강의 링크: PM을 위한 데이터 리터러시
수강 목적
- IT 회사에서 데이터 분석가로 일하고 있지만, 단순히 통계만 알아선 일하는데 한계가 있었고, 그동안 주먹구구식으로 배웠던 개념들을 확실히 다잡고 싶음 (리터러시, 퍼널, 코호트, 로그 설계 및 QA, 매트릭 등)
- Product Data Analyst 또는 Data PM으로의 역량을 키우고자
- 여기서 배운 것을 업무에 적용해보는 것 (더 나은 로그 QA, 더 나은 지표 설계 등)
모든 제품, 서비스는 고객의 문제를 해결하기 위한 것. 이런 관점에서,
- 고객은 왜 우리 제품을 사용해야 하는가?
- 우리 제품의 어떤 것이 매력적인가?
PMF (Product Market Fit)
- 실리콘 밸리 유명한 VC 투자자가 만든 개념이라는데, 제품을 만들기 전 가장 먼저 체크해야 할 것의 모음으로 보임
- 타겟 유저와 그 유저군의 수요, 현재 보유한 대안, MVP 제작 및 테스트 등 일련의 과정을 통해 PMF를 확인한다고 함
- 분석가가 이걸 알아야 하는 이유? 는 딱히 없지만, 조직의 일원으로서 좋은 제품, 비즈니스가 없다면 데이터 분석이 아직은 시기상조 임을 인지하는데 필요함. 즉 이런 경우엔 분석이 아닌 PMF가 필요하다~ 그러니 도망치자~ 라고 결론 내릴 수 있는 것
AHA Moment
- 고객이 제품의 핵심 가치를 처음 경험하는 순간
- 이 지표를 찾는 것도 결국 제품의 가치를 잘 ‘전달’하려는 것에 대한 고민이니까
- 본질부터 고민하는 것
- 다만 강사가 짚은 것처럼, ‘어떤 기능을 경험한 사람이 리텐션이 높지?’라는 것을 기계적으로 찾기 보단, 제품이 근본적으로 전달하려는 가치를 고민하는 것이 필요함
- 이걸 찾으면 뭘 하냐? 계속된 문제 해결. 반복적인 문제 해결을 통해 고객의 일상이 되는 것. 습관화가 목적
습관화를 데이터 사용해서 정량적으로 파악하기 = 가설 검정
- 유저가 실제로 자주 접속, 기능을 사용해서 제품을 계속 사용하는지?
- 특정 기능을 통해 습관을 형성하려 했는데, 기능이 런칭된 후 리텐션이 높아졌는지?
회사의 방향을 크게 두가지로 볼 수 있음: 계획, 전략
- 계획은 주로 예산, 비용 계획 등 통제할 수 있는 영역으로 비용 감소가 목적인 경우가 많음
- 전략은 미래의 outcome과 관련있으며 대부분 통제 불가능한 불확실성을 다루는 영역. 매출 증가, 리텐션 증가 등이 목적
BM
- 매출 뿐만 아니라 비용 구조도 생각해보면 좋다고 함. 근데 매출보다 비용 구조를 알기 더 어려운 것 같음
- Unit Economics: 가치를 창출하는 최소 단위라고 하며 예를 들어 배달 주문 1건과 같은 것이 있음.
주요 기능(Feature)의 히스토리
- 기능 개발 이유 및 개발 성과
- Release Note: 서비스 출시, 업데이트 할 때 마다 변경 사항, 기능 추가/삭제, 버그 개선 등을 정리해 제공하는 문서
- 현재 회사에선 이게 파편화 되어 있음. 이해 관계자들이 편한 방식이겠지만 나같은 외부인은 보기 어렵다는 점. 오히려 이런걸 노린건가..?
제품 개발 프로세스
- 어떤 업무 프로세스로 제품, 개발 조직이 진행되는지? 데일리 / 스프린트 / 회고
- 목적 조직 / 기능 조직인지? 기능이면 어떤 때 협업을 하는지?
- 현재 회사의 데이터 조직은 기능 조직. 협업은 주로 신규 피쳐 개발 시 기획, 디자인, 개발, 분석가 등이 참여함
- 어떻게 기획이 구체화되는지? PM이 처음 생각하는 경우도 있고, 운영이나 사업에서 처음 생각할 수도 있고, C레벨에서 생각 후 top-down으로 구체화되는 경우도 있음
- 이런 방식이 있구나라는 것도 알 수 있어 재밌음
데이터 4대장의 하나로서 데이터 분석가의 역할
- 단순히 ‘데이터 요청하면 추출’일 경우, 데이터 잘 활용하지 못하는 것
- 분석가가 현업과 많은 의견 주고받고, 실제 action item을 만드는 것이 핵심
- 이 부분에서 약간 양심의 가책을 느낌…
데이터 웨어하우스
- 데이터를 중앙으로 모은 것.
- 서비스 DB와 구분지은 것인데, 여기 있는 데이터를 거의 그대로 데이터 웨어하우스에 옮김
- 웨어하우스에서만 분석하기 때문에 쿼리한다고 해서 서비스에 영향 미치지 않음
- 데이터가 배치로 동기화되는지
Product Analytics Tool로서 GA4
- 워낙 언급이 많아서 어떤 것인지 궁금
- 쿼리 없이도 웹 화면에서 데이터 조회 가능. 누구나 접근 가능
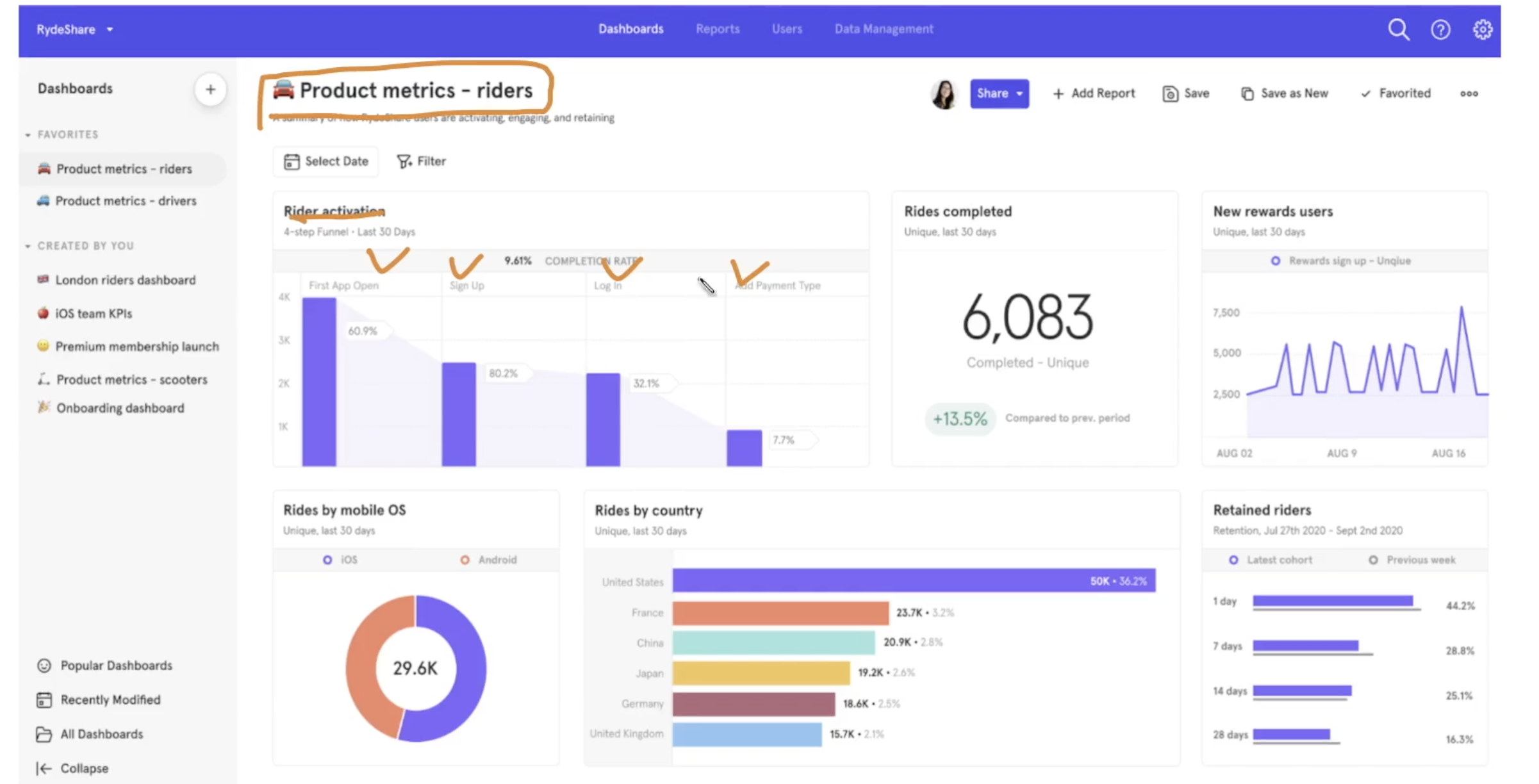
- GA4는 아니지만, 위와 같은 느낌이라면 looker와 비슷해 보임
데이터 이벤트 taxonomy, tracking plan
- 이벤트 로그 설계를 정리한 문서
- 프론트 로그 정리한 문서. 이걸 ‘이벤트 taxonomy’와 같이 표현하는구나
Push Solution
- 이 개념 자체는 관심 없는데, 업무하다 보면 braze 용어가 자주 들림. 이게 push solution의 대표적인 것이었음
- 마케팅 자동화 & 인앱 솔루션
강사가 정의한, 데이터로 할 수 있는 것 (나중에 포트폴리오에 참고할 수 있을 것 같아서)
- 현상을 이해하고 패턴을 찾을 수 있음
- 서비스의 핵심 지표 정의 후 성장성 확인
- 매출 증가
- 비용 감소
- 데이터 기반 의사결정, 업무 자동화
- 머신러닝, AI 모델 개발
의사 결정에는 직관 기반, 데이터 기반 두가지 방식이 있음
- 직관 기반: 일명 휴리스틱. 수많은 bias에 빠질 위험이 있음
- 데이터 기반: MVP 이후 데이터 쌓이는 시점부터 가능. 여기서도 bias는 존재하며 지표를 hacking 할 수 있음
- 이 수치를 올리기 위해, 제품 자체를 개선하는게 아닌 어떤 행동을 하는 것 (예를 들어 자극적인 푸시 메시지를 보내서 푸시 메시지를 더 많이 보게 많드는 것)
- 강사는 action이 성공할 확률을 높이는 것이 핵심이라면서, 직관 + 데이터 두개를 섞어야 한다고 함
- 데이터 기반만 강조할 줄 알았는데, 어찌보면 직관은 인간이 쌓아올린 수십년의 모델인 셈이니…
데이터 관련 여러 생각 (같이 생각해보면 좋을 것 같아서)
- 데이터에 답이 있다
- 데이터에 기반한 의사결정은 항상 좋은 선택일 것이다
- Local Optima, Global Optima라는 미적분 개념을 차용한게 인상적
- 정답은 하나다
- 데이터 분석은 데이터팀이 해야지
- 내 데이터, 가설이 틀릴 수 있다
데이터 리터러시
- 데이터 문해력, 데이터를 읽는 역량
- 직군 관계없이 모든 곳에서 필요한 역량
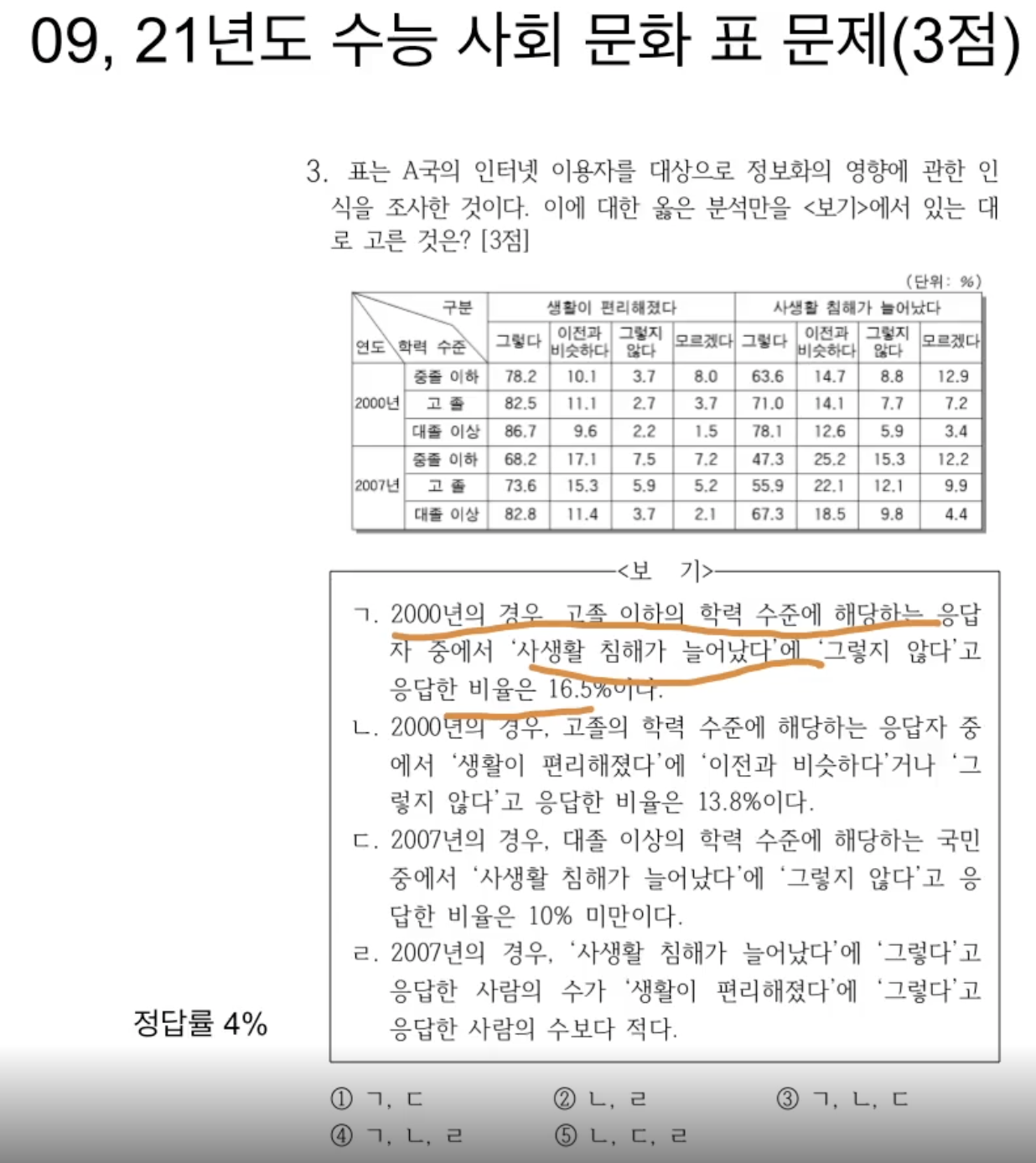
- 이것도 데이터 리터러시를 확인하는 문제다..! 생각지도 못했었는데 등잔 밑이 어둡다더니
- PM, PO 관점에선 방법론을 이해하는 것보단 데이터를 어떻게 해석하고 의사결정을 내릴까에 초점 맞추는 것이 수월 <- 분석가로서 방법론을 잘 전달하는게 중요하다 생각했는데 그렇게 안 중요한 것 같음. 앞으로는 리터러시 쪽을 중점적으로 고려해서 전달하는 시도를 해볼 것
- 분석가로서, 내 방법론에 딴지를 걸어주는게 사실 제일 열 받으면서 신나긴 함. 근데 잘 안 그래줌. 이유는 다들 이 ‘데이터 리터러시’가 있어서 어떻게 해석하고, 어떤 의사결정 내릴지에 혈안이 되어 있었기 때문. 멋진 사람들이었네
문제 정의
- 현재 상황과 바라는 상황과의 괴리 = 문제
- 이렇게 정의할 수 있다는 것이 신기
- 문제 정의 프레임워크: MECE, Logic Tree, So What? Why So?
- 이건 진짜 PM 쪽 역량. 일단 패스함
- PDA, DPM 쪽 직군 생각하고 있으니, 이걸 기반으로 사이드 프로젝트 삼아서 내가 직접 문제 정의, 구체화, 해결 등을 해볼 수 있지 않을까?
지표 정의
- 관련 용어: KPI(Key Performance Indicator), NSM(Notrh Star Metric), OMTM(One Metric That Matters) 뒤 두개는 처음 들어서 적어봄
- 새로운 의미의 KPI: Keep People Interested, Inspired
- 지표 종류: Input Metric / Output Metric
- 아웃풋은 어떤 것의 결과가 되는 지표 (매출, DAU 등). 어떤 것이 원인인지 파악하기 어려움
- 인풋은 아웃풋 메트릭을 구성함. 이걸 개선해야 아웃풋도 개선됨.
- 예시: 인풋은 결제 전환율, 아웃풋은 매출
- 프로젝트 성공과 관련된 지표: Primary Metric / Secondary Metric / Guardrail Metric
- 이 중 가드레일은 떨어지면 안되는 지표
- 예를 들어 신규 피쳐가 전체적인 서비스에 악영향을 주었는지 파악하는 것 등
- 피쳐 단위로 팀 꾸릴 때 있는데, 이 때 봐야하는 지표로 저 세가지 틀을 제시하면 좋을 것 같음
지표 구성 요소: 시간축
- Flow / Stock 두가지가 있음
- 전자는 일정 기간 동안을 집계하는 것, 후자는 특정 시점에서 집계하는 것
- 현재 쌓고 있는 테이블 중 하나가 ~flow~인데 생각나서 적어봄. 근데 이 테이블에 쓰인 flow와 시간축으로서의 flow는 다른 의미인 것 같음
- 각각 유량 / 저량 이라고 함
퍼널
- 퍼널 개선은 뒤에서 앞으로 개선하는 것이 좋음
- 결제 화면 -> 결제 완료로 가는 전환율을 높여야 매출로 직결되니
- AARRR, RARRA: 후자는 리텐션을 강조한 버전
리텐션
- 서비스를 사용한 사람이 다시 사용하는 비율
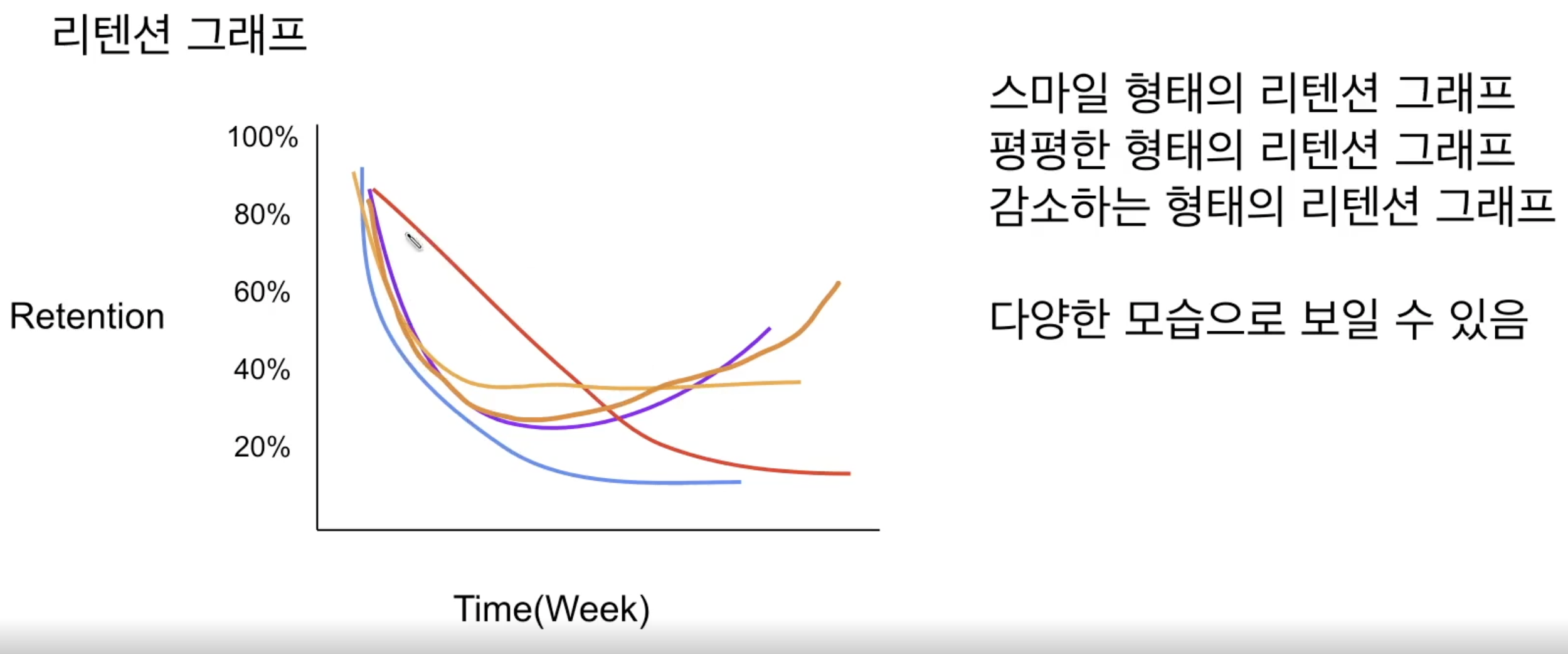
- 가로축은 서비스 출시 일자 정도로 생각하면 됨. 점점 리텐션이 증가하는 형태가 가장 이상적
- PMF를 찾았으면 리텐션 그래프가 보통 평평함
- 리텐션은 면적 관점으로 생각하는 것이 좋음
코호트
- 통계 용어(주로 의학 통계에서 특정 성질 공유하는 집단을 의미)로 자주 접했는데, 리텐션과 연관지어 쓰일 땐 다소 의미가 달랐음
- 가입일자 기준으로 종종 파악하며, 가입한지 몇주가 될 때까지 남아있는가? 등에 사용
- 보통 히트맵으로 나타냄
- 특정 기간에 접속한 사람들의 n주차별 리텐션
- 서비스 사용 주기에 따라 리텐션 그래프 길게 볼 필요 있음 (1년에 한 번 사용하는 서비스면 리텐션 최소 1년은 잡아야 함)
- 리텐션이 높은 segment가 있는지 파악하는 것이 중요
지표 정의 process
- 신규 기능 도입 시 팀 꾸릴 때, 어떤 지표를 봐야할지 논의하는 경우가 있음. 이 때 이런 방식으로 논의 이끌어가면 좋을 것 같아 정리함
- 전후 비교
- 새로운 기능인 경우, ‘후’ 데이터가 없으니 A/B test를 주로 사용함
- 메인으로 하나, 나머지는 보조로 선택하는 것이 좋음
- 기능을 기획한 사람이 선정하는 것이 의도에 부합한 지표를 선정할 수 있음
로그 설계
- 하나하나 다 공감돼서 그냥 캡쳐 땄음..

데이터 기초 지식
- DB 데이터 / 사용자 행동 데이터
- 각각 백로그 / 프론트로그라고 하기도 함
- 전자는 서비스가 운영되기 위해 필요한 데이터로, 분석이 목적은 아님
- 후자는 더 좋은 제품을 만들기 위한 인사이트가 목적인 데이터
- 전자는 서비스에서 고객에게 보여지는 데이터
- 후자는 고객에게 보여줄 필요가 없는 데이터
- 데이터 저장소
- DB에 저장하는 방식 vs 파일로 저장하는 방식 (이렇게는 생각 못했어서 인상적)
- 전자는 쿼리로 바로 확인 가능하나 DB에 부하 걸림
- 후자는 데이터 파이프라인을 구축해야 함. DB에 부하는 안 줌
- DB와 데이터 웨어하우스? 전자는 서비스 운영을 위한 것으로 OLTP(온라인 트랜잭션 처리) 특화이며, 후자는 데이터 분석을 위한 것으로 OLAP(온라인 분석 처리)에 특화됨
- 추가로, NoSQL: 비관계형 DB. 엑셀 표 같이 저장되는 RDBMS와 다르게 key-value로 구성됨
- 유저 행동 로그는 결국 데이터 엔지니어 통해서 ETL 파이프라인 타야 분석가한테 도달한다는 것.
- 근데 그동안 백엔드에서 개발한 로그를 별도 엔지니어링 없이 분석가 도달했던 것은? 이미 파이프라인 구축했기 때문에 자동으로 ETL 되는 것으로 추정됨
로그 설계 process
- 로깅의 핵심: 이벤트를 정의하고, 유저 정보를 기록하는 것에 있음
- Event Parameter: 이벤트의 정보
- event: click, view, swipe, custom event
- trigger: 예를 들어 유저가 특정 행동을 하는 경우, 특정 화면이 보이는 경우, 클라에서 서버에 request하는 시점 등
- state: 어떤 상태를 가지는지, 예를 들어 어떤 화면인지, 어떤 버튼을 클릭했는지, 그 당시 클릭한 제품 id 등을 이벤트 파라미터에 기록
- User Property: 유저가 특정 이벤트 하는 시점의 유저 정보
- 유저의 서비스 가입일을 이벤트 실행 시점에 같이 기록한다는 등
- 접속한 위치도 바뀔 수 있어 같이 심는 경우 있음
- DB의 유저 테이블과 비슷한데, 이벤트 시점의 데이터(스냅샷)를 남긴다는 차이가 있음
- 이건 로그 설계 필요 없음.
- 프론트, 백 개발을 몰라 어떤 로그를 심을 수 있는지 몰랐는데, 이렇게 정리해보니 어떤 요청을 할 수 있을지 알 것 같음
- 이걸 기반으로 event를 설계할 수 있음
- 어떤 것을 기록하고 싶은지?
- 해당하는 event_name 정의
- 어느 시점에 실행하는지?
- 어떤 파라미터를 갖는지?
- Event Parameter: 이벤트의 정보
- 로깅 할 수 있는 솔루션: GA4 (웹), Firebase (앱), Amplitude, Mixpanel, Braze, 자체 개발 등
- 본질은 동일: ‘필요한 데이터를 정의한 후, 정의한 상황이 되면 데이터를 이렇게 저장’
- default event라고 자동으로 수집되는 이벤트가 있음 (Firebase, GA4)
- 로그 설계 시 context 전달 필요함
- 작업의 당위성을 확립하고자 왜 필요한지 전달하긴 했었는데, 강의에서는 개발자가 더 좋은 방법을 제시할 수 있기 때문이라고 함.
- 실제로 설계 당시, 기존 로그로 이미 가능한 것이다~ 라는 얘기를 종종 들어서 불필요한 로깅을 방지할 수 있었음
- 개발자, 분석가에게 항상 감사함을 표현하라고 하는데, 좀 웃김
로그 설계를 기록하는 tracking plan (event taxonomy)
- 쉽게 말해 히스토리 남기는 셈 + 로그 명세 관리
- 지금 조직에선 로그 명세 관리했었는데, 업데이트 안한지 꽤 됨. 그런데도 업데이트 안 된 것 조차 종종 들여다보고 있음. 니즈는 있는데 아무도 안하려는 귀찮은 작업…
- 핵심은 공통화된 패턴을 잘 기록하고, 새로운 사람이 와도 쉽게 확인할 수 있도록 온보딩 문서 작성하는 것
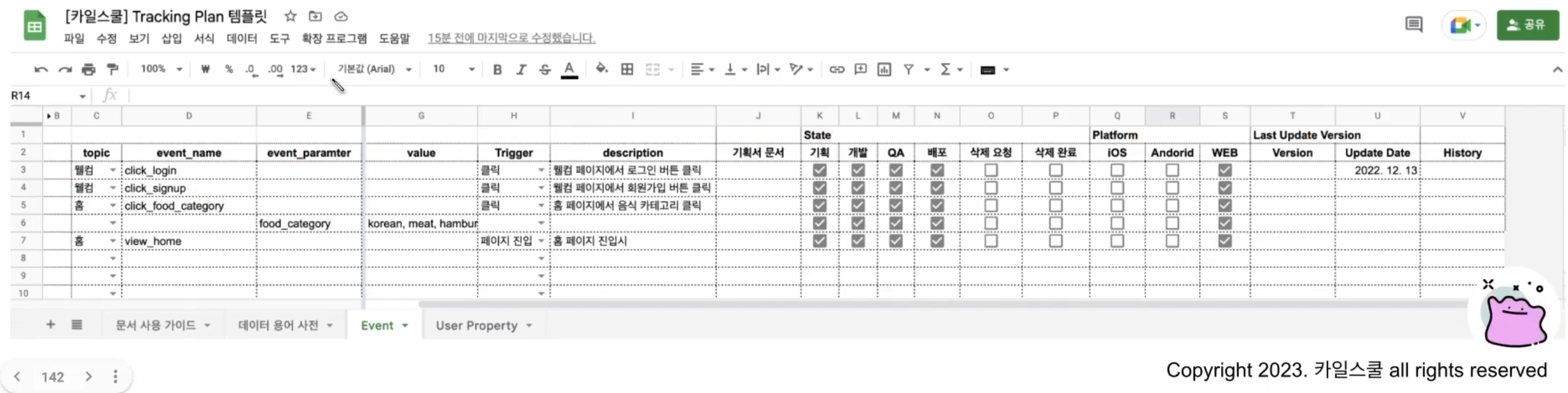
- 대충 위와 같은 항목을 포함하는데 (+용어 사전) 꽤 유용한 형식일 것 같아 캡쳐 땀
- 지금 조직에 있는 PM들은 이런 event taxonomy 쓰는걸 한번도 못봤는데, 분석가가 주도적으로 작성해도 되는건가?
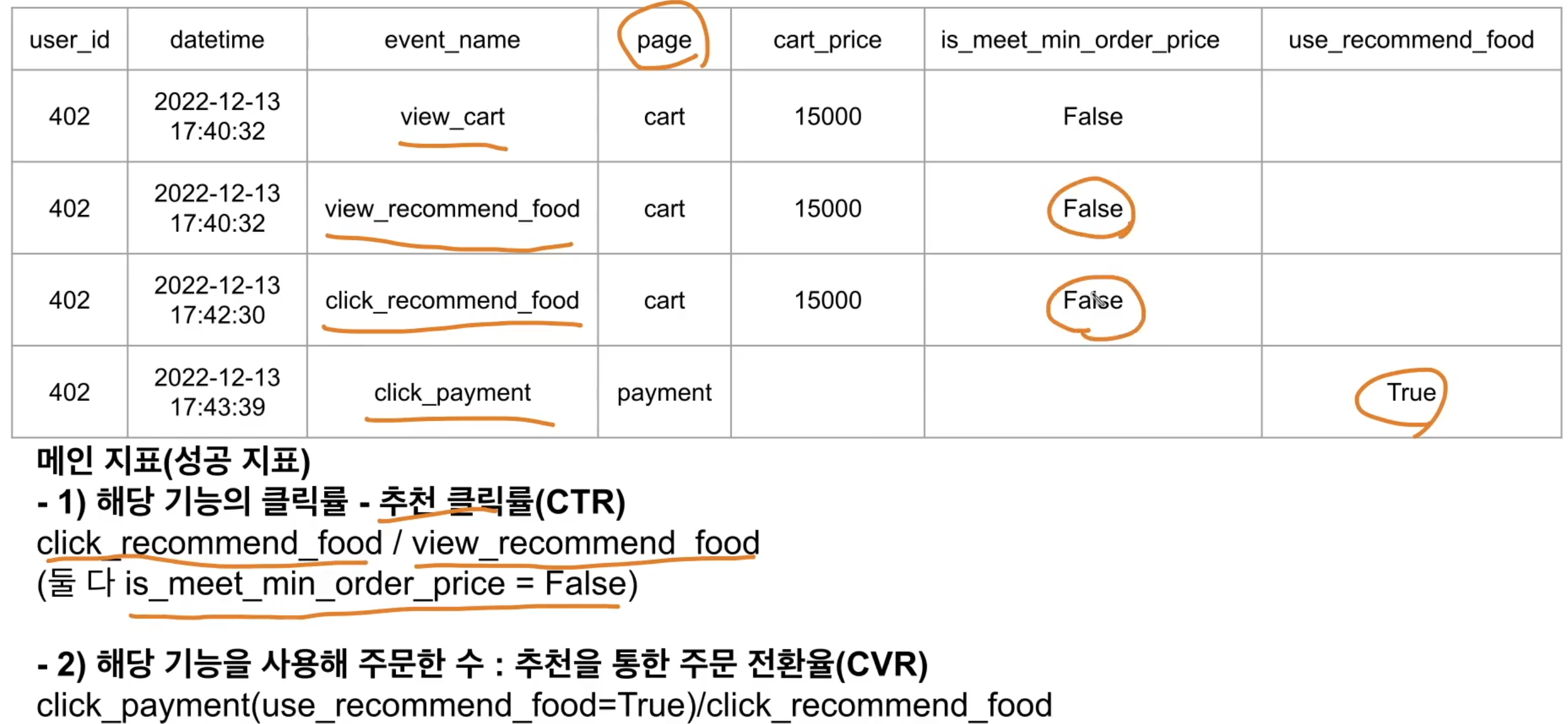
- 로그 설계 시 위와 같이 하는 방식이 나한테 맞는 듯
- 보려고 하는 지표와 집계 방식
- 이벤트, 파라미터 정의 후
- 설계한 로깅으로 저장되는 데이터 형태(테이블) 상상해서
- 이걸 기반으로 실제 지표 계산해보는 방식 (일종의 검토)
- 계산 시 실제 쿼리를 짜보는 것도 좋을 것 같음 (그래야 실수 줄일 수 있을듯)
- 기존에 있는 로그에 파라미터를 추가하는 경우
- 추가한 시점 이전, 이후에 따라 로그 스키마가 달라진다는 점
- 로그 분석 시 이게 은근히 걸림돌
데이터 QA
- 로그 설계 작업 시 가장 부족했었던 부분. 당시 개발자 분한테 이건 QA를 한게 아니라는 피드백을 받았을 정도..
- 데이터 QA로 확인해야 하는 것 (아래 항목으로 체크리스트 만들면 될듯)
- 데이터 로그가 기록되고 있는가?
- 지정한 이름, 값으로 기록되는지?
- 지정한 데이터 타입대로 기록되는지?
- 의도한 시점에 trigger 되는지?
- 앱 경우라면, Android, iOS가 동일하게 데이터 저장되는지?
- QA 핵심은, 어딘가 저장된 로그를 단순히 확인하기만 하면 됨 (쌩 노가다)
- 자동화하는 방법도 있긴 함. 동작 -> 확인 이 과정을 자동화시키기만 하면 됨
데이터 분석 레포트에 들어가면 좋은 요소
- 강의에서는
- 요약
- 이 업무가 어떤 목적으로 시작되었는가
- 어떤 지표를 사용했는가
- 결론은 무엇인가
- 과정은 어떻게 되었는가
- 과정에서 필요한 의사 결정은 무엇인가
- 앞으로 action plan은 무엇인가
- 추가로 파악하면 좋은 요소
- 스토리텔링: 레포트를 보고 변화를 만들려면 사람들의 마음을 움직여야 하는데 필요한 것
- 만약에로 이야기를 시작하면 도움이 됨
- 만약 유저 리텐션을 5% 올렸다면, 어떤 일이 벌어졌을지?
- 레포트를 고객 관점에서 전개하는 것도 도움이 됨
- 이렇게 하는 목적은 사람들에게 변화의 의지를 북돋는 것
- 에에올과 같은 영화.. 이걸 보고 이렇게 해야겠다~라는 생각이 든 것처럼, 내 보고서를 에에올과 같이.
- 그동안 ‘변화’ 자체에는 신경을 안 썼고, 질문에 대한 답을 잘 내는 것에 초점을 맞췄음
- 동료들의 피드백: 여기선 오타, 띄어쓰기 등을 봐달라는게 아니라 잘 이해되는지 봐달라는 것
- 레포트 최초 공유엔 직접 공유하는 것이 rapport를 쌓는데 좋다고 함
- 이렇게는 생각 안해봤는데… 그냥 저 사람이 무슨 생각을 하면서 말하는지 알려면 대면이 편해서 선호해왔었음
- 레포트 관련 팁 1~5 (당연한 얘기인데, 잘 안 지킨 경우 종종 있어서 명심할 것)
- 핵심 지표 위주로 먼저 제시 / 지표 해석하는 방법 추가 / action item을 제시하는 것이 핵심
- 디테일 챙길 것 (폰트 통일, 용어 통일, 생소한 용어는 사전 정의 필수, 문체 통일, 그래프 범례 확인, 그래프 단순 나열이 아니라 생각을 추가할 것)
- 모든 업무를 레포트에 넣는게 아니라, 보는 사람이 궁금해할 내용 위주로 공유할 것 (레포트 != 업무 일지)
- 모든 부분에 설명 자료를 추가할 것. 레포트를 보는 사람의 경험(UX)를 고려할 것.
- 데이터 추가 시, 데이터 추출 쿼리, 데이터 경로 명시할 것. 먼 훗날 다시 보는 사람을 위한 배려라고 생각하자
시각화 툴
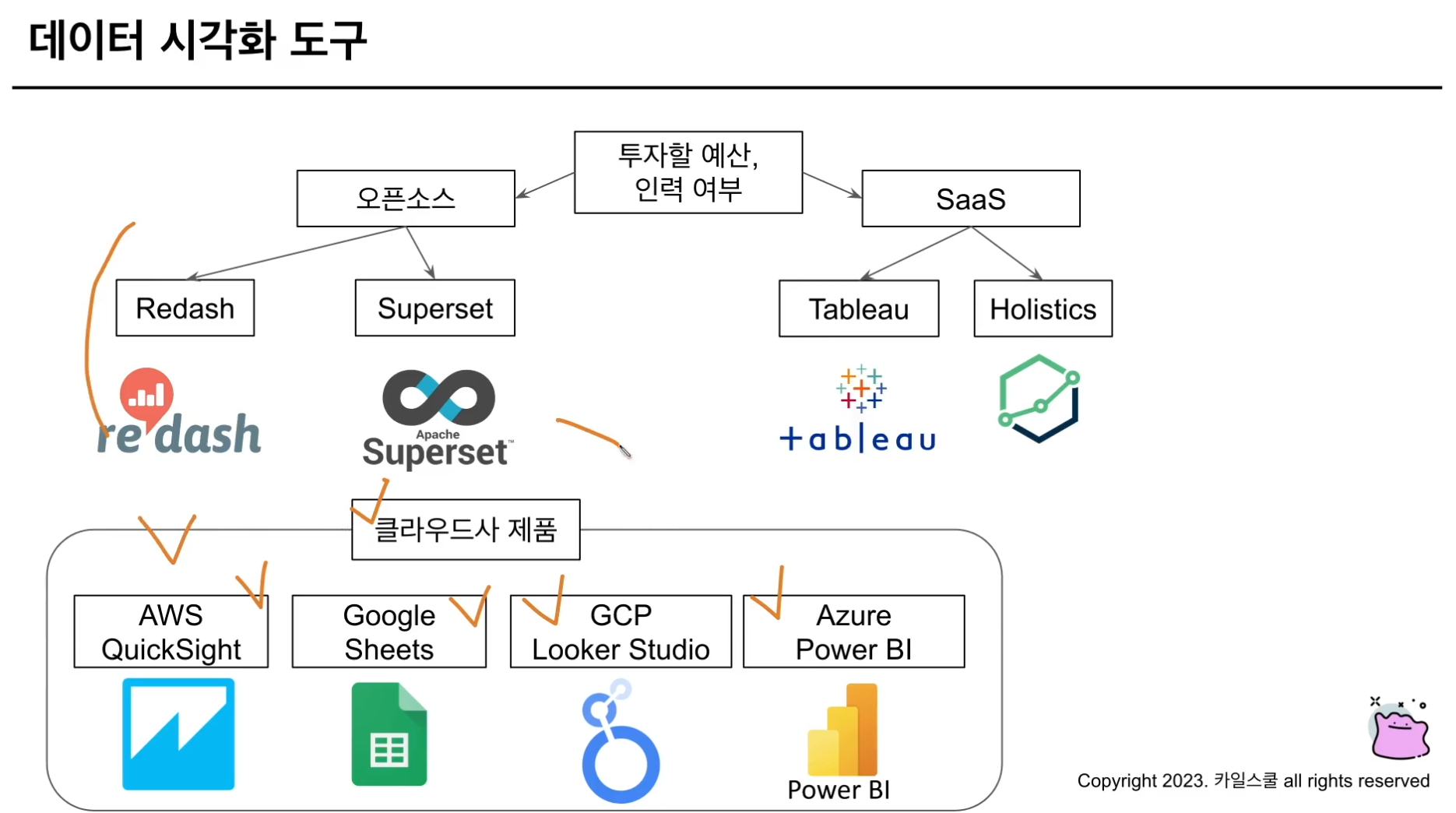
- 이렇게 구분 지을 수 있다~ 정도
- ‘데이터 시각화 도구 선택시 고려할 기능’이라고 강의에서 소개했는데, 역으로 생각하면 ‘데이터 시각화 툴을 다룬다~’는 것은 아래 기능을 잘 활용할 수 있어야 함을 의미. 면접 때 필요한 부분일 것 같아서 가져옴
- 데이터베이스 연결
- 쿼리 기능
- 스케줄링 기능
- 유저 권한 관리 기능
- 알림 기능
- 데이터 다운로드 기능
- 공유 기능
- 지금 조직에선 분석가인 내가 저 위 기능을 다 관리하고 있음. 이런 것도 나중에 어필이 될지 모르겠지만..
- 위 툴과 Amplitude, Mixpanel, GA4 등의 PA 도구 간 차이?
- 전자는 DB 데이터에 연결해서 데이터 시각화 vs 후자는 유저 로그 데이터를 시각화
- 이런 차이가 있었구나~
Metric Hierarchy
- 지표들의 계층 구조를 의미함
- 데이터 기반 문화의 기초
- 종류
- Focus Metric: 비즈니스에서 가장 중요한 지표
- L1 Metric: Focus Metric의 input metric / Focus Metric의 보완 요소
- L2 Metric: L1 Metric의 inputm metric / L1, Focus Metric에 기여하는 구체적인 지표
- 전사적인 것만 있는게 아니라, 세부 프로덕트 단에서도 이런 계층 구조를 잡는 것이 도움이 된다고 함
- 당장 업무에 필요한 내용은 아닌듯.. 앞으로도 필요할까..?
- 애초에 계층 구조를 잡는 것이 장단점이 있을 것 같음
A/B Test
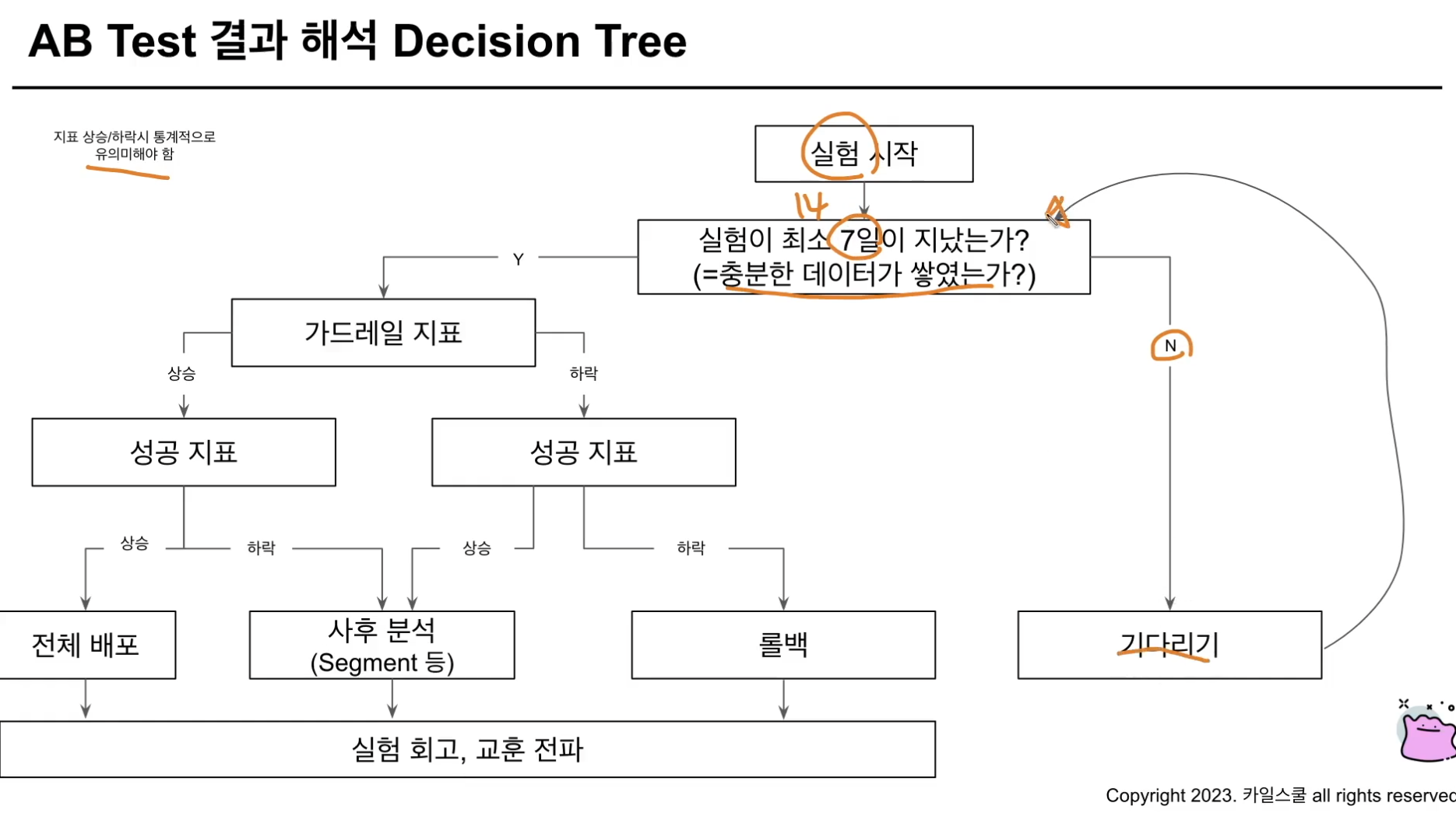
- 저번 스터디 때 선주님이 질문한 내용과 관련있어 가져옴. 각 지표가 어떤 방향일 때 어떤 액션을 취해야 할지?를 decision tree 형태로 정리

- 테스트 잘 진행하기 위한 13가지 규칙. 대부분 당연한 얘기지만, 역시나 잘 지키기는 어려운..
- 테스트 예시
- 귀무 가설: 추천 기능은 페이지 전환율에 영향을 미치지 않음
- 대립 가설: 추천 기능은 페이지 전환율에 영향을 미침
- Primary Metric: 페이지 전환율 (CVR)
- Secondary Metric: 주문 전환율 (CVR)
- Guardrail Metric: 해당 페이지 이탈율
- 가드레일을 이렇게 설정할 수 있는거구나..
- 로그 설계는 기존과 동일한데, user property 쪽에 이 유저가 대조군인지, 실험군인지 표시만 하면 됨. 로그 쪽은 생각보다 간단하네

- 대표적인 실험 플랫폼. Hackle 말고도 엄청 많구나.
- 실험 플랫폼을 만드는게 분석가 커리어에 필요할까?
- 플랫폼은 부수적인 것. 많은 실험을 효율적으로 하고자 할 때 도입을 고려하는 것인지, 플랫폼 자체를 위한 업무는 지양하는게 맞는 것 같다
- 실험 플랫폼 기능
- 제품의 새로운 기능이 런칭될 때 배포하는 방식: 개발자 분이 사전에 심사 받아놓고 정해진 시간에 배포함.
- 개발자가 아프거나 롤백인 상황에선? Featrue Flag: 실험 시작을 이 기능을 통해 trigger할 수 있음. 비율도 조정 가능
- Feature Flag는 다른 상황에서도 사용 가능함.
- Feature Flag가 On이 되면, 테스트 그룹 분배기를 통해 어떤 유저에게 어떤 기능을 보여줄지 정함
- 유저 아이디를 해시 알고리즘 통해 또다른 숫자로 만든뒤, 홀수는 A, 짝수는 B로 만들 수 있음
- 그냥 유저 아이디 사용하면 안되나? 왜 굳이 해시를 거치는지?
- 이후 부터는 지표 정의 / 실험 기록 / 실험 분석. 궁금했던건 Feature Flag 였음…
인지 편향
- 경험에 기반한 비논리적 추론
- 확증 편향: 자신의 선입견에 기반한 선택
- 사전에 B안이 더 좋다고 생각하고 테스트 진행. 계속 메트릭을 쪼개서 B안이 더 좋아질 때 까지
- 선택 편향: 표본을 치우치게 선택하는 것
- 실험군에 헤비 유저를, 대조군에 신규 유저를 구성하는 경우
- 특정 조건에서 수집한 데이터 분석한 결과 A라는 결론. 그러므로 모집단에도 A 결과가 나올 것이다라는 경우
- 기준점 편향: 한가지 특성, 정보에 많의 의존하는 경우
- 1일차 지표로 전체 기간 결과를 확정하는 것.
- 중고 물건 구매 시 처음 제시받은 가격을 기준점으로 여기고, 이 가격보다 조금 낮아지면 저렴하다고 느끼는 경우 <- 이건 몰랐었는데.. 난 호구?
- 실제로 저렴한지는 중고 물건의 평균 시세를 고려해야 한다고 함
- 노력 정당화: 많은 노력 = 높은 가치라는 편향
- 테스트 결과 기존안이 더 좋으면 롤백해야 함
- 근데 개발에 참여한 분들 관점에서 노력했으니 일단 새로운 UX로 가자!는 경우
의사 결정 TIP
- 답을 내린다고 생각하기 보다 배팅한다는 표현을 써볼 것
- Gray 영역의 문제를 답을 알기 어려운 것이 당연함.
- 알지 못하는게 당연한걸 알려고 노력해서 스트레스 받기 보다 인정하고, 내 결정이 틀릴 수도 있음을 받아들이는 자세가 필요
데이터를 활용하기 위해 필요한 기술적 인프라
- 데이터 검색 인프라: DB Schema, ERD, Event Taxonomy
- 데이터 거버넌스: 전사적으로 일관된 기준으로 데이터를 관리 / 데이터 표준, 데이터 활용 가이드 / 데이터 용어집
- 데이터 웨어하우스: 데이터를 분석할 수 있는 플랫폼 / 속도가 빠르고 쉽게 사용할 수 있어야 함
ChatGPT를 분석에 활용하는 방법
- ideation / 로그 설계