이전에 작성한 Hadoop & Spark 라는 문서가 있었는데 스파크를 따로 분리해서 작성해보려고 한다. 회사에서는 스파크 기반의 플랫폼을 구축하여 DB와 분석에 사용하고 있는데 이것의 정확한 작동 원리가 궁금하다. 그래서 일단 스파크가 무엇인지, 스파크를 선언해서 자원을 가져다 쓴다는게 무슨 의미인지 파악해보자.
Spark
스파크는 통합 컴퓨팅 엔진이며, 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리 집합라고 정의할 수 있다. (스파크 완벽 가이드, 빌 체임버스)
Old post
1. Apache Spark
Hadoop의 한계로 나온 것이 Spark라고 볼 수 있다. 2009년 U.C. Berkely의 AMPLab에서 시작했다고 한다. Spark는 인메모리 기반의 대용량 데이터 고속 처리 엔진으로 범용 분산 클러스터 컴퓨팅 프레임워크다. Spark의 주요 개념은 Resilient Distributed Datasets (RDD)와 Directed Acyclic Graph (DAG) execution engine이다.
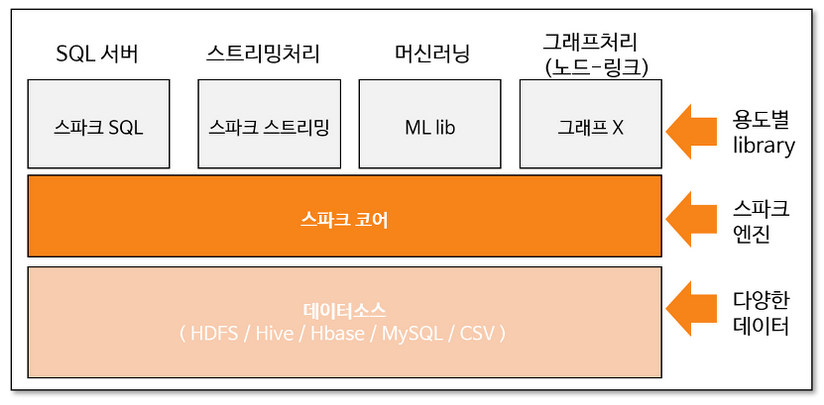
위 그림은 Spark의 프레임워크를 시각화한 것이다. 흔히 Spark를 하둡과 연계하여 HDFS에서 데이터 소스를 가져오지만, 직접 DBMS로부터 조회하거나, CSV를 호출하는 것도 가능하다. 또한 Spark engine을 사용해서 SQL, ML, streaming, Graph analysis의 분석을 할 수 있다.
ETL(Extract, Transform, Load)은 정제되지 않은 데이터를 분석에 용이한 형태로 가공하는 일련의 과정이다. Data sources에서 data warehouse로 탈바꿈시키는 과정을 일컫는다. Spark는 이 중 load 정도만 담당하고, load된 데이터를 분석할 수 있다. E,T는 하둡 프레임워크에서 담당한다. Spark 프레임워크에서 데이터 처리 방법론은 다음과 같다.
- Data source로부터 데이터를 호출하여 RDD화 한다.
- Transformation: 수행하고 싶은 operation으로 RDD tranformation
- Action
Spark의 특징 중 하나는 lazy excution인데, transformation 단계가 아닌 action 단계에서 데이터를 호출해서 작업을 처리하기 때문에 효율적이다.
1-(1). Resilient Distributed Datasets (RDD)
RDD는 Spark에서 사용하는 데이터 형태다. 여러 분산 노드에 저장되는 변경 불가능한 데이터의 집합이다. 현재는 RDD의 단점을 보완한 Dataset, DataFrame이 나왔다.
- Resilient: 분산되어 있는 데이터에 오류가 발생해도 자동적으로 복구할 수 있음
- Distributed: 클러스터의 여러 노드에 데이터를 분산시켜 저장
- Dataset: 분산된 데이터의 모음
두 가지 작업만을 지원한다.
- Transformation: 새로운 RDD 데이터를 생성
- Action: RDD를 처리
1-(2). Directed Acyclic Graph (DAG) execution engine
Spark의 scheduling을 담당한다. 어느 작업이 어떤 노드에서 어떤 순서로 실행되는지 결정한다. MapReduce의 느린 부분을 제거한 엔진이다.
1-(3). Hadoop과의 비교
Spark는 In-Memory data engine을 통해 MapReduce 보다 100배 더 빠르게 작업을 수행할 수 있다.
또한 Spark는 다양한 언어를 지원하기 때문에 개발화 친화적이라는 점에서 하둡보다 유용하다.
Spark에서는 하둡의 분산 처리 엔진이 갖는 복잡함을 간단한 메서드 호출로 커버한다. 예를 들어 word count process는 MapReduce에서는 50줄이 필요하지만 Spark에서는 몇 줄로 줄일 수 있다.
하둡은 HDFS와 MapReduce를 사용하기 때문에 Spark가 반드시 필요하지는 않다. Spark도 HDFS 외 다른 클라우드 기반 데이터 플랫폼과 융합될 수 있어 하둡이 반드시 필요하지는 않다.
하둡은 매번 Job의 결과를 디스크에 기록하기 때문에 HDFS나 MapReduce 과정에서 오류가 나더라도 결과를 활용할 수 있고, Spark는 RDD를 사용하기 때문에 오류가 나도 완벽하게 복구할 수 있다. 방식만 다를 뿐 둘 다 오류에 강건한 프레임워크다.
하둡은 데이터 일괄 처리를 최우선으로 하고, PB 데이터를 저렴하게 저장, 처리할 수 있다. Spark는 streaming data로의 전환이 용이하다.
1-(4). 특징
Speed: In-Memory 기반의 빠른 처리
Ease of Use: 다양한 언어(Java, Python, R, SQL 등)를 지원 다양한 언어를 지원하지만 언어마다 처리 속도가 다르다. Scalar가 가장 빠르다.
Generality: SQL, streaming, ML, 그래프 연산 등 다양한 기능 지원 Spark라는 단일 시스템에서 Spark SQL, Spark streaming, MLib, GraphX 등 다양한 분석을 할 수 있다는 것
Run everywhere: 다양한 클러스터(YARN, Mesos, Kubernetes 등)에서 동작 가능하며 다양한 파일 포맷(HDFS, Casandra, HBase 등) 지원