Background
[SQL Level UP (1)] 책을 읽고 RDBMS 내에서 쿼리가 어떤식으로 동작하는지 대략 이해할 수 있었다. 그럼 이걸 실무에 적용하는 단계. 다루려는 상황 & 내용은 아래와 같다.
- 대규모 데이터셋을 처리하는 회사의 경우 RDBMS만 가지고 데이터를 다루진 않을 것. 분산 처리 가능한 Spark를 사용하는 곳이 많을 것
- 이 책을 읽고 SQL 이해는 했는데, 이제 최적화하려고 보니까 회사는 Spark SQL을 쓴다.
- Spark SQL은 기존 SQL과 어떻게 다르며, 어떻게 최적화 할 수 있을까?
스파크의 기본 원리는 [(WIP) Apache Spark]를 참고할 것
Spark SQL 이란
- 기초적인 문제에서 시작하자. 나는 SQL로 쿼리할 줄 알고 나한텐 정형 테이블이 있다고 가정하자. 이걸 Spark 환경에서 다루려면 어떻게 할 수 있을까?
- 이런 문제를 해결해고자 Apache Spark에선 Spark SQL이라는 모듈을 제공해줌
- 다르게 말하면 우리가 생각하는 일반적인 쿼리를 Spark 환경에서 실행할 수 있게 해주는 일종의 도구(모듈)인 셈
- Spark SQL은 DataFrame이라는 데이터 구조에 기반하는데, 이 자체도 되게 효율적인 추상화라고 함
- 그 외 데이터의 스키마를 자동으로 추론하고, 다양한 데이터 소스 지원하는 등의 특징도 있지만, 이 포스트에서 신경써서 볼 부분은 Catalyst 라는 최적화 엔진
- [SQL Level UP (1)]에서 RDBM마다 쿼리 평가 엔진이 있어 가장 최적의 쿼리 계획을 도출해낸다고 했는데, Spark SQL의 평가 로직을 담당하는게 이 Catalyst 최적화 엔진임
- 또한 Tungsten 실행 엔진을 통해 런타임 효율성을 높인다고 함.
- 이게 왜 필요한지는 이해했다. 근데 이게 최선일까? 다른 방법은 없는건지?
스파크에서 데이터 다루는 방법이 Spark SQL 밖에 없나?
- 정형 데이터를 스파크로 다루는 방법은 굳이 SQL이 아니어도 된다. Spark에선 여러 데이터 구조와 추상화를 제공함. 대표적으론 아래 네가지가 있음
1. RDD (Resilient Distributed Dataset)
- Spark의 근본 추상화라고 함.
- 저수준 API라서 사용자가 더 많은 영역을 세밀하게 제어할 수 있음 (Java, C와 같은 결)
- 그 외 오류 발생 시 복구 가능하고, 파티셔닝과 분산 처리에 유용하지만 스키마 추론, 최적화 등을 제공하진 않음
2. DataFrame
- Spark의 고수준 API에 속함
- 열과 행으로 이루어진 표 형태의 데이터 구조를 제공함. 우리가 흔히 아는 테이블 구조라 표준화 되어 있다고 표현하는데, 이 표준화된 구조로 인해 다양한 데이터 타입을 쉽게 처리하고, 데이터 분석 및 처리 과정을 간소화할 수 있음
- RDD와 달리 데이터를 최적화된 방식으로 저장함. 이 때 사용되는 엔진이 Tungsten
- DataFrame API에서는 functions라는 모듈로 여러 전처리 함수를 지원함. 이 전처리 함수에 사용되는 최적화 엔진도 Catalyst라고 한다.
- 앞에서 Spark SQL도 Catalyst인데 이 때문이라고는 할 수 없지만 결과적으로 DataFrame API와 Spark SQL 둘의 전처리 성능은 거의 동일하다고 함
3. Dataset
- DataFrame의 최적화, 직관적인 사용 방식에 RDD의 타입 안정성을 결합한, 일종의 업그레이드 버전
- Spark 2.0 이상 & 스칼라, 자바에서만 지원함
- 분석가가 현업에서 마주칠 일은 잘 없는 구조일 것 같다.
- 개발자나 엔지니어 정도는 되어야 다뤄볼텐데 그 때는 또 어떤 목적으로 DataFrame을 놔두고 Dataset을 사용하게 되는걸까?
4. SQL Tables and Views:
- DataFrame 객체를
.createOrReplaceTempView()로 등록하면 테이블, 뷰라고 하는 것 같다 - 이 테이블, 뷰 역시 내부적으로는 DataFrame으로 관리된다고 함
spark.sql()로 직접 쿼리 할 수도 있고,spark.sql()의 결과를 DataFrame API로 다룰 수도 있다.- 후자는 Spark SQL과 DataFrame API를 혼합해서 데이터 다루는 셈. 자세한 예제는 아래에서 다뤄보자
사용해야 하는 유저 입장에선 어떻게 다른건지?
- 먼저 아래와 같은 json 데이터를 가정
[
{"name": "Alice", "age": 25},
{"name": "Bob", "age": 30},
{"name": "Charlie", "age": 35}
]
- RDD
from pyspark import SparkContext
sc = SparkContext.getOrCreate()
# RDD 생성
rdd = sc.textFile("path/to/json")
rdd = rdd.map(lambda line: json.loads(line))
# RDD 작업 수행
rdd_filtered = rdd.filter(lambda x: x['age'] > 30)
for person in rdd_filtered.collect():
print(person)
- DataFrame
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("example").getOrCreate()
# DataFrame 생성
df = spark.read.json("path/to/json")
# DataFrame 작업 수행
df_filtered = df.filter(df['age'] > 30)
df_filtered.show()
- Dataset
case class Person(name: String, age: Long)
val spark = SparkSession.builder.appName("example").getOrCreate()
// Dataset 생성
val ds = spark.read.json("path/to/json").as[Person]
// Dataset 작업 수행
ds.filter(_.age > 30).show()
- SQL Tables/Views
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("example").getOrCreate()
# DataFrame 생성 후 테이블로 등록
df = spark.read.json("path/to/json")
df.createOrReplaceTempView("people")
# SQL 쿼리 실행
spark.sql("SELECT * FROM people WHERE age > 30").show()
Spark SQL과 RDBMS SQL은 어떻게 다른가?
- 몇가지 기준을 잡아 비교해보자면,
| 기준 | Spark SQL | RDBMS SQL |
|---|---|---|
| 용도 | 대규모 데이터셋의 처리와 분석에 적합 | 관계형 데이터베이스의 데이터 관리와 조작에 초점 |
| 실행 환경 | 클러스터 상의 여러 노드에서 분산 처리 | 단일 서버 기반의 RDBMS에서 실행 |
| 성능 | 분산 처리와 메모리 내 처리를 통한 높은 처리 성능 | 전통적인 디스크 기반의 데이터 처리 |
| 데이터 소스 | 다양한 데이터 소스 지원 및 비/반구조화된 데이터에 유연 | 주로 구조화된 데이터에 초점 |
- 책에서 읽은 RDBMS 아키텍쳐를 기준으로 비교해보자
- Spark SQL에도 RDBMS 아키텍처에 대응하는 요소들이 있지만 분산 컴퓨팅 환경에 맞게 변형한 느낌
- 마지막 RDD 부분은 Spark SQL에서 RDD의 이런 복구 성질을 차용한 것이라고 이해함
| 비교 기준 | 일반적인 DBMS | Spark SQL |
|---|---|---|
| 쿼리 평가 엔진 | SQL 구문 분석 및 최적의 실행 계획 결정 | Catalyst 쿼리 최적화 엔진을 사용한 분석 및 계획 최적화 |
| 버퍼 매니저 | 디스크와 메모리 간의 데이터 흐름 관리, 효율적인 캐싱 및 교체 정책 운영 | 인메모리 처리 중심 |
| 디스크 용량 매니저 | 데이터 파일과 인덱스 구조를 디스크에 관리 | 분산 파일 시스템에 저장된 데이터 처리 |
| 리커버리 매니저 | 데이터 백업 및 복구, 트랜잭션의 내구성 보장 | RDD의 내결함성을 통한 데이터 처리 중 실패 대응, 장애 회복에 초점 |
Spark SQL, DataFrame API 간 성능 차이?
- 스파크 위에서 쿼리하다 보면 Spark SQL을 사용해야 할지, DataFrame을 사용해야 할지 고민될 때가 잦다
- 특히 Spark SQL 사용했는데 너무 많은 시간 걸리면 ‘아 DataFrame 사용해야 했나’라고 (잘 모르던 때에) 고민도 많이 했다
- Spark SQL은 쿼리라는 선언형 프로그래밍인 반면, DataFrame API는 메소드 체인 방식이라는 절차형 프로그래밍이다. 사고 방식 자체가 다른 언어다. 근데 생각보다 (적어도 나는) 실무에서 이 둘을 혼합해서 많이 사용한다. 각 API마다 편한 메서드가 있다보니 자연스럽게 혼합시키고 있다.
- 결론적으로는 이 둘 사이의 성능 차이는 없으며, 시간이 오래 걸린다면 그만큼 데이터가 크다거나, 또는 내 쿼리가 비효율적이라는 것
- 성능 차이가 없는 원인은 둘다 동일한 JVM 기반 Catalyst 엔진, Tungsten 엔진을 사용하기 때문 (https://velog.io/@datastsea/spark-sql-vs-dataframe-api)
Spark SQL 실행 계획 해석
- [SQL Level UP (1)]에서는 Oracle, Postgre에서의 실행 계획만 보여줌. 흔한 MySQL은 왜 안했을까 싶지만, 어쨌건 내가 다룰 것은 Spark SQL이니까!
- Spark SQL에서 실행 계획 보는 방법은 다음과 같다
EXPLAIN EXTENDED
SELECT *
FROM table
WHERE column > 100;
- DataFrame API에서도 실행 계획을 볼 수 있다
df = spark.read.json("path/to/json")
df_filtered = df.filter(df['age'] > 30)
df_filtered.explain()
- 현재 회사에선 데이터브릭스를 사용하고 있는데, 직접 실행 계획을 출력해볼 수 있다. 아래 코드를 실행하면 바로 밑의 출력 결과가 나옴
- 문제가 될만한 값은 별표 또는 삭제 처리 했습니다
display(
spark.sql("""
EXPLAIN EXTENDED
SELECT *
FROM *_mart.gcoin_topup
WHERE date >= '2023-12-12' AND platform = '*' AND product_id LIKE '%*%'
""")
)
== Parsed Logical Plan ==
'Project [*]
+- 'Filter ((('date >= 2023-12-12) AND ('platform = *)) AND 'product_id LIKE %*%)
+- 'UnresolvedRelation [*_mart, gcoin_topup], [], false
== Analyzed Logical Plan ==
date: date, platform: string, product_id: string, type: string
Project [date#3618, platform#3620, product_id#3622, type#3633]
+- Filter (((date#3618 >= cast(2023-12-12 as date)) AND (platform#3620 = *)) AND product_id#3622 LIKE %*%)
+- SubqueryAlias main.*_mart.gcoin_topup
+- Relation main.*_mart.gcoin_topup[date#3618,platform#3620,product_id#3622,type#3633] parquet
== Optimized Logical Plan ==
Filter (((isnotnull(date#3618) AND isnotnull(platform#3620)) AND isnotnull(product_id#3622)) AND (((date#3618 >= 2023-12-12) AND (platform#3620 = *)) AND Contains(product_id#3622, *)))
+- Relation main.*_mart.gcoin_topup[date#3618,platform#3620product_id#3622,type#3633] parquet
== Physical Plan ==
*(1) Project [date#3618, platform#3620, product_id#3622, type#3633]
+- *(1) Filter (((isnotnull(platform#3620) AND isnotnull(product_id#3622)) AND (platform#3620 = *)) AND Contains(product_id#3622, *))
+- *(1) ColumnarToRow
+- FileScan parquet main.*_mart.gcoin_topup[platform#3620,product_id#3622,type#3633,date#3618] Batched: true, DataFilters: [isnotnull(platform#3620), isnotnull(product_id#3622), (platform#3620 = *), Contains(product_..., Format: Parquet, Location: PreparedDeltaFileIndex(1 paths)[s3:*], PartitionFilters: [isnotnull(date#3618), (date#3618 >= 2023-12-12)], PushedFilters: [IsNotNull(platform), IsNotNull(product_id), EqualTo(platform,*), StringContains(product_id,p..., ReadSchema: struct<platform:string,product_id:string,...
- RDBMS와 마찬가지로 실행 계획은 가장 깊이가 깊은 (여기서는 +-이 가장 안쪽에 있는) 순서대로 실행된다
- FileScan: 파케이 파일에서 해당 테이블의 모든 필드(
SELECT *)를 읽음- 스캔할 때 DataFilters와 PartitionFilters, 그리고 PushedFilters라는 것이 있음
- DataFilters: 실제 데이터 파일을 읽을 때 적용되는 필터
- PartitionFilters: 파티셔닝 되어 있는 데이터에 대해 필터에 걸리는 파티션만 스캔함
- PushedFilters: 데이터 로드하기 전 데이터 소스 레벨에서 적용할 수 있는 필터
- PartitionFilters -> PushedFilters -> DataFilters 순으로 적용이 된다. 용량이 크면 파티션을 걸어야 탐색이 빠름
- 스캔할 때 DataFilters와 PartitionFilters, 그리고 PushedFilters라는 것이 있음
- Filter: 조건에 맞는 레코드만 필터링함. 이 필터링은 데이터 소스 단계에서 최적화되어 ‘PushedFilters’로 표현된다고 함
- Project: 최종적으로 필터링된 결과에서 선택된(여기서는 모든) 필드를 출력함
- FileScan: 파케이 파일에서 해당 테이블의 모든 필드(
각 단계는 Spark의 Catalyst 최적화 엔진에 의해 결정된다고 함.
- 같은 쿼리를 DataFrame API로 해서 explain 메서드를 걸면 아래와 같이 나옴
- Physical Plan 만 출력된다는 점과, 각 필드 옆의 인덱스가 다름
spark.read.table('pubg_mart.gcoin_topup')\
.where("date >= '2023-12-12' AND platform = 'STEAM' AND product_id LIKE '%pass%'")\
.explain()
== Physical Plan ==
*(1) Project [date#28, platform#30, product_id#32, type#43]
+- *(1) Filter (((isnotnull(platform#30) AND isnotnull(product_id#32)) AND (platform#30 = *)) AND Contains(product_id#32, *))
+- *(1) ColumnarToRow
+- FileScan parquet main.*_mart.gcoin_topup[platform#30,product_id#32,type#43,date#28] Batched: true, DataFilters: [isnotnull(platform#30), isnotnull(product_id#32), (platform#30 = *), Contains(product_id#32,..., Format: Parquet, Location: PreparedDeltaFileIndex(1 paths)[s3://*], PartitionFilters: [isnotnull(date#28), (date#28 >= 2023-12-12)], PushedFilters: [IsNotNull(platform), IsNotNull(product_id), EqualTo(platform,*), StringContains(product_id,p..., ReadSchema: struct<platform:string,product_id:string,...
TMI
- 열 이름과 #숫자 (예: platform#3620)
- 이러한 표현은 Spark 내부에서 해당 열에 할당된 고유 식별자를 나타냄. 실행 계획 안에서 구별하기 위함이며 같은 열이라도 실행 계획마다 뒤에 붙은 숫자가 다름 (위의 Spark SQl과 DataFrame API로 출력한 식별자가 다름)
- *(1) ColumnarToRow
- Spark가 내부적으로 컬럼 기반의 데이터를 행 기반의 데이터로 변환하는 과정을 나타냄
- 파케이 자체가 컬럼 기반의 저장 포맷인데, 스파크에선 이걸 행 기반으로 처리하다보니 이걸 변환시키고자 들어가는 과정
- +- *(1) 같은 표현
- 실행 계획의 노드(단계)를 나타냄. 실행 계획 자체가 트리 구조라고 하는데, 트리의 계층적 구조를 그냥 +-로 나타내자고 약속한 것. (약속할 때 나도 끼워주지)
- *(1)은 해당 단계가 단일 스테이지(stage)에서 실행됨을 나타냄
- 스테이지는 스파크에서 작업을 처리하는 단위라고 이해하면 쉽다
- 만약 *(2)와 같은 숫자가 붙었다면, 해당 작업이 두 번째 스테이지에서 실행됨을 의미함
- 스테이지 번호는 최적화 엔진에서 매기는 것 같음. 작업의 복잡성, 셔플(shuffle) 작업의 필요성 등에 따라 새로운 스테이지에서 실행할 수도 있다
Spark SQL 최적화
- 같은 결과를 더 빨리 쿼리하기 위해선 쿼리 외적으로 할 수 있는 것과 쿼리 자체를 개선시키는 두가지가 있다
- 외적으로는
- 파티셔닝: 적절해야 함. 대용량 데이터셋에서는 효율적인데, 저용량이라면 파티셔닝이 오히려 비효율적
- 데이터 포맷: parquet, ORC 같은 컬럼 기반 데이터 포맷이 읽기 좋음
- 캐싱: 자주 쓰는 DataFrame이라면
.cache()메서드를 사용해 메모리에 올려놓고 캐시하면 쿼리 시간이 단축됨 - 클러스터 리소스: 당연히 클러스터 메모리, 코어 수를 적절히 할당하면 성능이 올라감. 다만 이건 한계가 있는 상황임을 가정 (비용이 크니까)
- 중간 쿼리 결과물 저장: 자주 사용해야 하거나, 너무 크기가 큰데 행마다 면밀히 살펴야 하는 테이블이라면 필요한 데이터만 모아 별도 저장 공간에 적재해서 다시 불러와 사용함
- 쿼리 자체를 개선하는 방법은 아래에 정리해봄
- 쿼리 실행 환경은 데이터브릭스 노트북
- 스파크 특성 상 처음 쿼리 시 걸리는 시간이 크다는 점을 감안해서, 모든 쿼리는 최소 5회 이상 실행시켜 비교했다.
1. 필요한 열만 SELECT 하기
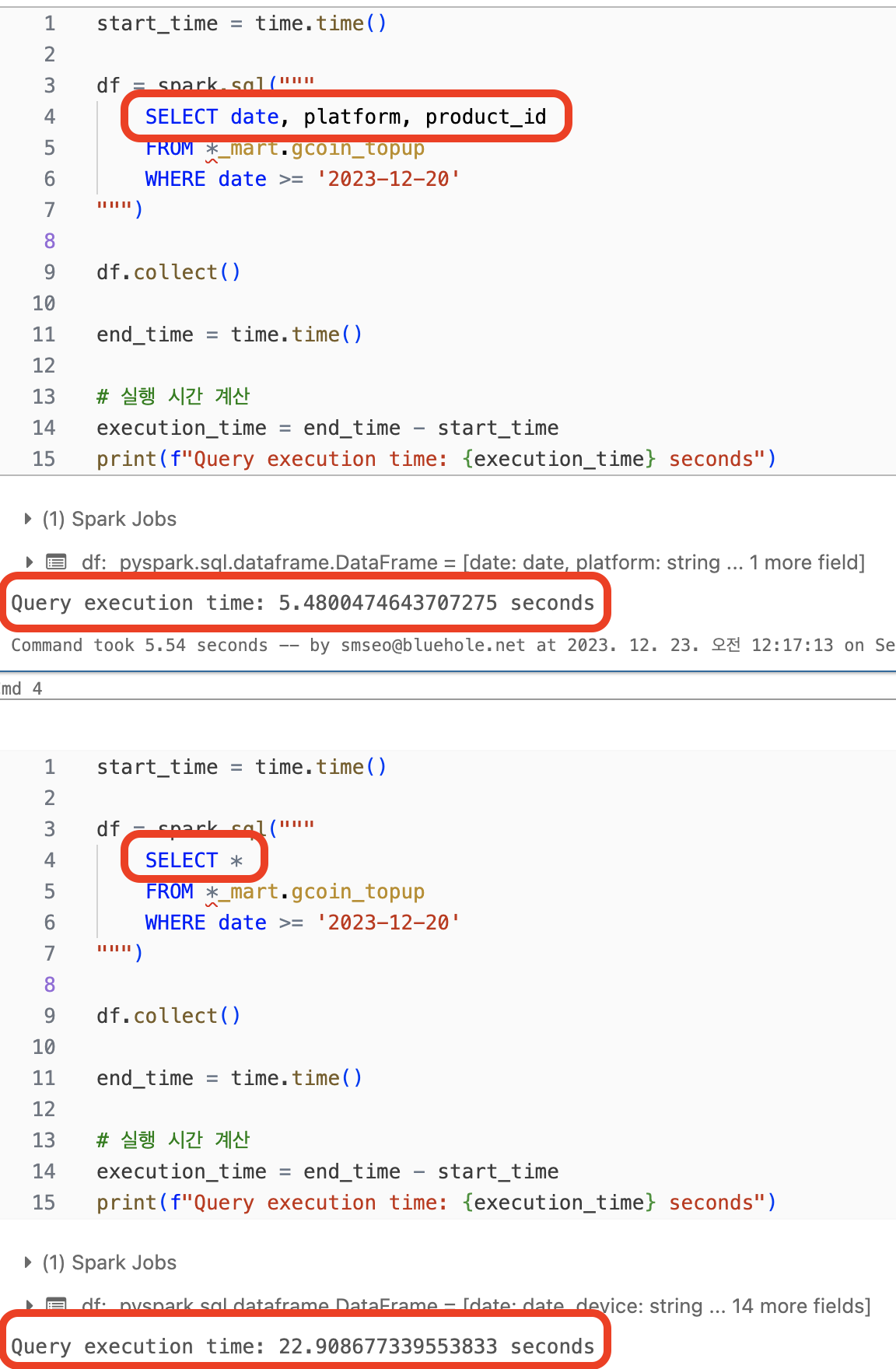
- 이건 위의 실행계획에서도 알 수 있듯이 FileScan 단계에서부터 가져오는 열에 차이가 있음
2. WHERE 구 등 조건을 걸 때 되도록 연산 하지 않기
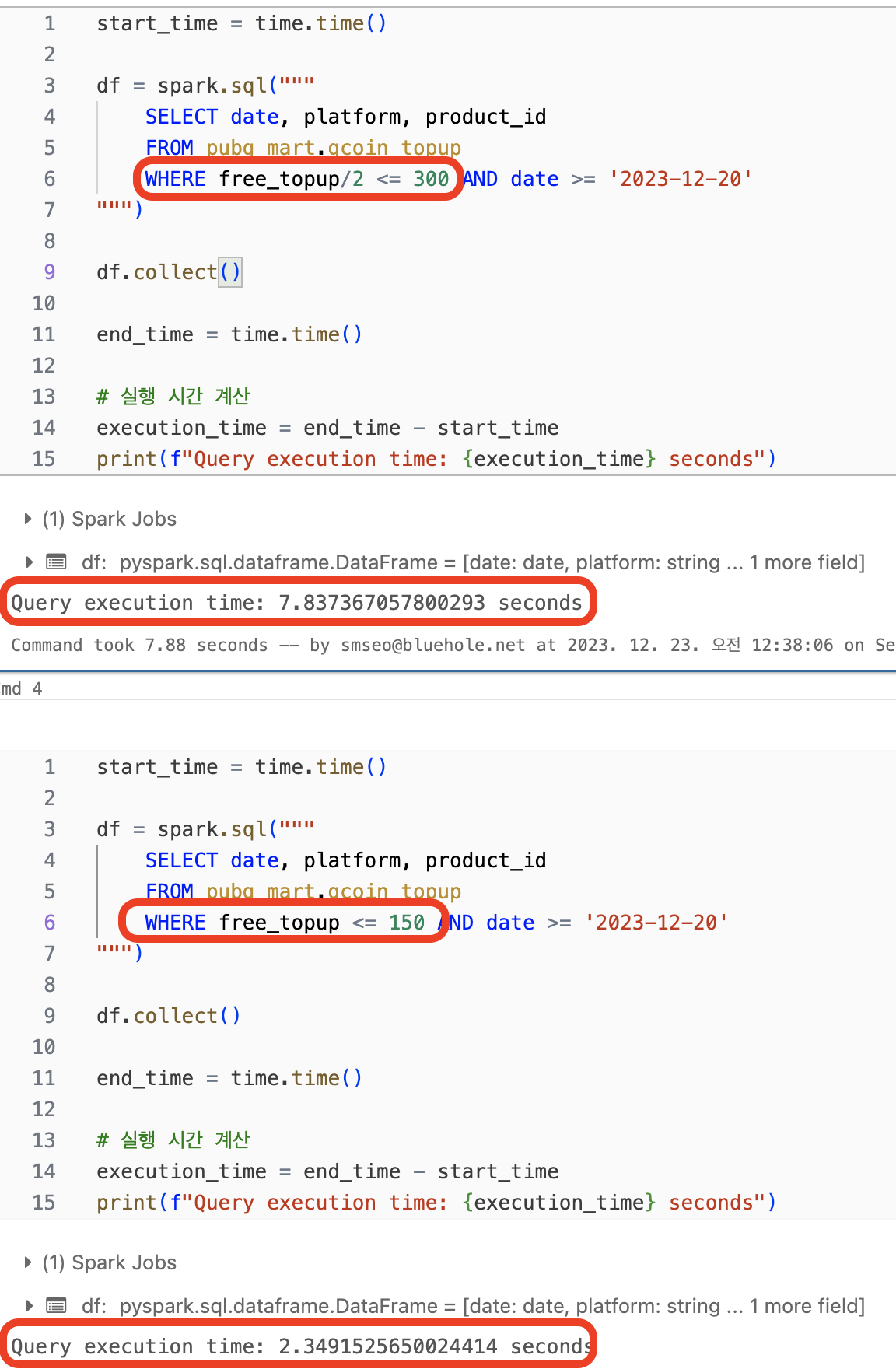
- 실행 계획을 보면 DataFilters, PushedFilters가 각각 아래와 같음
- 연산 들어간 쿼리
DataFilters: [isnotnull(free_topup#1474L), ((cast(free_topup#1474L as double) / 2.0) <= 300.0)]PushedFilters: [IsNotNull(free_topup)]
- 조건만 들어간 쿼리
DataFilters: [isnotnull(free_topup#1541L), (free_topup#1541L <= 150)]PushedFilters: [IsNotNull(free_topup), LessThanOrEqual(free_topup,150)]
- 앞에서 PushedFilters 가 DataFilters 보다 먼저 적용된다고 했는데 열 자체로만 조건을 걸게되면 PushedFilters 에서 먼저 필터를 적용하므로 더 적는 데이터를 탐색한다는 이점이 있음
- 연산 들어간 쿼리
3. LIKE 사용시 와일드카드 문자열(%)을 String 앞뒤에 배치하지 않기
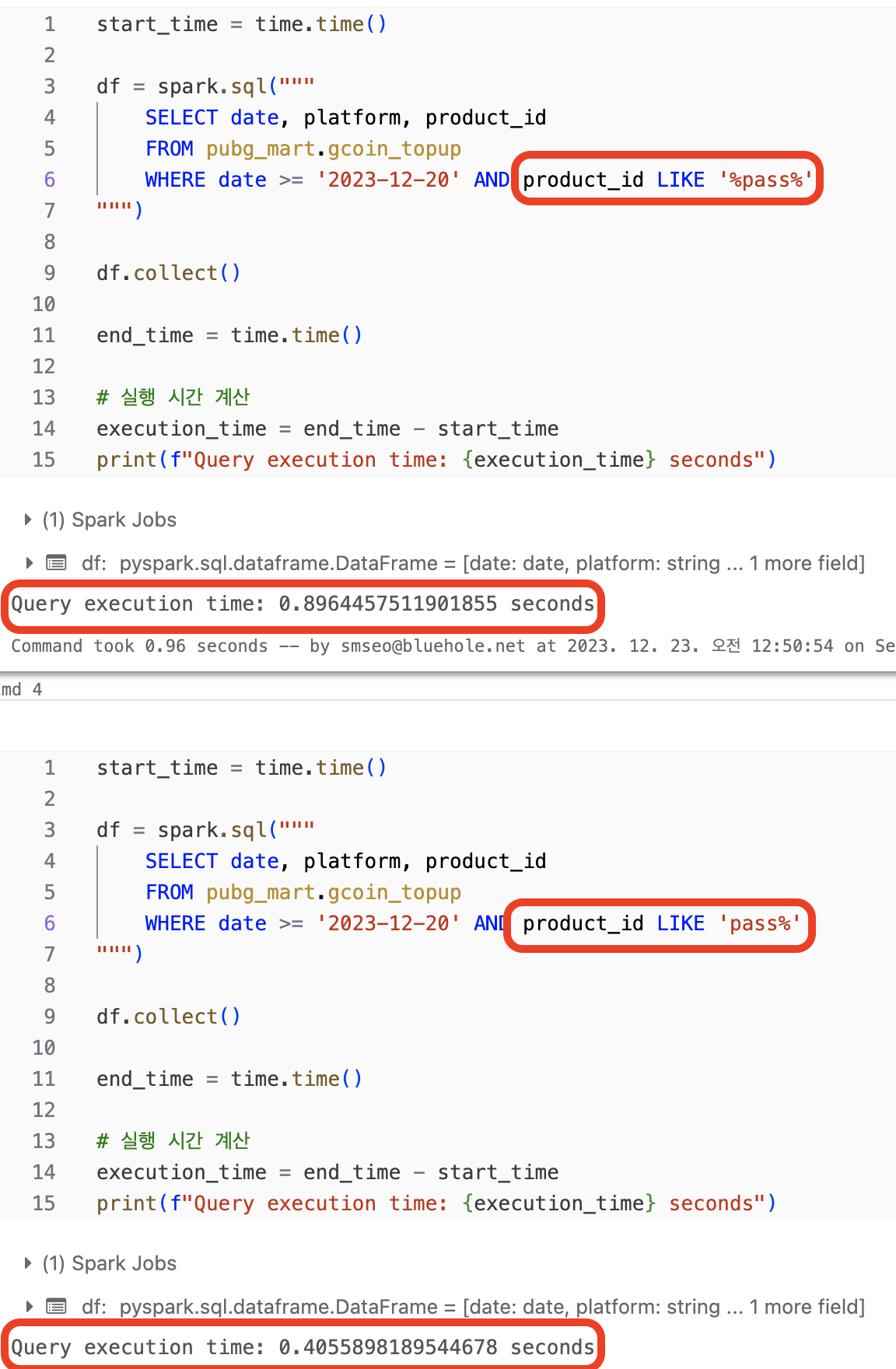
- 실행 계획에서 차이는
- 앞 뒤 다한 쿼리는
DataFilters: [isnotnull(product_id#2004), Contains(product_id#2004, pass)]PushedFilters: [IsNotNull(product_id), StringContains(product_id,pass)]
- 뒤에만 적용한 쿼리는
DataFilters: [isnotnull(product_id#2138), StartsWith(product_id#2138, pass)]PushedFilters: [IsNotNull(product_id), StringStartsWith(product_id,pass)]
- 앞 뒤 다한 쿼리는
- 자세한 로직은 모르지만 Contains 보다 StartWith이 알고리즘 상 더 적은 시간이 소요되는 것 같다
- 근데 Contains 적용할 일을 StartsWith으로 대체할 수 있을까? 불필요하게 앞 뒤 다 붙이지 않는 것이 최선인 것 같다
- 참고로 앞에만 적용해도 결과는 같음.
StartsWith이EndsWith으로 바뀔 뿐이다 - 또 참고로 RDBMS SQL 에서는 약간 다르다. 앞부분에 배치하는 것이 비효율적이라고 함
4. 조건 구에서의 순서는 상관 있다
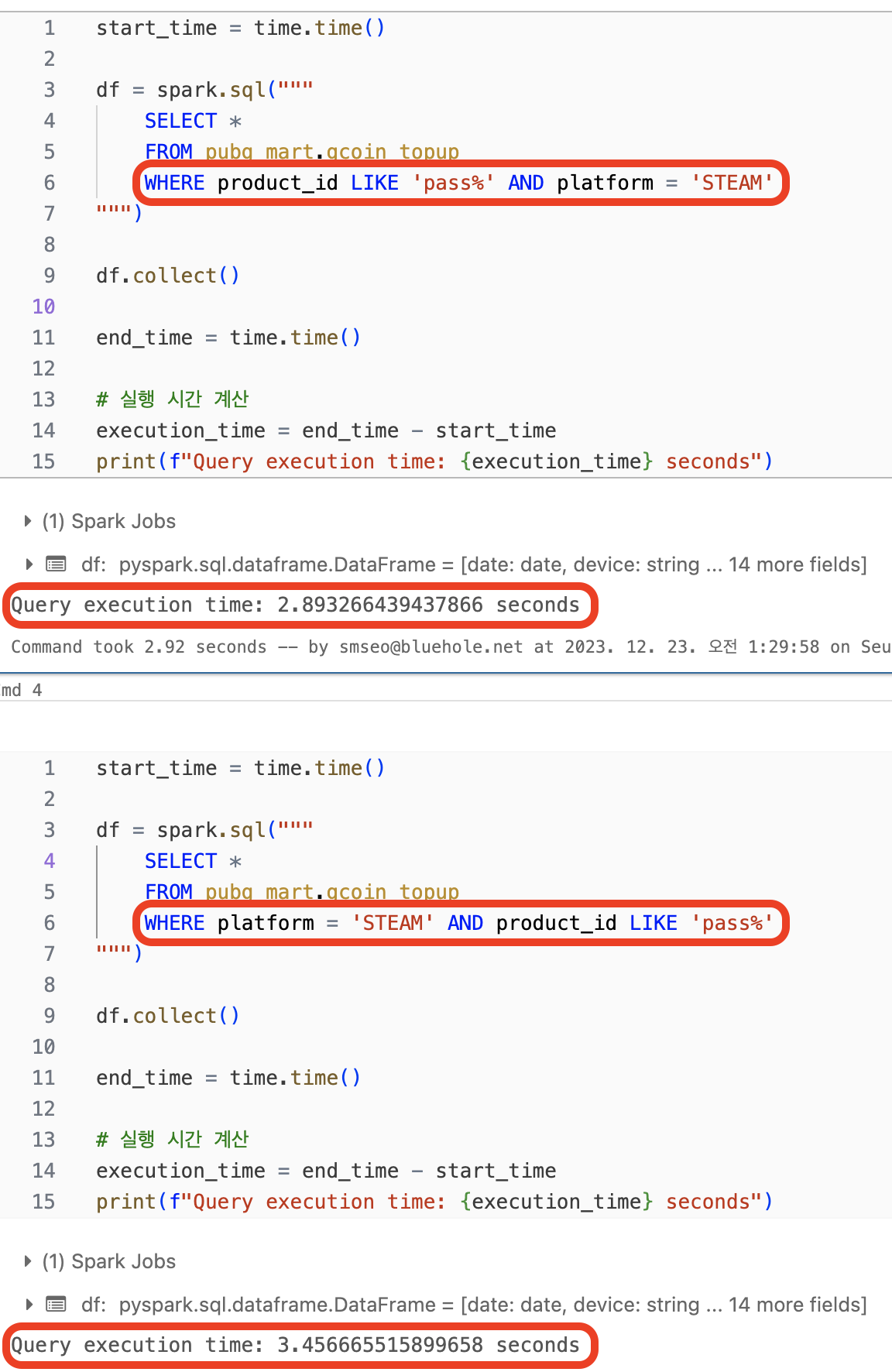
- 이건 정말 의외의 결과였다…!
- 예를 들어
product_id LIKE 'pass%' AND platform = 'STEAM'와platform = 'STEAM' AND product_id LIKE 'pass%'로 조건을 걸 때 차이가 남- 실행 계획에서 차이나는 부분은 PushedFilters, DataFilters 에서
product_id가 먼저오냐platform이 먼저오냐 뿐이다 - 다만 먼저 위치한 조건에서 더 적은 데이터만 가져올 수 있다면 이후 조건에선 더 적은 데이터에 대해서만 적용된다
- 위 쿼리에선
platform이STEAM인 경우가 훨씬 많다. 그래서 시간이 더 걸렸다고 추측할 수 있다. (추측이라고 한 이유는 이것 외에 다른 요인이 있을 수 있기 때문에)
- 실행 계획에서 차이나는 부분은 PushedFilters, DataFilters 에서
[기타] 중복 제거가 연산량이 많은데 DISTINCT 구를 대체하는건 특별한 경우 아니면 의미 없는 것 같다
[기타] GROUP BY 할 때 HAVING 이나 WHERE 이나 실행 계획에 있어 차이 없다
- RDBMS 에선 WHERE이 HAVING 보다 시간이 덜 걸린다고 함
결론
- Spark SQL에서 쿼리 최적화하는 것은 기존 RDBMS SQL의 최적화와 비슷하지만 다른 부분이 있다.
- 그래서 RDBMS SQL의 최적화 기법을 그대로 적용하면 안된다
- 실행계획과 쿼리 시간을 살피면서 그 때 그 때 최적의 Spark SQL 쿼리를 찾아내려는게 중요하다
- 이번 포스트 준비하면서 Spark SQL의 실행 계획을 읽을 수 있게된게 가장 큰 수확이다.
효율적인 쿼리를 짤 수 있게 되었으면 다음 단계는 UX다. [SQL Style Guide]를 참고해서 CPU한테 이쁨받는 쿼리 뿐만 아니라 사람한테도 이쁨 받는 쿼리를 작성해보자
참조
- [도서] SQL 레벨업 : DB 성능 최적화를 위한 SQL 실전 가이드 / 미크
- [도서] 스파크 완벽 가이드 / 빌 체임버스, 마테이 자하리아
- https://dadk.tistory.com/74
- https://kadensungbincho.tistory.com/87
- https://velog.io/@datastsea/spark-sql-vs-dataframe-api
- https://medium.com/watcha/%EC%BF%BC%EB%A6%AC-%EC%B5%9C%EC%A0%81%ED%99%94-%EC%B2%AB%EA%B1%B8%EC%9D%8C-%EB%B3%B4%EB%8B%A4-%EB%B9%A0%EB%A5%B8-%EC%BF%BC%EB%A6%AC%EB%A5%BC-%EC%9C%84%ED%95%9C-7%EA%B0%80%EC%A7%80-%EC%B2%B4%ED%81%AC-%EB%A6%AC%EC%8A%A4%ED%8A%B8-bafec9d2c073