교수님께 드리는 보고서를 그대로 가져왔기 때문에 구어체인 점 양해 부탁드립니다.
1. ETS의 computerized adaptive testing (CAT)
Way, W. D., et al. “Some considerations related to the use of adaptive testing for the common core assessments.” *Retrieved June 11 (2010): 2010.*
- ETS, Pearson에서 공동으로 낸 CAT에 대한 개론 형식(설명, 장단점 등)의 보고서입니다.
Davey, Tim. “A Guide to Computer Adaptive Testing Systems.” Council of Chief State School Officers (2011).
- 2011년에 ETS에서 직접 CAT 방식에 대해 정리한 것으로 question pool, question selection, question adiministration, scoring and score properties으로 파트를 나눠 설명하고 있으나 일반적인 CAT 설명과 크게 다르지 않습니다.
- 특이한 점은 글의 목적이 buyer’s guide라서 CAT을 도입하는데 있어 실제 나올법한 질문에 대한 대략적인 답을 같이 제공합니다. (ex. . What are the statistical characteristics of reported scores?)
Linacre, John Michael. *Computer-adaptive testing: A methodology whose time has come. No. 69. MESA memorandum, 2000.*
Seo, Dong Gi. “Overview and current management of computerized adaptive testing in licensing/certification examinations.” *Journal of educational evaluation for health professions 14 (2017).*
위 두 보고서가 CAT에 대해 설명이 잘 되어 있어서 이를 요약한 것 입니다.
1960년부터 Classical test theory(CTT)의 주요 가정 중 하나인 parallel test assumption에 대한 한계를 보완하려는 시도가 있었고 1970년 들어서 item response theory(IRT)가 invariance properties (test-independence, sample-independence)를 만족하면서 각광받았습니다. IRT의 특징은 다음과 같습니다. (이론은 뒷부분에서 다루겠습니다)
- possible to compare candidates on the same scale
- compute the test information function (TIF)
- requires large item bank
CAT is also known as tailored testing
Def: the test’s difficulty adapts to the performance of the candidate, getting harder or easier following a correct or incorrect answer respectively
Step:
- The pool of available items is searched for the optimal item, based on the current estimate of the examinee’s ability
- The chosen item is presented to the examinee, who then answers it correctly or incorrectly
- The ability estimate is updated, based upon all prior answers
- Steps 1–3 are repeated until a termination criterion is met
Ex: Graduate Management Admission Test (GMAT), GRE,
Pros and Cons
Pros Cons 1. Quicker
2. More accurate measurement of individuals
3. More fair
4. More Secure
5. Better support the measurement of growth over time
6. Better for high and low performers1. not produce tests that are equated in the strictest statistical sense
2. the expensiveness of the large item pool
2. Review of past items is generally disallowed
3. time limited CAT is unfair
4. Hard to catch the extremly high and low performersHow to: Technical components in building a CAT
- calibarated item pool: 방대한 양의 문제은행 필요
- starting point or entry level: 응시자가 치를 첫번째 문제는 어떻게 선정?
- item selection algorithm: n번째 문제를 맞추거나 틀렸을 때 n+1번째 문제는 어떤걸로 내야?
- scoring procedure: examinee’s ability level을 추정해야함. priori를 부여하고 score는 likelihood로 넣어서 MAP를 구하는 bayesian estimation. 또는 그냥 MLE 구할 수도 있다
- termination criterion: 언제까지 문제 낼건지? 단순히 문제 은행 소진될 때 까지 or standard error of measurement가 일정 기준 이하로 내려가면 (즉, 점수에 큰 변동이 없을 때)
2. ETS의 CAT 적용 사례
2-(1). GRE
- section adaptive 방식을 사용해서 문제 단위가 아닌 section 단위를 adaptive하게 제시합니다. 예를 들어 first measure(section)에서 많이 맞췄다면, second measure에선 약간 더 어려운 문제들이 출제됩니다. Question adaptive는 old GRE에서 사용한 방식입니다.
- More difficulty, higher score: 예를 들어, first measure에서 10/20(20개 중 10개)를 맞추고, second measure에서 20/20을 맞춘 사람에 비해, first measure에서 18/20을 맞추고, second measure에서 12/20을 맞춘 사람의 점수가 더 높습니다. 후자의 경우 second measure에서 더 challenging한 문제를 풀었기 때문에 이를 고려하여 더 높은 점수를 매기지만 하지만 이러한 차이가 critical하지 않기 때문에 어디까지나 문제를 몇 개 더 맞췄는지가 중요합니다.
- Score equating:
- Equating 필요성? 매번 GRE를 치를 때 마다 난이도가 달라질 수 있는데, 그럼에도 불구하고 robust하게 공정한 점수를 매겨야하기 때문입니다. so equating ensures that average scores stay consistent across different versions of the test.
- ETS에서 scoring 관련 exact process를 공개하지 않았지만, 대략적인 방식은 다음과 같습니다.
- verbal section (V), quantitative section (Q), analytical writing (A) 세 부분으로 나뉘어지고
- V, Q의 경우 각 40문제씩 있고 기본 점수로 130점을 주기 때문에 130~170점 사이의 점수를 획득합니다. 이 때 풀었던 문제의 난이도에 따라 약간의 변동을 부여합니다. (30/40을 맞췄는데 좀 어려운 문제가 많았다면 130+30+3=163을 매김) 그러나 그 변동은 minor하다고 합니다.
- A는 0부터 6까지 점수를 trained grader & e-reader가 매깁니다.
- 참고
2-(2). TOEFL, TOEIC 외
- 모두 CAT 방식을 사용하지 않으며, 채점 방식은 item respond theory(IRT)의 Rasch 모형, 3PLM을 사용한다는 공통점이 있습니다
- TOEFL의 경우 이전의 CBT (computer-based test)와 현재 iBT (internet-based test) 모두 CAT 방식이 아닌 Linear 방식을 사용하고 scoring procedure 역시 both electronic and human assessment를 사용합니다.
ETS에서는 이미 오래전부터 IRT와 CAT을 접목하려는 시도가 있었으나(Graphical Models and ComputerizedAdaptive Testing, 1998), GRE, TOEFL 등 대표적인 시험에선 가장 기본적인 형태만 사용합니다. 결론적으로 ETS에서 CAT 방식을 적극적으로 사용하지 않고, 현재까지 찾아본 바로는 분야 불문하고 아직까지 정교한 CAT 방식(MAP, bayesian updating, VI 등)을 실제로 적용한 사례는 거의 없는 것 같습니다.
Almond, Russell G., and Robert J. Mislevy. “Graphical models and computerized adaptive testing.” *Applied Psychological Measurement 23.3 (1999): 223-237.*
- 위 내용을 다룬 보고서인데, ETS에서 왜 IRT-CAT을 적용하기 어려운지에 대한 현실적인 논의를 잘 다뤘습니다.
3. Scoring procedure in CAT
3-(1). Bayesian method
Bayesian CAT에서는 prior beliefs와 observed data를 사용해 item and person parameters에 대한 추정을 동시에 합니다. 따라서 linear testing보다 cost가 낮다는 것이 장점 중 하나입니다. 업데이트해야하는 parameters는 주로 IRT의 3 parameter logistic model을 사용합니다.
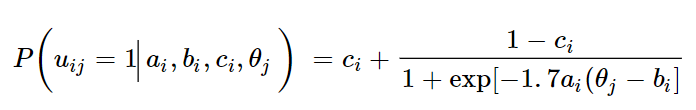
이 IRT 모델을 기반으로 아래와 같이 theta를 추정할 수 있습니다.
Seo, Dong Gi, and David J. Weiss. “Best design for multidimensional computerized adaptive testing with the bifactor model.” *Educational and Psychological Measurement 75.6 (2015): 954-978.*
- 위 방식은 단순 MLE를 사용한 것으로, 베이지안 추정과 관련된 논문은 아래에 정리했습니다.
Owen, Roger J. “A Bayesian sequential procedure for quantal response in the context of adaptive mental testing.” *Journal of the American Statistical Association 70.350 (1975): 351-356.*
- Bayesian adaptive testing strategy의 뿌리에 해당하는 논문입니다.
Weiss, David J., and James R. McBride. “Bias and information of Bayesian adaptive testing.” *Applied Psychological Measurement 8.3 (1984): 273-285.*
- 개인의 ability를 theta로 두고 이를 베이지안으로 추정한 논문입니다. (Owen, 1975) 논문을 bias of estimates 등의 측면에서 심화적으로 분석한 것 입니다. 결론적으로는 (Owen, 1975)는 theta의 prior 값에 영향 받음을 증명했습니다.
van der Linden, Wim J. “Bayesian item selection criteria for adaptive testing.” *Psychometrika 63.2 (1998): 201-216.*
- 기존 Owen, 1975 논문이 가진 normal approximation of true posterior 한계를 computing power로 극복한 논문입니다.
Veldkamp, Bernard P. “Bayesian Item Selection in Constrained Adaptive Testing Using Shadow Tests.” *Psicologica: International Journal of Methodology and Experimental Psychology 31.1 (2010): 149-169.*
- item selection의 대표적인 기준인 maximum Fisher information과 이것의 보완책으로 나온 이론(Veerkamp & Berger (1997), Chang & Ying (1996))의 한계를 짚고, 이를 bayesian alternatives로 극복하고자 한 논문입니다.
- ability parameter에 대한 베이지안 추정이 잘 나와있어 인용했습니다.
Veldkamp, Bernard P., and Mariagiulia Matteucci. “Bayesian computerized adaptive testing.” *Ensaio: Avaliação e Políticas Públicas em Educação 21.78 (2013): 57-82.*
- empirical prior를 사용한 bayesian CAT을 설명하면서, 이것이 estimation efficiency, quality of information 측면에서 어떤 장점을 가지는지 등에 대해 논하고 있습니다.
Plajner, Martin. “Probabilistic Models for Computerized Adaptive Testing.” *arXiv preprint arXiv:1703.09794 (2017).*
- CAT을 Bayesian network에서 접근한 논문입니다.
3-(2). VI
Chang, Hua-Hua, and Zhiliang Ying. “A global information approach to computerized adaptive testing.” *Applied Psychological Measurement 20.3 (1996): 213-229.*
- 위 논문에서 Kullback-Leibler information을 CAT에 적용한 시도가 있었고
Natesan, Prathiba, et al. “Bayesian prior choice in IRT estimation using MCMC and variational Bayes.” *Frontiers in psychology 7 (2016): 1422.*
- IRT parameter estimation에 MCMC, Variational Bayes를 적용하여 기존의 marginal maximum likelihood를 사용한 추정과 비교한 것 입니다.
3-(3). Data integration
Score linking, score equating 과 연관지어서 볼 수 있습니다. 이 분야는 기존의 IRT - CAT과 다른데, IRT-CAT의 강력한 특징 중 하나는 몇가지 조건만 만족시키면 score equating이 따로 필요없다는 것 입니다.
- If a candidate’s ability and the item’s difficulty parameters are placed on an identical scale, equating can be performed without any assumptions about candidate score distributions. This property makes it possible to compare candidates on the same scale even if measurements are made of different groups and with different tests
4. 기타
A Bayesian Method for the Detection of Item Preknowledge in Computerized Adaptive Testing
- ETS에서 1999년에 CAT과 bayesian을 연관시킨 보고서인데 접근할 수 없습니다.
Computerized Adaptive Testing: The Concept and Its Potentials
- ETS에서 1977년에 이미 CAT을 인식하고 도입할 준비를 했었고
The TOEFL Computerized Placement Test: Adaptive Conventional Measurement
- 1989년에 TOEFL에 CAT을 적용하려는 시도를 했었던 것 같습니다.
베이지안 접근법이 주로 논의된 부분은 item selection입니다. Scoring procedure에서 bayesian을 사용할 수 있다는 아이디어는 item selection에서 비롯된 것인데, 다음 문제를 선택할 때 기준이 highest information이고, 이 때 fisher information을 계산하는데 여기에 필요한 likelihood function이 주어진다. 이 likelihood function은 true ability parameter인 theta에 대한 함수인데, 3PL에선 이 함수가 3개 parameters의 조건부 형태로 나타난다고 본다. 즉, 이러한 conditional likelihood function을 사용해서 역으로 ability에 대한 추론을 베이지안으로 할 수 있다고 말하는 것 같다. (인용한 논문 2편에는 관련된 scoring procedure와 bayesian approach를 직접적으로 다루는 내용이 안나온다.)