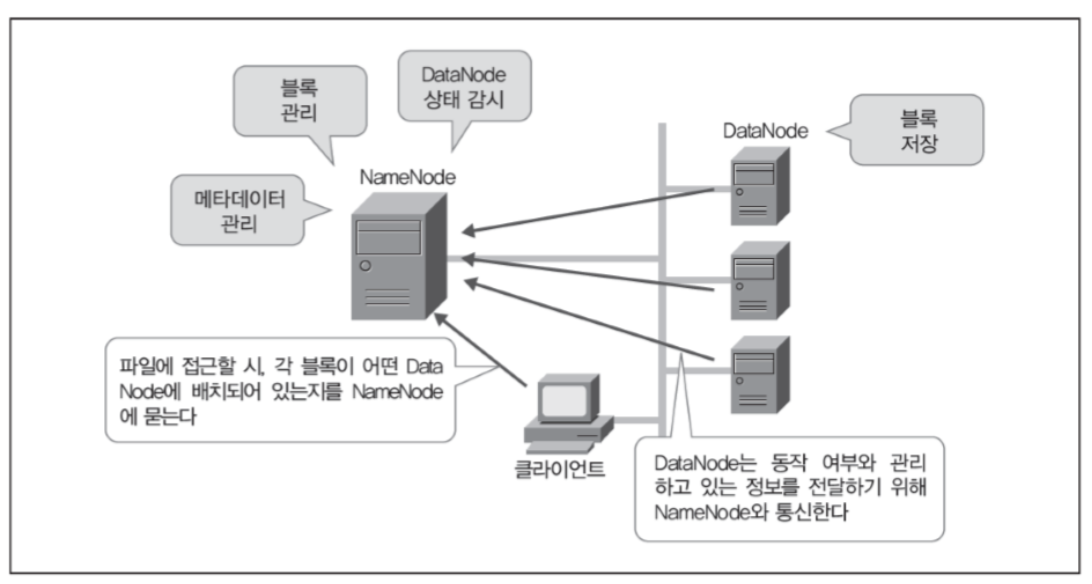
파일을 적당한 블록 사이즈(64mb, 128mb)로 나눠서 각 노드 클러스터(개별 컴퓨터)에 저장한다. 외부 시스템에서 하둡에 대용량 파일을 저장하면, 이 파일을 블록으로 쪼개서 각 블록을 서버의 로컬 디스크에 저장한다. 나중에 이 대용량 파일을 읽을 때는 여러 서버(디스크)에서 동시에 읽는다.
HDFS를 사용하는 사람은 블록이 어디에 저장되어 있는지 모른다. 엄밀히 말하면 알 필요가 없기 때문이며 이를 투과성이라고 한다. 또한 디스크 용량이 부족하면 서버를 추가(scale-out)하면 되기 때문에 확장성이 좋다. 그리고 각 블럭이 복수의 서버에 다중으로 저장되기 때문에 (replication factor를 지원한다고 함) 데이터 유실의 위험이 적어 신뢰성이 높다.
또한 NameNode를 이중화시켜서 마스터 서버 고장에 대비한다. 기존에는 NameNode와 secondary NameNode 구조를 가졌으며 두 네임노드가 동시에 다운될 경우 시스템 전체가 마비되는 Single Point Of Failure(SPOF) 문제가 있다. 이를 보완하고자 Zookeeper라는 방법을 적용했는데, NameNode 고가용성(HA, high availability?)가 가능하도록 구성한 것이다. 여러 개 NameNode 중 하나만 active고 나머지는 standby 상태로 두는 것이다.
1-(2). Mapreduce
분산 처리 시스템이며, Map 함수에서 데이터를 처리하고 Reduce 함수에서 원하는 결과값을 계산하는 프레임워크로 데이터를 병렬 처리할 수 있게 해준다.
데이터에 실행하고 싶은 처리를 Job이라고 하며, 분산 저장된 데이터에 실행되는 처리를 Task라고 한다. 즉, Job도 Task로 분배해야 하는데, 각 서버(컴퓨터)마다 성능도 다르고 오류가 발생하는 경우도 다르니까 이를 고려할 필요가 있다. 또 처리 중 서버가 고장나면 Task를 재실행해야 하고, 각 Task 처리 결과를 취합해서 출력도 해야하는데 이를 모두 자동화한 것이 Mapreduce다.
Mapreduce에선 JobTracker(마스터 서버), TaskTracker(슬레이브 서버)로 구분한다
Mapreduce 처리 흐름은 다음과 같다. 먼저 하나의 Job을 우리가 정해서 Mapreduce의 input으로 넣으면,
- Job을 Map task로 분할한다.
- HDFS로 분할된 각 블록에 Map task를 전달한다. (Map 처리)
- Map task가 각 블록을 처리하고 작업 분담을 위한 key를 부여한다. (Map 처리)
- key 별로 데이터를 정렬한다. (Shuffle)
- 모든 데이터에 Reduce task를 병행하여 데이터를 처리한다. (Reduce 처리)
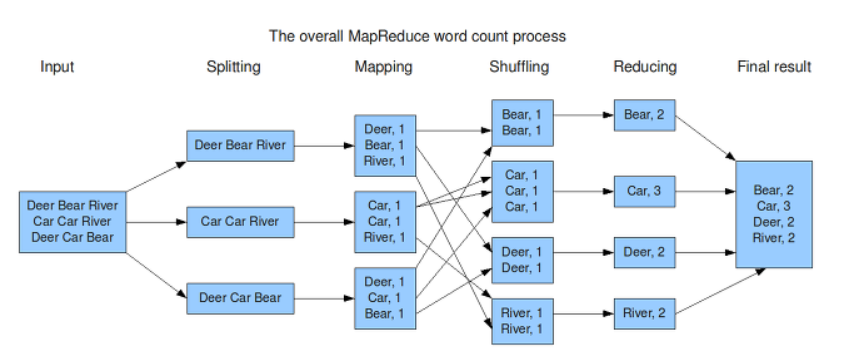
위 그림은 하둡의 word count process를 시각화한 것이다. 이러한 절차를 이해하는 것은 쉽지만 코드로 구현하는 것은 어려운데, 하둡 라이브러리의 객체를 상속받아 메서드 오버라이딩을 하고 최종적으로 구현된 클래스를 모아 jar 형태로 만들어 배치 형태로 하둡에 다시 제출해야 하기 때문이다.
1-(3). RDBMS와 비교
| RDBMS | Hadoop | |
|---|---|---|
| 데이터 크기 | 몇 TB까지는 가능하다 | PB도 가능하다 |
| 응답 시간 | 몇 초 정도 소요하기 때문에 빠르다. | 분산 처리를 위한 전처리가 필요하여 최저 10~12초의 오버헤드 발생 |
| 서버 대수와 성능 향상 | 한 대의 서버 능력을 향상시키는 scale-up | 서버를 추가함으로써 성능을 향상시키는 scale-out |
| 데이터 구조 | structered data (고정된 schema가 필요하며 데이터가 사전에 정의된 구조로 정규화되어야 함) | semi-structered data (schema가 반드시 필요하지 않고 처리 시점에 데이터 정의가 가능함) |
1-(4). Hadoop Eco System
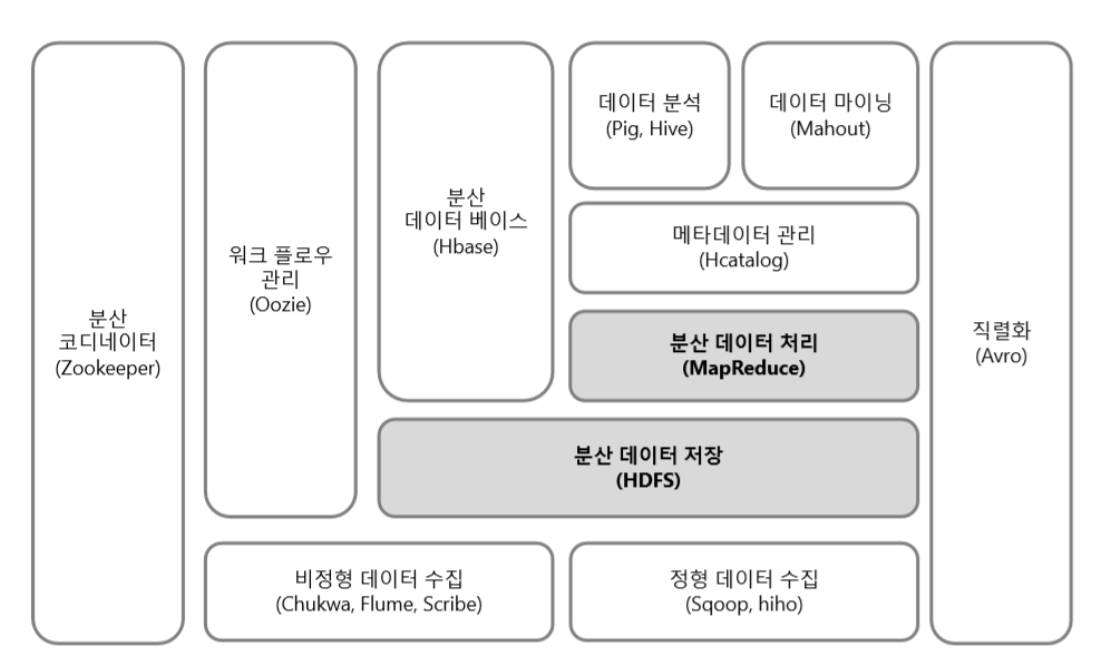
하둡에서 제공하는 일종의 확장 프로그램이라고 이해했는데, HDFS와 MapReduce는 그 중 일부라는 것이 확실하게 보인다. 각각의 개념에 대해 다뤄볼 기회가 생기면 좋겠다.
1-(5). Hadoop1의 한계
- batch에 최적화되어 있어 streaming에 약하다
- MapReduce만 지원하는데 MapReduce는 ad-hoc 데이터 분석에 적합하지 않다.
- 그 외 (JobTracker 하나에 많은 로드, Map/Reduce task 분배에서 자원 활용 문제)