Background & Contents
- Udemy의 AWS Certified Machine Learning Specialy 2024 - Hands on! 강의를 듣고 있다.
- 자격증을 목표로 하고 있진 않다. 그냥 재밌을 것 같아서!
- 분석가로 입사했는데 AWS를 몰라 많이 우왕좌왕했었다.
- 그 때 경험과 강의 내용을 종합해서 나와 같이 시작하는 사람들에게 도움이 될 내용을 정리했다.
- 실무에서 자주 접한 IAM, S3, Athena, EMR, RDS, OpenSearch 위주로 설명
- 여유가 되면 추가적으로 Kinesis, Glue, Quichsight, Sagemaker 도 다뤄볼 예정 (part 2)
IAM
- 입사한 첫날, 데이터를 다루려면 일단 분석 플랫폼에 접근할 수 있는 권한이 필요하다고 했다.
- 위키 문서에 적힌 가이드대로 어찌 가입은 했지만 이게 정확히 뭘 해주는지는 몰랐다
- IAM은 ‘Identity and Access Management’의 약자인데, 쉽게 말해 내가 AWS에서 할 수 있는 것을 관리하는 서비스다
- IAM 등록 후 AWS 리소스를 사용하면, 조직은 내가 어떤 것에 접근할 수 있는지 권한을 부여한다거나, 언제 어떤 서비스에 접근했는지 파악해서 세밀하게 제어할 수 있다.
- IAM을 생성하는 방법은 먼저 루트 계정으로 접속 후, IAM 서비스에서 관련 사용자, 그룹과 그에 대응하는 권한 정책을 부여해서 IAM 계정을 생성할 수 있다.
- 아래는 내 루트 계정으로 접속 후 IAM 계정을 생성한 예시
- ARN이라는 개념이 있는데, ‘Amazon Resource Name’의 약자로 AWS 시스템 내의 리소스를 고유하게 식별하는 키다.
- ARN은
arn:{partition}:{service}:{region}:{account-id}:{resource}로 나타냄. - account-id에 해당하는 것이 나중에 로그인 할 때 필요하다.
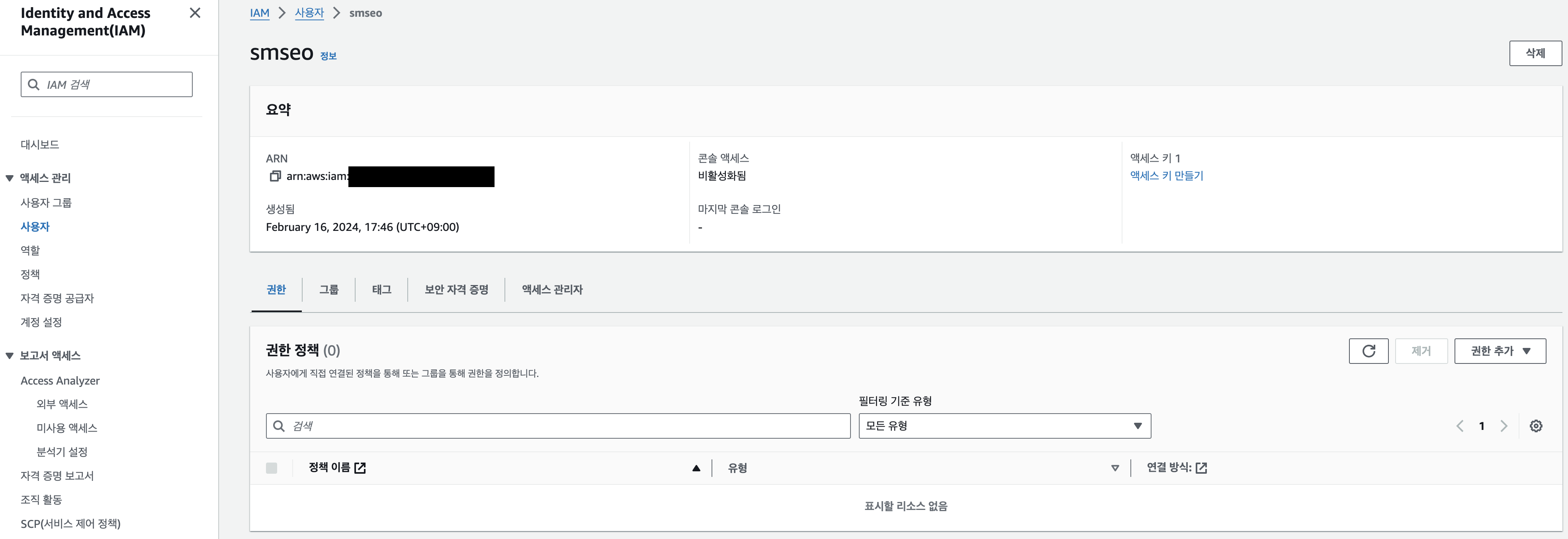
- 다르게 말하면, IAM 계정 정보를 알기 위해선 루트 계정으로 접속할 수 있는 사람이 신규 인원에게 일일히 알려주는 수 밖에 없다
- 회사마다 이런걸 도와주는 툴응 제공하는 것 같다.
- 지금 회사에선 별도의 registry(?)를 만들어서 회사 계정으로 접속 후 IAM 계정을 생성, 권한 신청, 할당 받는 프로세스를 처리하고 있다
AWS 콘솔 로그인 화면에서 IAM 사용자 -> 계정 ID (account-id) 입력 -> 사용자 이름, 비밀번호 입력하면 콘솔에 접근할 수도 있다.
- IAM으로 나에게 할당된 권한은 아래와 같다
- 이것 외의 것들은 할 수 없다는 것
- 다만 권한 명칭만 보고

S3
- objects를 buckets에 저장할 수 있는 솔루션
- 버킷 하위 경로는 모두 key라고 함
- 실제로
boto3라는 모듈을 사용해서 s3에 put 하는 경우, 아래와 같은 형태의 코드를 작성하는데, bucket과 key만을 인수로 가짐
- 실제로
client = boto3.client()
client.put_object(Bucket = '',
Key = '',
Body = '')
- S3에 있는 것들을 통합해서 data lake라고 할 수 있음
- 파티셔닝이라는 특징이 있는데, Athena와 연동지어서 빠르게 쿼리 가능케 함
- 파티셔닝을 만드는 것 자체는 별거없음
- 윈도우 파일 시스템처럼, 버킷 하위 경로에 폴더가 곧 파티션이 되는 것 같음
- 즉, 데이터 적재, 저장을 애초에 잘 해야 한다는 것
- Storeage Classes라는게 있어서 object마다 클래스를 매길 수 있음
- 실무에선 standard 또는 glacier를 주로 사용함. 전자는 언제든 사용 가능하니 별 고려할건 없었는데 glacier의 경우 복원하는 작업이 필요함
- 빨리 받으려면 그만큼 돈을 더 내야함. 당시 엔지니어링(DE) 쪽에선 Glagier Deep Archive라고 가장 저렴한 스토리지 클래스 적용시켜놨음. 48시간 기다리는게 당연한건줄 알았는데, 강의 들으면서 엔지니어링팀이 비용 절감을 위해 선택한 방법이라는걸 알았다.
- S3를 Durability과 Availability 관점에서 보면,
- Dureability: 데이터 소실에 얼마나 강한지. 만 년에 한 개 없어지는 꼴
- Availability: s3 서비스 안 끊기고 얼마나 잘 사용 가능한지. 1년에 53분은 끊길 수 있다고 함
- Intelligent-Tiering이라는 클래스. 객체 접근 주기에 따라 자동으로 클래스를 분류함. 대신 그만큼 auto-tiering fee를 챙김.
- 공식 문서에선 이게 가장 비용 효율적이라고 함. 그럼에도 DE에서 이걸 사용 안 한 이류를 생각해보자면, 객체의 클래스가 자기 멋대로 변경되면 이걸 관리하는 비용이 더 들 수 있다. 데이터 보안, 접근성에 대해 확실하게 제어할 필요가 있을 때는 이 클래스가 적합하진 않은 것 같다.
AZ라는 용어가 여기서도 나오는데, Availability Zones의 약자- Lifecycle Rules는 여러 actions을 실행하는 예약 서비스(?) 같은 것. 예를 들어 60일 이후엔 Standard IA 클래스로 transition하거나, 1년 후엔 expire시킨다거나 등.
- DE와 이런걸로 논의할 경우는 없겠지만, 만약 탐색할 권한이 있다면 한번쯤 보는 것도 재밌을 것 같음. 아니면 DE 내부 논의를 이해하는 정도
- S3 보안이 가장 골치 아팠음. 일단 두가지 방법으로 나눌 수 있음
- User-Based: IAM 정책과 관련된 것. IAM 솔루션을 사용해서 유저 단위로 어떤 API를 허용할건지 관리하는 방안
- Resource-Based: 객체 자체에 대한 접근을 조정하는 것. 버킷 자체에 대한 rule을 설정하거나, 객체 자체에 대해서도 가능함. 후자에선 Object Access Control List (ACL) 이라는 것이 있는데 이 ACL 때문에 한 번 고생했던 적이 있다.
- boto3 모듈로 s3에 put해서 다른 사람이 해당 오브젝트를 가져갈 수 있어야 했다. 근데 ACL 설정을 안하면 가져갈 수 없는 구조라 이 원인, 방법을 찾는데 한나절 걸렸던 경험이… ACL = ‘bucket-owner-full-control’를 put_object 메서드에 입력했어야 했다.
- Bucket Policies로 관리하는게 일반적인다.
- 이건 단순한 json으로 작성, 관리된다.

- 이건 Resource에 해당하는 버킷에 Pricipal에 해당하는 모든 유저가 get 가능케 하는 정책
- 버킷 정책 설정하는건 버킷 - Permission - Becket Policy의 Edit 버튼 - Policy Generator로 정책 설정 가능함.
- Block Public Access를 설정 해제하면 공개 URL을 이용해 어디서든 액세스할 수 있음.
- VPC Endpoint Gateway라는게 있어 S3에 대한 private access를 가능케 함
Kinesis
- Apache Kafka를 대신할 스트리밍 서비스라고 함
- 실무에선 다룰 일이 없었고, 그나마 개인 스터디에서 Kafka를 써보긴 했는데 재밌을듯
- Kinesis는 아래 4개 기능(?)으로 구성됨
- Kinesis Streams: low latency streaming ingest at scale이라는데, 그냥 전송 담당하는 부분이지 않을까
- Kinesis Analytics: stream에 대해 쿼리하는 기능
- Kinesis Firehose: 적재하는 기능. 적재 위치는 S3, Redshift, ElasticSearch & Splunk라는게 있다고 함
- Kinesis Video Streams: 비디오 스트리밍을 위한 기능. cctv이런게 해당되려나?
- Kinesis Streams
- producer에서 shard를 생성하고, 이 shard를 consumer에서 청취(?)하는 구조는 kafka와 유사하다. 근데 왜 shard라는 것으로 쪼개는걸까?
- reprocess, replay는 24시간 이내에 가능한데 delete는 불가함. immutability를 보장하기 위해서
- data storage 기능이 있어 1일부터 1년까지 제공함.
- records는 1MB라고 함. 그래서 작은 사이즈의 빠른 배치에 적합
- Provisioned mode / On-demand mode가 있음. 내가 제어 / AWS에서 제어해주는 차이인듯
한계: producer, consumer의 성능, data retention 등이 비용적 한계가 있음.
- Kinesis Firehose
- 적재 기능. 꼭 kinesis streams에서만 read 할 수 있는게 아니라 모든 기기, 솔루션에서 가능한 것 같음. 근데 kinesis streams가 가장 흔하다고 함
- data ingestion 임을 강조.
- Lambda function을 통해 data transformation하고 batch writes로 저장소에 적재하는 구조
- Fully managed service라고 함. 내가 100% 제어해야 한다는건가?
- 준실시간 서비스. 즉, 최소 60초의 latency가 있다고 함. 예를 들어 전달 받은 데이터를 s3에 적재하는데 60초 정도 걸릴 수 있음
- Redshift, S3, ES, Splunk 로의 data ingestion을 담당.
- data storage는 없음. 말 그대로 deliver, ingestion 하는 역할
- 일종의 ETL 툴 같다고 생각됨
- error 케이스를 별도로 다뤄서 이것도 적재한다는게 신기함. 이게 가능한건가 싶기도 하고..
- 실습에선 kinesis streams 비용이 커서 안 다룸(그래서 실습도 없었구나) direct put 설정값을 사용했는데, 데모 테스트에선 브라우저에서 작동하는 스크립트를 실행해서 s3에 적재되게 함.
- Kinesis Analytics
- streams나 firehose에서 데이터 받아와 쿼리 날리고, 결과를 analytics tool이나 output으로 보내는 서비스
- 용도가 다양한데, 먼저
- streaming ETL: select 구 등으로 사이즈를 줄일 수 있음
- continuous metric generation: 실시간 지표가 필요할 때 이걸 활용할 수 있음
- responsive analytics: 실시간 데이터에 뭔가 이상한 점 있으면 alert 할 수 있다는 것
- lambda와 연결지어서 post-processing을 더 다채롭게 할 수 있음
Glue Data Catalog
- metadata repository라고 함. 메타 테이블이란 용어가 여기서 나왔나?
- 내가 aws 서버에 심은 모든 테이블의 schema를 추론해서 저장시켜 주는 서비스
- 당연히 athena, redshift 등과 연결지어 사용됨
- 테이블을 서치하는건 glue data crawler라고 함
- 크롤러 설정 시 db가 있음. 여기엔 크롤러가 수집한 스키마를 저장함
- Glue ETL. 이게 왜 있을까?
- 태블로의 flow와 유사함. UI도 그렇고. 스키마를 다루는 서비스다 보니까 스키마를 변경하는 작업도 같이 제공해주는 것으로 이해됨
- 배치와 같이 스케줄 거는 것도 있음. 이 점도 태블로 flow와 유사함
- Glue ETL과 Firehose의 차이?
기타
- Athena: 쿼리하는 서비스. DBMS처럼 결과까지 직접 볼 수 있다는 특징
- Redshift: 데이터 웨어하우스. 쿼리도 가능함. OLAP. column-based organized. 분석까지 고려할 때 Redshift 사용.
- RDS, Aurora: RDM 저장소. 쿼리 가능하나 OLTP. row-based organized. 단순 저장소 고려할 때 RDS, Aurora 사용
- DynamoDB: NoSQL data store. ML 모델 아웃풋 올릴 때 적합
- S3: object storage
- OpenSearch(ElasticSearch): 데이터 인덱싱, 데이터 검색(?), Clickstream Analytics 목적. ML이나 분석 기능은 없음
- ElasticCache: 캐싱 메커니즘. 왜 필요한진 잘 모르겠음
- Data Pipeline: orchestration service라고 함. 예를 들어 EC2 인스턴스 하나 파서 저장소 간 데이터 이동을 관장
- Glue ETL과의 차이? 둘 다 ETL 서비스이긴 한데, 전자는 내가 100% 관리, 후자는 AWS가 관리
- Batch: 배치 돌리는 서비스인데 도커 이미지로 돌린다고 함.
- Glue와의 차이? Batch는 모든 computing job에 대해 적용됨. non-ETL이고 batch-oriented면 Batch가 적합
- DMS: Database Migration Service. 결국 이관시키는 것. 이건 EC2 인스턴스 써가면서 이동시킴.
- Glue와 달리 실시간 - 연속적인 서비스. 또 data transformation 없음.
- Step Functions: design workflows 목적.
- 예를 들어 ML 모델 튜닝할 떄 아래와 같은 여러 단계가 있는데 이걸 workflow로 실행시키는 서비스
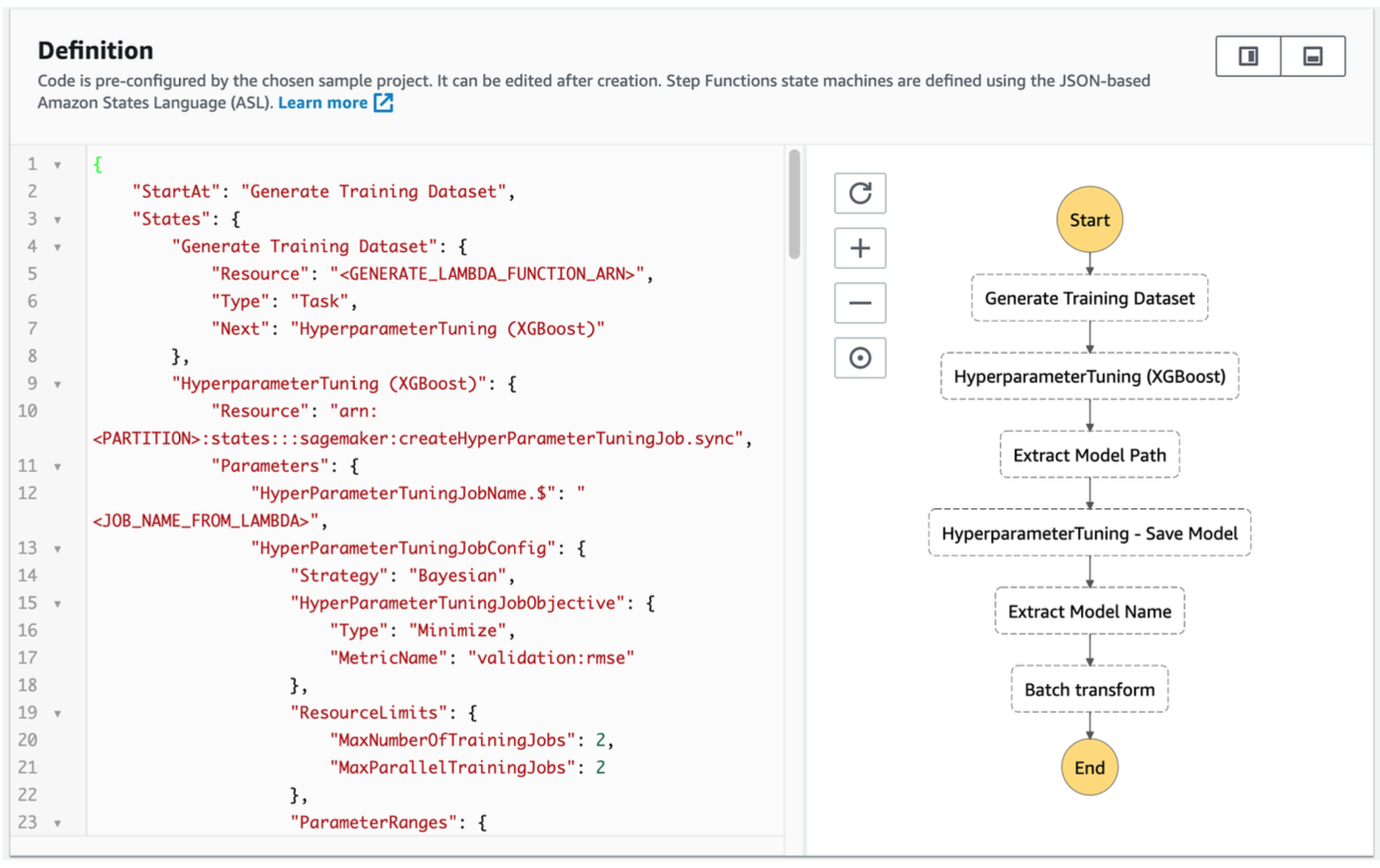
- DataSunc: on-premises에서 AWS storage services로의 이관시키는 서비스
- 분석 단에서 학습에 쓰일 train data를 sagemaker 등에 보내는 경우
Section 2: EDA
Amazon Athena
- interactive query service for S3
- 서버리스 (내가 관리해야 할 서버가 없다는 뜻. 그냥 AWS에서 제공하는 서비스 이용하기만 하면 된다는 것)
- 내부 작동 원리는 Presto라고 함. 이게 뭐지
- Glue catalog가 생성한 메타 데이터를 사용해서 쿼리하고, 쿼리한 결과를 quicksight에서 시각화하는 예시가 있음
- column-based 형식의 데이터 사용하는게 비용 절감된다고 함. (ORC, Parquet)
QuickSight
- 분석, 시각화 툴. AWS에 저장된 모든 데이터를 빠르게 시각화해서 대시보드로 제공하는 서비스
- 아래 데이터 소스를 다룰 수 있음
- Redshift (데이터 웨어하우스) / Aurora, RDS / Athena / EC2-hosted databases / S3 or on-premises
- Machine Learning Insights라는 기능
- anomaly detection, forecasting, auto-narratives 등을 할 수 있다고 함
- Quicksight Q라는 기능
- 대화형 쿼리? 라고 이해됨. 이것도 일종의 NLP니까 ML 기능을 제공하는 Quicksight에 적합하긴 한듯
- Quicksight Paginated Reports 라는 기능. 그냥 대시보드 같아보임.. 해봐야 할 것 같은데
EMR (Elastic MapReduce)
- 내가 이 글을 써야겠다고 마음 먹은 부분이다. EMR 관련해선 할 얘기가 좀 있다
- EC2 인스턴스 위에 돌아가는 하둡 프레임워크라고 할 수 있음
- massive data를 분산 처리할 수 있는 서비스
- node = EC2 instance 라고 할 수 있음
- Master node
- Core node
- Task node
- 쿼리, 분석 끝나고 클러스터 종료시켜야 비용 안나감
Haddop?
- HDFS
- 데이터 저장소. 데이터를 여러 클러스터의 인스턴스에 분산시켜 저장시키는 기능
- cache 개념. 클러스터 종료하면 사라짐
- YARN: Yet Another Resource Negotiator
- MapReduce
- 태스크와 관련된 프레임워크
- 큰 데이터를 처리해야 하는 태스크를 여러 리소스에 할당(map)시키고, 각 결과를 합치는(reduce) 것을 담당
- Spark
- MapReduce를 대체할 수 있는, EMR 클러스터에 선택적으로 설치할 수 있는 프레임워크
- 메모리 캐싱, 쿼리 최적화, 여러 언어 API 제공 등의 기능
- Spark Context라는 driver program이 시작되고, cluster manager를 통해 executor에 작업을 할당
- 여러 components
- Spark SQL: 쿼리 API. mapreduce보다 100배 빠름
- Spark Streaming:
- MLLib: ML 알고리즘을 분산 처리할 수 있는 것. Sagemaker도 가능
- GraphX
EMR Notebook
EMR 실습
- 루트 계정이 아닌 IAM 계정으로 접속 권장함
- 왜? 루트로 Workspace 접속하면 권한 이슈 있다고 함
- 권한 대충 부여한 IAM 계정 생성 후 로그인
- EMR Studio를 먼저 생성함
- 그럼 Workspace와 Workspace에서 바라보는 S3 버킷까지 같이 생성됨
- EC2 기반 EMR 클러스터는 따로 생성할 필요 없는 것 같음
- 자동으로 Workspace의 대화형 노트북 창(?)으로 이동함. 나에게 너무나 익숙한 창이 이렇게 쉽게 만들어지는 거였구나..
- 강의 자료(ipynb)를 workspace에 업로드. PySpark 커널 선택하면 됨
- 커널이 뭔데?
- VSC에서도 비슷하게 선택하는 과정이 있음. 터미널 생성할 때 파이썬 버전을 선택한다거나..
- 뒷정리 작업 중요. 그래야 호구 안 당함
- EMR Studio 접속 -> Serverless Applications에서 활성화 되어 있는 Application을 중지 -> 영구 삭제
- Workspaces 제거
- EMR 페이지로 돌아와서 Studio도 제거
- S3 버킷, IAM 유저 등도 제거하면 좋지만 비용은 안 나감
- 그냥 workspace 생성한걸로는