SQL은 DB를 다루기 위해 매우 필수적인 언어다. 관련 개념과 쿼리를 확실하게 익히는 것이 본 포스팅의 목적이다.
DataBase (DB)
- DB는 뭘까? 어느정도 체계를 갖춘 데이터 집합이라고 볼 수 있다. 논리적으로 연관되어 있고, 데이터 구조를 정규화함으로써 검색, 갱신 등을 효율적으로 관리 할 수 있다. 이렇게 DB를 관리하는 시스템을 DBMS(DataBase Management System)라고 한다.
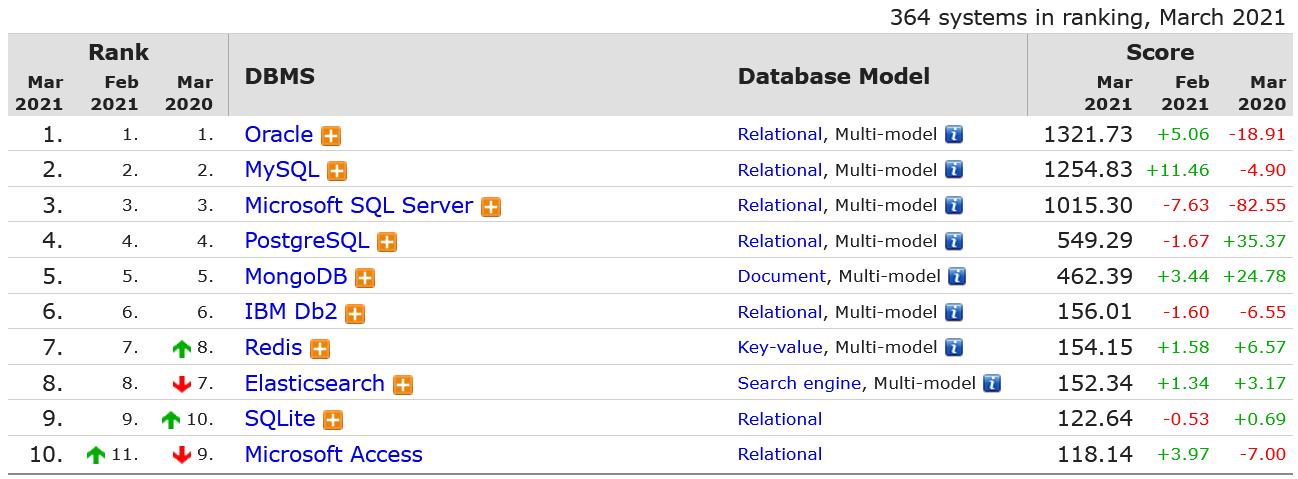
- DataBase는 relational / non-relational로 구분되는데, 전자는 주로 정형화된 데이터로 RDBMS의 R에 해당한다. 후자는 RDBMS의 한계(대용량 데이터 저장 및 처리 비용 등)를 보완하고자 schema-less 구조의 NoSQL 같은 것이 있다.
Relational DataBase Management System (RDBMS)
DB의 한 종류이며, 가장 많이 사용되고 있다.
Entity(distinct한 사람이나 사건), Attribute(entity의 특성), Relationship(entities간 관계로 one-to-many, many-to-many, one-to-one)의 3가지로 구성되어 있다.
쉽게 생각하면 2차원 테이블의 집합이다. 데이터를 attribute와 attribute value로 나눠 둘 사이 관계를 정의하고, 테이블 형태로 도식화한다. 이 때 primary key, foreign key라는 개념이 있는데, 전자는 테이블의 row를 식별하는 column이며, 후자는 다른 테이블과 병합하여 식별할 수 있는 attribute를 의미한다. 사전적 정의는 다음과 같다.
- Primary key: A column (or set of columns) whose values uniquely identify every row in a table
- Foreign key: One or more columns that can be used together to identify a single row in another table
DB의 테이블 구조, 관계 등을 formal language로 나타낸 것을 schema라고 한다. 일종의 데이터베이스 설계도며 보통 아래와 같이 도식화시켜 나타낸다. Schema를 ER diagrams라고도 한다. 그림을 그리는 방식도 여러가지가 있는데 Chen Notation, Crow’s Foot Notation, UML Class Diagram Notation 등이 있다.
RDBMS의 종류: MS SQL Server, MySQL, IBM DB2 Oracle, Apache Open Ofiice Base, Sybase ASE, SQLite, PostgreSQL
RDBMS에 대조되는 개념으로 transactional DB가 있다.
Structed Query Language
RDBMS와 대화하기 위한 언어다. 좀 더 일반적으로 sql 은 database와 users 간 interpreter 역할을 한다고 볼 수 있다. Data scientist는 data의 end-user로서 data retrieval 목적으로 sql을 사용한다. Schema를 생성, 수정하고 테이블 관리 및 데이터 CRUD 등 DB와 관련된 모든 작업을 위해 사용되는 언어다. DB마다 SQL 문법에 약간 차이가 있다. MySQL과 SQLite 간 차이가 그 예시다. 그러나 표준 SQL을 기반으로 하고 있기 때문에 SQL을 할 줄 안다고 말해도 다 알아듣는다. 마치 표준어와 사투리 정도의 차이인가..?
왜 굳이 DB랑 따로 얘기하기 위해 SQL이 나오냐 생각할 수 있는데, SQL이 나오고 매우 유용한 언어로 그 쓰임새를 인정받고 있기 때문에 지금까지 많이 쓰이는 것 같다. 대다수의 회사, 정부기관, 은행 등에서 많이 쓰이기 때문에 SQL을 알고 능숙하게 다루는 것이 필요하다.
- SQL은 세 가지로 나뉜다.
- Data Definition Language(DDL): CREATE, ALTER, DROP
- Data Manipulation Language(DML): INSERT, UPDATE, DELETE, SELECT
- Data Control Language(DCL): GRANT, BEGIN, COMMIT, ROLLBACK
- CRUD는 대부분의 컴퓨터 소프트웨어가 가지는 기본적인 데이터 처리 기능인 create, retrieve, update, delete를 묶어서 일컫는 말이다. 이 4개 조작 중 하나라도 불가한 소프트웨어는 불완전하다고 표현한다. 각 문자는 다음과 같이 표준 SQL문으로 대응시킬 수 있다.
| 이름 | 조작 | SQL |
|---|---|---|
| Create | 생성 | INSERT |
| Read(또는 Retrieve) | 읽기(또는 인출) | SELECT |
| Update | 갱신 | UPDATE |
| Delete(또는 Destroy) | 삭제(또는 파괴) | DELETE |
SQL query based on SQLite
- Create
CREATE TABLE Shoes
Id char(10) PRIMARY KEY,
Brand char(10) NOT NULL,
Type char(250) NOT NULL,
Color char(250) NOT NULL,
Price decimal(8,2)NOT NULL,
Desc Varchar(750)NULL
);
INSERT INTO Shoes
(Id, Brand, Type, Color, Price, Desc)
VALUES ('145333', 'Gucci', 'Slippers', 'Pink', '695.00', NULL);
CREATE TEMPORARY TABLE Sandals AS
(
SELECT *
FROM shoes
WHERE shou_type = 'sandals'
)
- Retrieve
SELECT col1, col2
FROM data;
Update
Delete
Filtering
SELECT colname
FROM table_name
WHERE colname operator value
operator 종류:

출처: https://www.coursera.org/learn/sql-for-data-science/lecture/ESCUo/basics-of-filtering-with-sql
또는
WHERE ~ IN (~,~,~)
WHERE ~ OR ~
WHERE ~ AND ~
WHERE NOT ~
또한 조건문에 괄호 붙여서 순서 정할 수 있다.
- Ordering
SELECT something
FROM database
ORDER BY colname
ORDER BY colname1, colname2
ORDER BY DESC colname
- Mutate
R의 dplyr 패키지의 mutate가 하는 것과 비슷해서 제목을 저렇게 적었다.
SELECT Id, col1, col2, col3, (col1-col2)/col3 AS col4
FROM database
SELECT AVG(col1) AS col1_avg,
COUNT(col2) AS col2_cnt,
COUNT(*) AS total_cnt,
COUNT(DISTINCT customerID),
MIN(col3) AS col3_min,
MAX(col4) AS col4_max,
SUM(col5) AS col5_sum
FROM database
- Grouping
SELECT ID, COUNT(*) AS col1
FROM database
GROUP BY ID
HAVING COUNT(*) >= 2;
- Wildcards
SQL의 정규표현식과 살짝 비슷한 개념이다. 정확한 정의는 special character used to match parts of a value다. 텍스트나 기호를 매칭시켜 호출할 수 있다. 그러나 가능하면 일반 operator 쓰는 것이 더 빠르다.
WHERE size LIKE '%Pizza%'
- Adding Comments
single line은 two dash
SELECT shoe_id
-- ,brand_id
,shoe_name
FROM Shoes
section은 /* */ 사용함
SELECT shoe_id
/*,brand_id
,shoe_name
*/
FROM Shoes
- subqueries : 쿼리 안에 쿼리가 있는 형태인데, 주로 2개 이상의 테이블을 한번에 다룰 때 유용하게 쓰임. 일종의 문법이며 filtering에서 자주 쓰임
SELECT customerID, companyName, Region
FROM Customers
WHERE customerID in (SELECT customerID
FROM Orders
WHERE Freight > 100)
위 코드는 모두 coursera의 SQL 강의에서 작성한 것이다.
SQL with R, Python
SQL이 RDBMS와 유저 간 interpreter로서 역할을 하는 것을 알고 어떻게 query를 작성할지 알았다. 그럼 데이터 분석가 입장에서 SQL을 어떻게 사용할 수 있다는 걸까? 일단 내가 생각한 방식은 다음과 같다.
- MySQL, SQLite 등을 다운받아 해당 프로그램 내에서 데이터 로드, 처리, 저장한 뒤 처리된 데이터를 Python, R에서 불러 분석
- Python, R와 SQL을 연결시켜 Python에서 SQL query를 작성
- 간단한 분석이라면 Oracle, MySQL 등만을 사용(?)
2번이 가장 그럴듯 해보인다.
NoSQL(Not Only SQL)
- 다음과 같은 정의가 있다. ‘A mechanism for storage and retrieval of unstructered data modeled by means other than tabular relations in relational databases.’