1. 언어 모델 (Language Model)
언어 모델은 단어 sequence에 확률을 assign하는 모델이다. 확률을 할당한다는게 뭐고 어떻게 한다는 걸까? 이전 단어가 주어졌을 때 다음 단어를 예측하는 task(?)를 보편적으로 사용한다. 예를 들어 ‘단어 A가 있을 때 다음에 B가 올 확률은?’과 같은 방식으로 단어 seq에 확률을 assign한다는 것이다. 같은 맥락에서 언어 모델링은 주어진 단어로부터 아직 모르는 단어를 예측하는 것이다.
A 단어 다음에 B 단어가 올 확률이 높다는 것은 무엇을 의미할까? 애초에 우리는 A 단어 다음에 왜 B 단어가 와야한다고 아는걸까? 이게 문법때문이라고 보는 시각도 있고 어느정도 이해되지만 이러한 시각은 POS 개념에만 초점을 맞춘게 아닐까. 가령 ‘매운’ 다음에 ‘떡볶이’가 올 수도 있고 ‘닭발’이 올 수도 있으니까? 무엇을 표현하고 싶다는 의지 또는 생각이 결국 글자와 단어 seq로 나타나는건데 이런 생각이 확률로 표현이 될 수 있는건지 의문이다. 생각 기저에 깔려있는 무의식의 패턴을 드러내는게 모델 훈련 아닐까?
언어 모델의 원리를 수식으로 나타내면 다음과 같다. 단어 sequence를 $\mathcal{W}$, 단어 하나를 $w$라고 한다면,
\begin{aligned} P(\mathcal{W}) = P(w_1,…,w_n) = \prod_{i=2}^{n-1} P(w_1)P(w_{i+1}|w_1,…,w_i) \end{aligned}
항상 이런 낯선 개념을 접하면, 그걸 처음 고안해낸 사람의 논리 프로세스를 상상해보곤 하는데, 이 경우는 수식이 너무나 깔끔해서 쉽게 알 것 같다.
- 이 단어 sequence(문장)이 나올 확률은 얼마일까?
- 단어 seq를 $\mathcal{W}$, 그 안에 포함된 단어를 $w_i$라고 해보자
- Probability function을 사용해서 이렇게 풀 수 있는데
- 이걸 조건부 확률을 사용해서 이렇게 조건부 확률의 곱으로 나타낼 수 있겠다.
- 근데 이 조건부 확률의 의미는 결국 $w_1,…,w_i$가 주어졌을 때 다음 단어인 $w_{i+1}$을 예측하는거네?
- 오 신기해 너무 재밌다
마지막은 내가 진짜 재밌어서 넣었다. 검색 엔진이 언어 모델을 사용하는 대표적인 예시다.
2. 통계적 언어 모델 (Statistical Language Model)
그럼 조건부 확률은 어떻게 구할까? 빈도 수 기반의 접근이 있다. 학습에 사용된 corpus가 있을 때, 그 corpus에서 우리가 원하는 문장이 몇 번 나타났는지 계산할 수 있다고 가정한다. 가령 다음과 같은 조건부 확률을 구한다고 하면,
\begin{aligned} P(w_3|w_1, w_2) &= \frac{P(w_1,w_2,w_3)}{P(w_1,w_2)} \\
\text{where } P(w_1,…,w_i) &= \frac{\text{the number of } w_1,…,w_i \text{ in the corpus}}{\text{the number of total word sequence in the corpus}} \end{aligned}
매우 직관적이고 간단하지만 그만큼 한계점이 있다. 우리가 원하는 특정 단어 sequence가 주어진 corpus 내에서 얼마나 등장할까? 단어 sequence가 복잡해질수록 등장하는 경우가 0에 가까워질텐데 그럼 결국 조건부 확률 값도 0에 수렴한다. 이런 문제를 sparsity problem이라고 한다. 이 한계를 해결하기 위해 n-gram이나 smoothing, back-off 등의 여러 generalization 기법이 있지만 sparsity problem에 대한 근본적인 해결책이 되지 못한다. 그래서 통계적 언어 모델이 인공 신경망 언어 모델에 비해 뒤쳐질 수 밖에 없다고 한다.
궁금한건 저 한계라는 것은 어차피 단어 빈도에 기반한 확률이다. 확률을 정의하는 여러 방법 중 빈도론이라는 한가지 접근법만 시도했을리는 없을텐데… 적어도 베이지안을 접목하려는 시도는 있었을 것이고, 그 방법 역시 잘 안됐던 것이 분명하다. 어떤 시도가 있었는지 알아보자!!
3. N-gram 언어 모델
기존의 빈도 기반 언어 모델을 보완한 것인데, 아이디어는 간단하다.
\begin{aligned} P(w_3|w_1,w_2) \approx P(w_3|w_1) \end{aligned}
로 확률 값을 구하면 정확하지는 않지만 어느정도 근사한 값을 얻을 수 있다는 것이다. 아예 0의 확률값을 갖느니 biased estimates를 얻는다는 점에서 익숙한 원리다. 여기서 몇 개의 단어를 포함한 것인지 정해야하기 때문에 N-gram이라고 한다. -gram 이라는 표현이 네트워크 분석의 지표에서 나온 것 같아 궁금해서 찾아봤는데,
Something written, drawn or otherwise recorded.
이라는 의미의 그리스어라고 한다. 네트워크는 검색해도 안나왔다… N-gram은 window라고 봐도 무방하며, unigrams, bigrams, trigrams, 4-grams,…로 나뉜다. 이 때 단어 sequence에서 N개 연속된 단어를 잡는 경우는 여러 가지가 있는데, 그 중 가장 가까운 n-1개 단어만을 고려한다. 예를 들어 $w_5$의 조건부 확률을 bigrams를 이용해서 나타내고 싶다면,
\begin{aligned} P(w_5|w_3,w_4) = \frac{count(w_3,w_4,w_5)}{count(w_3,w_4)} \end{aligned}
로 구한다. 개념 자체가 어렵지 않고 구현하는 것도 쉽다. 근데 왜 딥러닝을 못 이길까?
- 여전히 sparsity problem이 존재함
- 단어 sequence가 나타날 경우를 늘릴건지 vs bias를 줄인건지 사이의 trade-off 문제
역시 적절한 $n$을 찾는 것이 문제다. 권장하는 $n$은 최대 5를 넘겨서는 안된다는 것인데 이는 검정에 필요한 최소 표본 수는 30이다라고 말하는 것과 같다.
4. 기타 generalization methods
- Smoothing
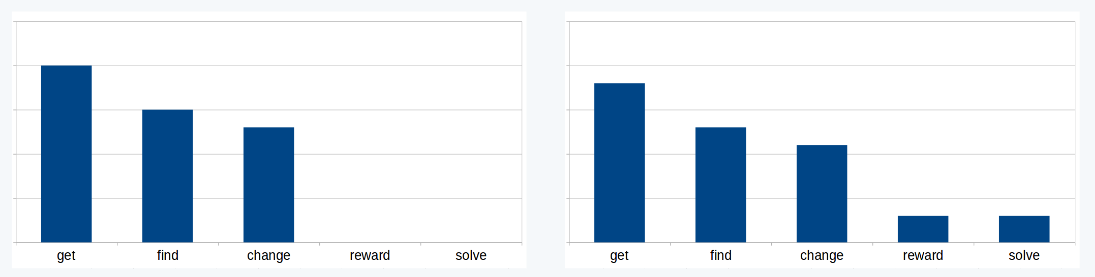
출처: https://www.marekrei.com/pub/Machine_Learning_for_Language_Modelling_-_lecture3.pdf
N-gram이어도 확률값이 0인 경우에는 일정 기준(smooth)에 따라 0보다 큰 확률값을 부여한다는 것
- “Stupid” backoff
\begin{aligned} S(w_i|w_{i-(n-1)},…,w_{i-1}) &= I(count(w_{i-(n-1)},…,w_i) > 0) \frac{count(w_{i-(n-1)},…,w_i)}{count(w_{i-(n-1)},…,w_{i-1})} + \\\ & I(count(w_{i-(n-1)},…,w_i) = 0) \times 0.4 \times S(w_i|w_{i-1},…, w_{i-(n-2)}) \end{aligned}
- Interpolation
\begin{aligned} P_{\text{interp}}(w_i|w_{i-(n-1)},…,w_{i-1}) = \lambda_1 P(w_i|w_{i-(n-1)},…,w_{i-1}) + \lambda_2 P(w_i|w_{i-(n-2)},…,w_{i-1}) + \cdots + \lambda_{n} P(w_i) \end{aligned}
- Kneser-Ney smoothing
\begin{aligned} P_{K N}\left(w_{i} \mid w_{i-1}\right)=\frac{\max \left(C\left(w_{i-1} w_{i}\right)-D, 0\right)}{C\left(w_{i-1}\right)}+\lambda\left(w_{i-1}\right) P_{\text {continuation }}\left(w_{i}\right) \end{aligned}
5. Perplexity (PPL)
SLM이 딥러닝 기반의 LM에 비해 떨어진다는 기준은 무엇일까? 여러 기준이 있지만, 그 중 대표적으로 perplexity라는 언어 모델 평가를 위한 내부 평가 지표가 있다. 단어 의미 그대로 ‘헷갈리는 정도’라고 이해해도 좋으며, 같은 맥락에서 PPL이 낮을수록 언어 모델의 성능이 좋다고 볼 수 있다. PPL은 다음과 같이 계산한다
\begin{aligned} PPL(W) = P(w_1,…,w_n)^{-\frac{1}{n}} = \sqrt{\frac{1}{\prod_{i=2}^{n-1} P(w_1)P(w_{i+1}|w_1,…,w_i)}}^n \end{aligned}
수식의 의미는 간단한데, 각 조건부 확률은 해당 time-step에서 다음 단어가 나올 확률값이기 때문에 이것의 역수를 취한 것은 얼마나 많은 후보가 있는지 나타낸다. 즉, 모든 time-step에서 가능한 경우의 수를 반영한 지표라고 할 수 있으며 이러한 점에서 branching factor라고 한다.
당연히 PPL이 낮다고 무조건 좋은 언어 모델은 아니다. 사람이 직접 느끼기에 다를 수 있고, 테스트 데이터의 양, 도메인 등의 변수의 영향을 고려해야 한다.
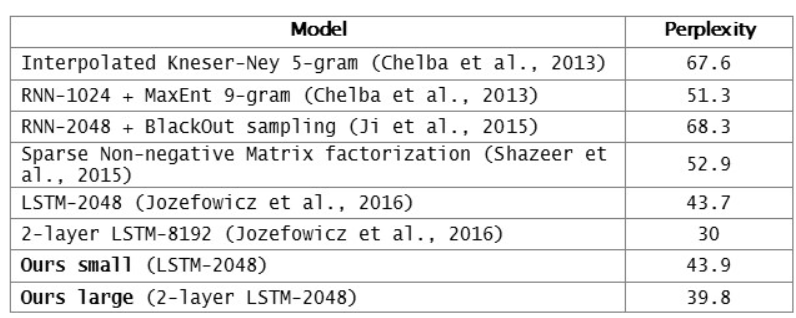
출처: https://research.fb.com/building-an-efficient-neural-language-model-over-a-billion-words/
위 테이블은 페이스북 AI 연구팀에서 n-gram LM과 딥러닝 기반의 LM을 PPL로 비교한 것이다. 가장 위의 모델이 Kneser-Ney smoothing를 적용한 5-gram LM인데 다른 딥러닝 기반 LM에 비해 PPL이 높다.
참고
https://wikidocs.net/21687
https://www.marekrei.com/pub/Machine_Learning_for_Language_Modelling_-_lecture3.pdf